object code

What is object code?
Object code is machine-readable code that provides instructions to a target computing platform, as defined by its operating system and hardware architecture. Object code is written in binary language (0s and 1s) because this is the only language a computer can understand. The code is typically packaged in an executable format that can be loaded into the computer's memory in preparation for processing. The processor uses this data to execute operations the software defines.
Object code must conform to a processor's instruction set architecture (ISA). Common ISA examples are complex instruction set computer (CISC) and reduced instruction set computer (RISC). The ISA is part of the processor's microarchitecture, acting as an interface between the hardware and software. It also defines the set of commands the CPU can perform. Object code must be created specifically for the processor's architecture and ISA, no matter how it's generated.
Source code vs object code
Object code is often compared to source code; both play a critical role in software development. Source code is human-readable and much easier to work with than object code. For this reason, it is commonly used when first developing a software program. Developers write the code in plain text, often working in an integrated development environment, which makes it easier to manage the code and development process.
At some point in the development process, source code is translated to object code. To get to this point, developers must first create the text files that contain the source code. For this, they typically use a high-level programming language, such as C, C++, C#, Visual Basic, Java, Python. There are many other languages that make it much simpler to create, read and update code, which is extremely difficult with object code.
In some cases, high-level source code is converted to assembly code or bytecode before it's converted to object code. The assembly code must be specific to the target platform. Assembly code, whether created with a low-level or high-level language, must target the correct platform.
No matter where developers start, the software must end up as object code because processors do not understand source code. In this sense, source code and object code can be thought of as the before and after versions of a software program. Developers create plain text files in a specific programming language. These files are eventually converted to object code, which includes instructions that a processor can understand but are difficult for a human to read or modify.
How is object code generated?
The exact approach to getting source code to object code depends on the programming language and environment in which the software runs.
One common approach to generate object code from source code is to use a compiler, which is a special program that translates source code into object code, assembly code, bytecode or another programming language. When a compiler is used to generate object code, the code is then usually fed to a linker, a program that combines object files with other elements to produce executable code.
Some resources treat object code as a large category of code that includes bytecode and machine code, which itself includes the executable files and supporting libraries. Under this definition, object code refers to any code after it passes through the compiler.
Other resources treat object code and machine code as one in the same, using the terms interchangeably (and sometimes inconsistently), along with terms such as machine language and native code. To further complicate matters, there are some sources that make a clear distinction between object code and machine code, claiming that object code is converted to machine code at some point so it can be loaded into memory.
Despite these nuances, the point is that the source code must eventually be translated into object code before a computer can understand the software's instructions. In some cases, the source code might first be translated into assembly code, which is then converted into object code. Figure 1 shows this process. A compiler converts the source code into assembly code, and an assembler converts the assembly code into object code, which is then fed to a linker. An assembler is a software application whose primary purpose is to translate assembly code into object code for a specific target platform.
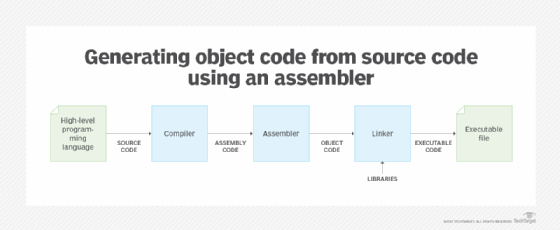
An assembler can also be used when developers start with an assembly language rather than a high-level language. This scenario does not require a compiler. All that's needed is the assembler to generate the object code, as shown in Figure 2.
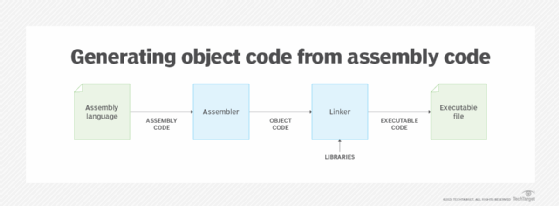
In the previous examples, the compiler- or assembler-generated object code that was specific to the target platform. However, some programming languages, such as Java and C#, instead use a compiler to translate the source code to bytecode or another type of intermediary code. This code is then converted by an interpreter running on each platform. It is the individual interpreter that generates the object code for that platform, as shown in Figure 3.
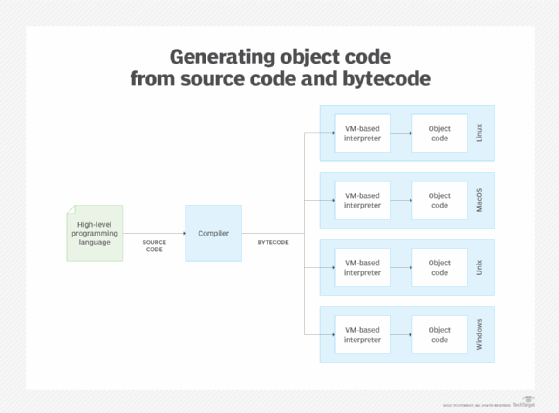
The use of intermediary code, such as bytecode, eliminates the need to recompile the source code for each targeted platform. Instead the same intermediary code can be used on each platform, where it is translated into object code for that environment.
See what low-code/no-code and pro-code mean for providers and learn the differences between interpreted vs. compiled programming languages. Explore in-demand programming languages devs should get to know and check out a breakdown of object-oriented programming concepts.