non-uniform memory access (NUMA)

What is non-uniform memory access (NUMA)?
Non-uniform memory access, or NUMA, is a method of configuring a cluster of microprocessors in a multiprocessing system so they can share memory locally. The idea is to improve the system's performance and allow it to expand as processing needs evolve.
In a NUMA setup, the individual processors in a computing system share local memory and can work together. Data can flow smoothly and quickly since it goes through intermediate memory instead of a main bus.
NUMA can be thought of as a microprocessor cluster in a box. The cluster typically consists of four microprocessors interconnected on a local bus to a shared memory on a single motherboard. The bus may be a peripheral component interconnect bus, the shared memory is called an L3 cache and the motherboard is often referred to as a card.
This unit can be added to similar units to form a symmetric multiprocessing system (SMP) that can contain 16 00 256 microprocessors with a common SMP bus interconnecting the clusters. In an SMP system, all the individual processor memories look like a single memory to an application program.
How non-uniform memory access works
When a processor looks for data at a certain memory address, it first looks in the L1 cache on the microprocessor. Then it moves to the larger L2 cache chip and finally to a third level of cache (L3). The NUMA configuration provides this third level. If the processor still cannot find the data, it will look in the remote memory located near the other microprocessors.
Each of these clusters is viewed by NUMA as a node in the interconnection network. NUMA maintains a hierarchical view of the data on all nodes. Data is moved on the bus between the clusters using a scalable coherent interface. SCI coordinates cache coherence (consistency) across the nodes of the multiple clusters in the NUMA architecture.
NUMA and symmetric multiprocessing
NUMA is commonly used in a symmetric multiprocessing system. An SMP system is a tightly coupled, share-everything system in which multiple processors work under a single operating system and access each other's memory over a common bus or interconnect path. These microprocessors work on a single motherboard connected by a bus.
One limitation of SMP is that as microprocessors are added, it overloads the shared bus or data path, creating a Performance bottleneck. NUMA adds an intermediate level of memory that is shared among a few microprocessors so that all accessed data doesn't travel on the main bus. This helps address performance bottleneck issues.
SMP and NUMA systems are typically used in data mining applications and decision support systems. In these types of applications, processing can be parceled out to multiple processors that collectively work on a common database.
NUMA node architecture
The NUMA architecture is common in multiprocessing systems. These systems include multiple hardware resources including memory, input/output devices, chipset, networking devices and storage devices (in addition to processors). Each collection of resources is a node. Multiple nodes are linked via a high-speed interconnect or bus.
Every NUMA system contains a coherent global memory and I/O address space that can be accessed by all processors in the system. The other components can vary, although at least one node must have memory, one must have I/O resources, and one must have processors.
In this type of memory architecture, a processor is assigned a specific local memory for its own use, and this memory is placed close to the processor. The signal paths are shorter, which is why these processors can access local memory faster than non-local memory. Also, since there is no sharing of non-local memory, there is an appreciable drop in delays (latency) when multiple access requests come in for the same memory location.
Advantages and disadvantages of NUMA
One of the biggest advantages of NUMA is the fast movement of data and lower latency in the multiprocessing system. Additionally, NUMA reduces data replication and simplifies programming. And the parallel computers in a NUMA architecture are highly scalable and responsive to data allocation in local memories.
One disadvantage of NUMA is that it can be expensive. And the lack of programming standards for larger configurations can make implementation challenging.
Difference between NUMA and UMA
There are three shared-memory models in multiprocessor systems.
- Uniform memory access (UMA)
- Non-uniform memory access (NUMA)
- Cache-only memory access/architecture (COMA)
Figure 1 shows the differences between UMA and NUMA.
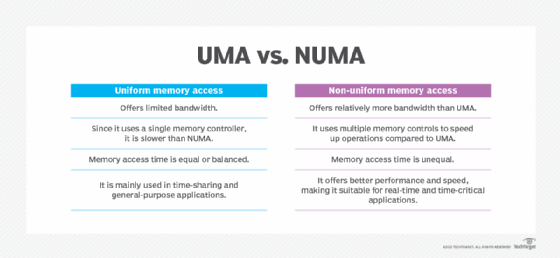
Like UMA and NUMA, COMA is also a shared-memory model used in multiprocessors. In a COMA machine, multiple processing nodes are connected by an interconnection network. Each node includes a processor and cache and is allocated as part of the global shared memory. The local memory (typically DRAM) at each node is used as the cache. This feature differentiates COMA from NUMA in which the local memory is used as the main memory.
COMA generally enables more efficient use of memory resources. The drawback is that it also makes it harder to find a particular piece of data since there is no home node in COMA (unlike NUMA). Moreover, it can be challenging to address memory shortage problems once the local memory fills up.
See also: vNUMA (virtual NUMA), IT Acronyms at your fingertips