failover cluster
What is a failover cluster?
In computing, a failover cluster refers to a group of independent servers that work together to maintain high availability of applications and services. If one of the servers fails, another node in the cluster can take over its workload with little or no downtime. This process is known as failover.
In a failover cluster, the clustered servers can collectively improve the availability and scalability of applications and services. The servers work together to provide either continuous availability or at least high availability (HA) through the failover process. Failover clusters can comprise either physical servers or virtual machines (VMs).
Each server is called a node and is connected to other servers in the cluster by physical cables and software. A failover cluster consists of at least two nodes to transfer data, as well as software to process the data through the cables. In addition, a cluster uses one or more technologies for load balancing, storage, parallel processing and other functions.
The applications and services in a failover cluster are sometimes known as clustered roles. The cluster keeps these roles operational if one server fails. At the same time, each role is proactively monitored to ensure that it is working properly. If it's not, it might be restarted or the role moved to another node.
The need for failover clusters
Server failure can lead to application downtime, which can result in operational disruptions for users. By providing continuous availability or high availability, failover clusters enable users to keep using the applications and services they need without experiencing outages, even if a server fails. There might be a brief service interruption with high-availability clusters during the failover process. However, the system usually recovers quickly with little or no data loss and minimum downtime.
Failover clusters play a vital role to ensure the ongoing availability of mission-critical applications and systems such as online transaction processing (OLTP) systems that demand very high -- near 100% -- availability. Database replication and disaster recovery (DR) also require failover clusters. These clusters provide geographic replication so if a server in one location goes down, data will still be available on failover servers at other sites.
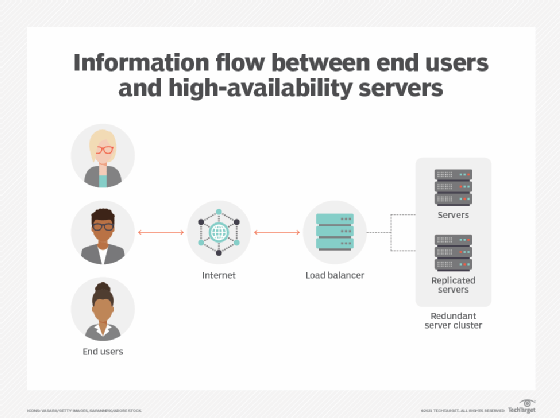
How failover clusters work
In a high-availability failover cluster, groups of independent servers share data and resources, including storage. At any time, a least one node is active and at least one is passive. These clusters include a monitoring connection that allows each server to check the health of the other servers. In a two-node cluster (the simplest possible configuration), if a node fails the other node will recognize the failure via the monitoring connection and configure itself as the active node. Larger configurations usually use dedicated servers that determine if any nodes are failing and then direct another node to assume the load and participate in the failover process.
In high-availability failover clusters using VMs, the VMs are pooled into a cluster along with the physical servers they reside on. If there is a failure, the VMs on the failed host will be restarted on alternate hosts.
In a continuous-availability failover cluster -- also known as a fault-tolerant cluster -- multiple systems share one copy of a computer's operating system (OS). Thus, the commands issued by one system are simultaneously executed on the other systems as well. The cluster requires a continuously available and near-exact copy of a machine running the service (physical or virtual). This redundancy model is known as 2N. It can automatically detect failures of hard drives, power supplies, network components and CPUs. When the cluster identifies a failure point, a backup component -- or procedure -- takes its place instantaneously without service interruption.
High-availability failover clusters vs. continuous-availability failover clusters
High-availability clusters attempt 99.999% availability (five 9s availability). These clusters are generally adequate for most applications and services. However, services or applications that require 100% availability, continuous-availability failover clusters are required. These include mission-critical applications such as electronic stock trading, ATM banking, order management, employee time clock systems and reservation systems. Many applications in manufacturing, logistics and e-commerce also require continuous-availability failover clusters.

Types of failover clusters
Failover clustering is a popular feature in Windows Server and Azure Stack HCI. With those OSes, organizations can create highly available or continuously available file share storage for applications such as Microsoft SQL Server and Hyper-V VMs. Another approach is to create highly available clustered roles on physical servers or VMs that are installed on servers running Hyper-V.
Failover clusters in Windows provide Cluster Shared Volume (CSV) functionality. CSV provides a general-purpose, clustered file system that's layered above NTFS or ReFS. Multiple clustered nodes can read from or write to the same LUN (part of a drive or collection of drives) that is provisioned as an NTFS volume. CSVs provide a consistent distributed namespace that can be used by clustered roles to access shared storage from all nodes and simplify the management of a large number of LUNs in a failover cluster.
Failover clusters are also available in VMware, SQL Server and Red Hat Enterprise Linux. VMware offers many virtualization tools for VM failover clusters. For example, vSphere vMotion replicates a VMware VM and its network to provide continuous availability. VMware vSphere pools VMs and their hosts into a cluster for automatic failover and high availability.
SQL Server 2017 comes with a high-availability failover clustering solution called Always On that registers SQL Server components as cluster resources and enables automatic failover to a different node if one node fails. Red Hat Enterprise Linux also provides a failover cluster mechanism, which allows users to create high-availability failover clusters with the Red Hat Global File System (GFS/GFS2).
What is cluster affinity?
affinity refers to a rule a user would set up to establish a relationship between two or more roles to keep them together. These roles could be VMs, resource groups or other entities. Anti-affinity is also a rule, albeit one that is used to keep the specified roles apart.
These rules are required because a failover cluster can hold many roles that can move and run between nodes. However, when certain roles should not run on the same node, they must be kept apart. Affinity and anti-affinity rules help avoid performance impact issues, which might happen if roles running on the same node use more resources or memory than they should.
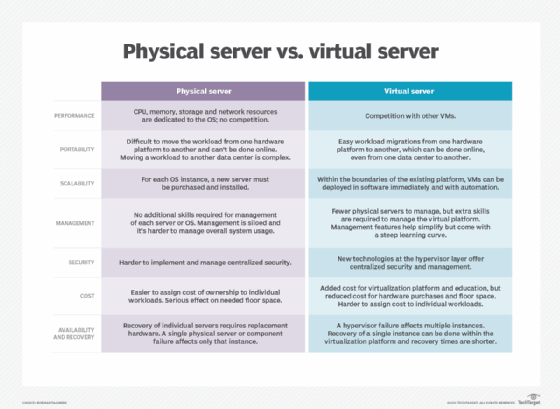
Learn more about the differences between virtual servers and physical servers.





