
Getty Images Plus
How AI speech recognition shows bias toward different accents
AI speech recognition systems often struggle to understand certain accents and dialects due to insufficient training data.

Have you ever tried to activate a voice assistant only to have it fail to understand you? It turns out that artificial intelligence and speech recognition systems have difficulty understanding some accents more than others.
People with specific accents might find automated customer service calls challenging. It can be a frustrating experience at best and can exclude entire demographics from a service or technology feature at worst. This failure in technology can have a negative effect on individuals and in the overall customer experience with a product.
A survey of 3,000 Americans based on age, gender and geography conducted by Guide2Fluency showed that the top five U.S. regional accents misunderstood by AI include the following:
- Southern.
- New York City.
- New Jersey.
- Texan.
- Boston.
Not only do each of these regions have a different way of pronouncing some words, each also comes with a slightly different dialect that might not be understood by AI systems.
Why AI needs to understand dialects and accents
While an accent is defined as a specific way of pronouncing words in a language, a dialect is a set of more broad linguistic concepts that includes differences in grammar, pronunciation, vocabulary and how the language is used. Accents and dialects are not something one can easily change, and they can be tied deeply to one's culture and community.
Businesses with speech recognition technology that can understand diverse accents and dialects might see an improved customer experience, a broader user base, and improved brand image and loyalty. Asking users to change how they speak for the system to understand them, however, should not be considered an option.
The inability of speech recognition systems to understand different accents and dialects can affect a large part of a product or service's user base and can lead to frustrating experiences. Services such as automated customer service platforms, court transcriptions or accessibility tools can all be negatively affected by this. And it's a simpler fix on the AI side than you might think.
How speech recognition software works
To understand why this problem exists and how to fix it, it is important to first know how speech recognition works.
Speech recognition software captures audio through a microphone input, then digitizes it into a format that can be processed by a computer. The audio is then broken down and analyzed using a variety of algorithms. The broken-down segments are compared against a database of language models and speech patterns to identify the most likely words or phrases being used.
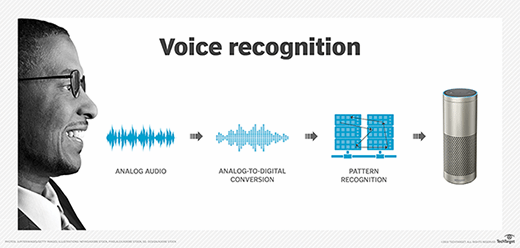
The algorithms used typically include machine learning and natural language processing. They can also include neural networks, natural language understanding (NLU), hidden Markov models or n-grams -- depending on the model.
These models "learn" using a large collection of data, and the accuracy and quality of the model depend on the accuracy and quality of the training data. The training data typically includes audio recordings and transcriptions. Each audio clip in the data set should be paired with an accurate transcription so that there is an exact representation of what was spoken.
Although these algorithms -- which are based on AI and machine learning -- help improve the accuracy of speech recognition, this is also where the issue of understanding accents and dialects is introduced.
How does AI understand accents?
Speech recognition systems can only recognize accents and dialects that they've been trained to understand. So the issue of understanding accents and dialects lies in whether the model was exposed to an accent during the training process.
For example, Guide2Fluency's survey indicated that the speech recognition system its participants used lacked a diverse enough training data set to accurately understand those accents.
A diverse training data set is one that is not limited to a specific group of people. Training data sets should include audio with a variety of accents, dialects, genders, ages and speaking styles. This provides the model an opportunity to learn different speaking patterns, accents or dialects, and to form clear links between different words and sounds.
Diverse NLU models also aid in understanding different dialects, as NLU can help in understanding regional terms and sentence structures. Voice recognition systems -- given enough training -- can even be used to understand multiple languages.
The challenges of training speech models with diverse accents
Common challenges in training speech models with more diverse accents and dialects include the following:
- Data collection cost. All the costs typically associated with training an AI or machine learning model -- such as data acquisition, computational resources and storage -- are increased when training a model that can understand different accents and dialects.
- Computational complexity. Training a machine learning model on a single dialect or accent takes a massive amount of data. Training a model on additional regional and non-native accents takes more computational power, processing and storage.
- Market and cost considerations. Technology companies -- especially smaller ones with less budget -- might also have to consider balancing the cost of developing a speech recognition model with the associated market demand.
- Bias. A model might be created using the dominant accent and dialect of an area, with developers unintentionally omitting different accents or dialects.
There are some ways around these challenges, however. For example, transfer learning is an approach that could enable an organization to start with a machine learning model that has already been pretrained on a specific dialect or accent. It can then train that model on more regional accents and dialects to cut down on the data training time.
Another method is to use more advanced AI models that actively train themselves through continuous learning or feedback loops. These models can learn accents by being corrected over time.
The role of accents and dialects in AI bias
AI and machine learning bias is a phenomenon that occurs when an AI or machine learning model produces results that are systemically prejudiced. This is typically due to insufficient data used to train the models, the design of the algorithms or the context in which the model is deployed.
One way this bias shows up in speech recognition systems is their failure to understand different accents and dialects. This is most likely due to the lack of sufficient training data, where the model is not exposed to a diverse enough set of training data -- either due to the monetary or resource cost, the data collection process, or lack of consideration by developers.
This leads to a significant performance gap where a speech recognition system might work perfectly for some people while working poorly -- if at all -- for others who have a different regional or non-native accent and dialect. This difference in user experience can result in frustration, less accessibility or even exclusion for those people whose speech varies from that on which the AI was trained.
A study called "Racial Disparities in Automated Speech Recognition" published in 2020 found that speech recognition systems developed by Amazon, Apple, Google, IBM and Microsoft all had higher error rates for Black speakers when compared with white speakers, for example. The issue was cited as the systems' failure to pick up on different phonetic pronunciations and accents.
This underscores the importance of having diverse data sets to train speech recognition systems as well as having a diverse team work on developing these systems.
Alexander Gillis is a technical writer for WhatIs. He holds a bachelor's degree in professional writing from Fitchburg State University.






