Could the AI era open a new frontier for object storage?
Object storage has seen a steady progression over the years. Explore this evolution and several products that seek to capitalize on its performance, specifically for AI.
Intelligence and advice powered by decades of global expertise and comprehensive coverage of the tech markets.
Published: 09 Dec 2024
The criticality of building the right data and storage architecture for the modern era of AI, advanced analytics and data lakes continues to drive innovation in the storage ecosystem. In recent months, we've seen a substantial number of announcements in the object storage realm as market players seek to take advantage.
What's driving this trend, and what might it tell us about the future of object storage adoption in the enterprise? Object storage isn't new, and it is a great example of how a fundamental enabling technology can evolve over time and be applied to a different set of uses.
How it started
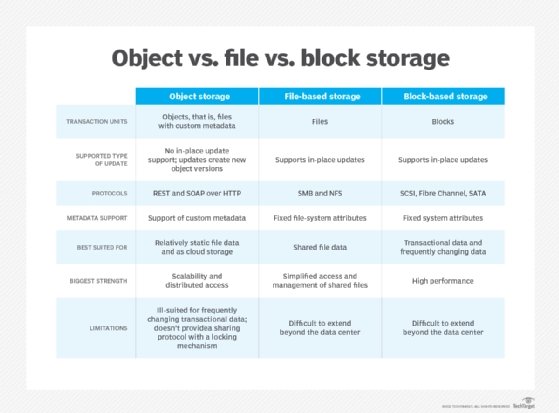
Object storage was first productized in the early 2000s in the aftermath of the Enron financial scandal, as tighter financial regulations such as the Sarbanes-Oxley Act required organizations to retain digital information -- email and documents -- for set time periods. IT needed a cost-effective way to centrally store large amounts of data in an easily retrievable format; compliance-oriented storage, such as EMC's Centera "content addressable storage" system, emerged to fill the gap.
Rather than storing data as a file to be organized into a file system, data was stored as an object in a much flatter hierarchy, which made the system more scalable. It also enabled users to store data in an immutable manner, with a much richer set of metadata than in a file system. Regulated industries, particularly the financial sector, widely adopt such platforms.
The next wave was critical in turning object storage from a niche use into the underpinnings of the cloud as we know it today. It emerged because of the digital content explosion in the wake of mass smartphone adoption, together with the rise of social media and the public cloud model -- specifically AWS -- in the mid-to-late 2000s.
The launch of Amazon S3 was instrumental, offering a new way to create a massively scalable, distributed and simple storage architecture, consumed as a service and with a rich API to which anyone could connect. It has now become a de facto standard, opening the gate to a legion of new data-centric cloud-based applications that could easily take advantage of S3.
This period also saw the emergence of multiple object storage technology specialists. Content-heavy organizations could cost-effectively manage their exploding data volumes on-premises, and other service providers could look to offer S3-like storage services. Most of these specialists ended up getting acquired by the larger storage and infrastructure suppliers.
How it's going
Over the intervening years, object storage has evolved along two distinct trajectories. In the public cloud, its use has gone stratospheric, as S3 grew to underpin a new breed of web-scale apps and big data lakes. The number of S3 customers stretched into the millions, and it now stores some 450 trillion objects. Furthermore, this growth looks set to continue as Amazon's investment in innovation here continues.
By contrast, enterprise adoption of on-premises object storage platforms has been more modest. Research from Informa TechTarget's Enterprise Strategy Group suggested it's in use in some capacity by around a third of organizations. Though usage has certainly increased -- especially for those who have very large unstructured data volumes, or who can't or won't use public cloud -- object storage is still the exception in the regular enterprise. Mainstream applications, especially those requiring substantial levels of storage performance, still run on SAN, NAS or unified storage.
In the enterprise, object storage is largely restricted to the necessary but unglamorous role of supporting capacity-centric uses that prioritize durability and cost-effective scale over performance. It can serve as a repository for backups, archives, large-scale data lakes and so on. Additionally, as some organizations begin to deploy AI at scale with large volumes of unstructured data, they are turning to high-performance file storage, such as parallel file systems. Here, object storage might be in the mix as a lower, capacity-oriented tier, but so far, it hasn't been front and center.
However, on-premises object storage is undergoing a new phase of innovation that could see its role evolve once more. Proponents believe that by boosting performance, object storage could play a much larger role in the enterprise overall as a more scalable, easier-to-use and more cost-effective alternative to traditional storage approaches. Here, it could even directly support high-performance AI workloads, potentially providing an alternative to file system-based approaches.
Some recent object storage products
For example, HPE recently unveiled its first homegrown object storage platform. HPE built its Alletra Storage MP X10000 on a disaggregated, all-flash architecture. Aimed at "high-speed data lakes" as well as more traditional uses, such as backup and archiving, HPE is drawing attention to the system's performance, which it claims offers up to six times that of competitive offerings.
Additionally, HPE is collaborating with Nvidia to enable a direct path for direct memory access between GPU memory, system memory and the X10000. Such a capability, which HPE plans to deliver next summer, would further increase the system's bandwidth as well as reduce latency and improve GPU utilization, making it more suitable as a storage layer for high-performance AI applications.
HPE is not alone in such an endeavor. In an industry first, object storage specialist Cloudian integrated its HyperStore product with Nvidia Magnum IO GPUDirect Storage technology, enabling direct communication between Nvidia GPUs and Cloudian storage nodes. In bypassing the CPU in this way, Cloudian says it can offer high levels of parallel throughput and scalability for AI workloads such as training and inferencing, without incurring the complexity of a file system or having to migrate data between tiers.
These and other innovations highlight that this is a good time for many organizations to take a fresh look at where object storage could play, especially if they are looking to modernize their overall data and storage architecture for their large-scale data lakes, analytics or AI initiatives.
Another object storage specialist, Scality, recently unveiled an "extreme performance" variant of its Ring software optimized for AI workloads such as model training, featuring microsecond response time latencies for small object data. Running on AMD Epyc-based all-flash NVMe storage servers, the system can be configured alongside regular Ring storage to offer end-to-end storage management across the AI data pipeline.
Hitachi Vantara's latest object storage product, VSP One Object, is aimed at a variety of enterprise uses, spanning S3-native analytics, backup and even high-performance AI/ML data lake workloads.
These and other innovations highlight that this is a good time for many organizations to take a fresh look at where object storage could play, especially if they are looking to modernize their overall data and storage architecture for their large-scale data lakes, analytics or AI initiatives.
As always, we would recommend that IT decision-makers evaluate a range of products that consider their own specific requirements. As the market evolves, the role of object storage is changing with it, providing new alternatives for organizations to consider.
Simon Robinson is principal analyst covering infrastructure at Informa TechTarget's Enterprise Strategy Group.
Enterprise Strategy Group is a division of TechTarget. Its analysts have business relationships with technology vendors.