
What is dimensionality reduction?

Dimensionality reduction is a process and technique to reduce the number of dimensions -- or features -- in a data set. The goal of dimensionality reduction is to decrease the data set's complexity by reducing the number of features while keeping the most important properties of the original data.
Data features refer to the different variables and attributes typically found in data sets. The more features a data set has, the more complex it becomes. High-dimensional data, therefore, can lead to problems such as overfitting or a decrease in performance. Reducing the data's complexity through dimensionality reduction processes helps to simplify the data.
Dimensionality reduction is advantageous to artificial intelligence (AI) and machine learning (ML) developers or other data professionals who work with massive data sets, performing data visualization and analyzing complex data. It also aids in the process of data compression by helping the data take up less storage space.
Techniques such as feature selection and feature extraction are used to complete dimensionality reduction. Along with this, each technique uses several methods that simplify the modeling of complex problems, eliminate redundancy and reduce the possibility of the model overfitting.
Why is dimensionality reduction important for machine learning?
ML requires large data sets to properly train and operate. There's a challenge typically associated with ML called the curse of dimensionality. The idea behind this curse is that as the number of features in a data set grows, the ML model becomes more complex and begins to struggle to find meaningful patterns. This can lead to increased computational complexity and overfitting where a model works fine on training data but performs poorly with new data.
Dimensionality reduction is a useful way to prevent overfitting and to solve classification and regression problems. This process is also useful for preserving the most relevant information while reducing the number of features in a data set. Dimensionality reduction removes irrelevant features from the data, as irrelevant data can decrease the accuracy of machine learning algorithms.
What are different techniques for dimensionality reduction?
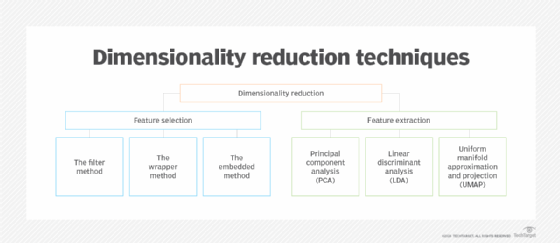
There are two common dimensionality reduction techniques, as follows:
- In feature selection, small subsets of the most relevant features are chosen from a larger set of dimensional data to represent a model by filtering, wrapping or embedding. The goal is to reduce the data set's dimensionality while keeping its most important features.
- Feature extraction combines and transforms the data set's original features to create new features. The goal is to create a lower-dimensional data set that still has the data set's properties.
Feature selection uses different methods, including the following:
- The filter method. This filters a data set into a subset that only has the most relevant features of the original data set.
- The wrapper method. This technique feeds features into an ML model to evaluate if a feature should be removed or added.
- The embedded method. This evaluates the performance of each feature by checking training iterations of the ML model.
Feature extraction uses the following methods:
- Principal component analysis. This statistical process identifies smaller units of features from larger data sets. These small units are called principal components.
- Linear discriminant analysis. This method finds the features that best separate different classes of data.
- Uniform manifold approximation and projection (UMAP). This nonlinear dimensionality reduction method maps high-dimensional data to lower-dimensional spaces. UMAP is similar to T-distributed stochastic neighbor embedding (t-SNE), but it offers more scalability while preserving local and global data structures.
- Autoencoders. Autoencoders are neural networks used for feature extraction. They compress data into a simpler form, then reconstruct the original data.
Other methods used in dimensionality reduction include the following:
- Factor analysis.
- High correlation filter.
- Generalized discriminant analysis.
- T-SNE.
Benefits and challenges of dimensionality reduction
Dimensionality reduction offers the following benefits:
- Improved performance. Dimensionality reduction reduces the complexity of data, which reduces irrelevant data and improves performance.
- Increases visualization. High-dimensional data is more difficult to visualize when compared to lower or simplified dimensional data.
- Prevents overfitting. Dimensionality reduction helps prevent overfitting in ML models.
- Reduced storage space. It reduces storage space as the process eliminates irrelevant data.
- Feature extraction. Dimensionality reduction aids in extracting relevant features from high-dimensional data.
- Data compression. It compresses data, which improves its storage and processing efficiency.
The process does come with downsides, however, such as the following:
- Data loss. Dimensionality reduction should ideally have no data loss, as data can be recovered. However, the process might still result in some data loss, which can affect how training algorithms work.
- Interpretability. It might be difficult to understand the relationships between the original features and the reduced dimensions.
- Computational complexity. Some reduction methods might be more computationally intensive than others.
- Outliers. If not detected, data outliers can interfere with the dimensionality reduction process, leading to biased data representations.
- Linear correlations. Dimensionality reduction can sometimes find more direct, linear correlations between variables. This could be a downside if it ignores nonlinear correlations or if it reduces the model's predictiveness.
Future of dimensionality reduction in ML
As AI and ML processes become more widespread, so does the practice of dimensionality reduction. Some current trends seen in the space include the following:
- Integration with deep learning. Some dimensionality reduction techniques, like autoencoders, might see further integration with deep learning and neural network models.
- UMAP adoption. The use of UMAP is also currently growing, particularly due to its advantages over t-SNE.
- Hybrid models. The adoption of hybrid models that combine dimensionality reduction and feature selection might also become more common. This combination further helps to focus on keeping the most informative features in a data set.
To improve the performance of an ML model, dimensionality reduction can also be used as a data preparation step. Learn more data preparation steps for ML.