Storage

stock.adobe.com
Optimal architectures for intelligent storage systems
Explore the best, most optimal architectures for intelligent storage and how these systems improve storage performance/utilization to help get more bang out of your data set buck.

Brute force has been the critical lever to achieving advances in storage technology for much of its history. Making storage devices bigger, faster and denser has worked well and will no doubt continue to contribute to improved storage systems, but it is no longer the best way to improve storage costs and performance. Instead, machine learning and analytics in the form of intelligent storage systems now drive the most important advances in storage technology.
What is an intelligent storage system?
Pre-intelligent storage systems optimize for low-level operations of a storage device, such as reading from an SSD or sending a packet to a network interface. Intelligent storage systems operate at higher levels of abstractions by using data about device operations to improve performance within a device and observing data utilization patterns to optimize system-level operations.
Intelligence is incorporated into storage systems at three distinct levels: device-level optimizations, tiered storage and data lifecycle management, and data accessibility support. In the case of device-level optimizations, machine learning algorithms identify categories of data with similar access patterns. If a machine learning model predicts a set of blocks will likely be read in the future, those blocks can be copied into a cache prior to the time they are read.
This reduces read latency, which is particularly important for use cases like training machine learning models that require not only large volumes of data, but data delivered fast enough to keep up with the processing speed of GPUs and other accelerators.
Tiered storage and data lifecycle management support focus on larger volumes of data than device-level optimizations. While the latter targets the optimal placement of soon-to-be-used data and watches for potential failures, the former is designed to optimize the placement of data for long-term storage. For example, recently generated time-series data is more likely to be queried than older time-series data. Tiered storage intelligence can detect different access patterns to place likely-to-be-accessed data on low-latency but higher-cost storage, while migrating older data to a less expensive storage platform.
As the volume and variety of data grow, it becomes increasingly difficult to find specific data. Of course, searching for a specific file by name or restoring a set of archive files created at a particular time are straightforward operations. But not all data access requirements are so simple. For example, engineers may find intelligent machine learning models performing poorly in production because they have not been trained on a sufficiently broad training set.
They would likely want to search storage systems looking for data with specific characteristics. Intelligent indexing, tagging and retrieval are essential to implementing this use case.
Features of intelligent storage systems
Intelligence evolved in a variety of ways in living creatures, and a similar diversity of approaches is found in intelligent storage systems. Some of the most common features across intelligent storage systems are the use of predictive analytics, distributed storage and processing, optimal data placement and enhanced security.
Some intelligent systems use predictive analytic techniques. These are essentially statistical and machine learning methods that detect patterns in device operations data and use those patterns to predict how data stored on the device will be accessed.
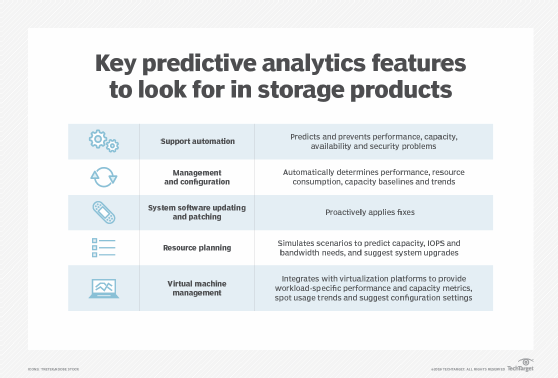
For device-level optimizations, this kind of analysis depends on I/O trace logs, which are records of each operation on a device. Statistical techniques do not need to understand the meaning of the data to the user -- it makes no difference if a sales transaction or a sensor on a vehicle generated the data. What matters is the characteristics of the data, such as where it is located and when it was written. Clustering algorithms are typically used for this kind of predictive analytics.
Intelligent storage systems can span multiple devices. An IoT sensor can send data to an edge device for storage and further analysis. The edge device can perform a preliminary analysis of the data to determine which data should be stored locally and which should be sent to a centralized analysis system. For instance, an anomalous set of measurements from a sensor may indicate a problem that needs to be addressed immediately. That data is then sent directly to the next stage of the ingestion process, while other data is simply stored and sent in batches at a later time.
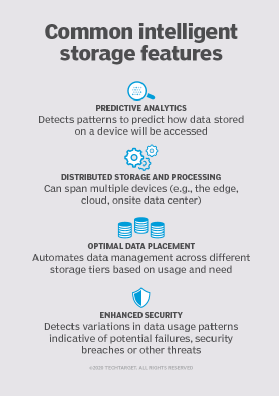
Intelligent systems can also manage data across different storage tiers. Recent time-series data is much more likely to be queried than older data, so it should be kept in low-latency storage while older data can be moved to lower-tier storage that may have longer latency but also costs less. This kind of data lifecycle management needs to be automated, as the volume and types of data that require this sort of management are not amenable to manual management. At best, humans may define high-level lifecycle management policies, but we will depend on intelligent storage systems to implement those policies across a range of data sets and use cases.
Enhanced security is another feature of intelligent storage. Applications and services will often have predictable patterns of CPU utilization, IOPS and other commonly monitored metrics. Variations from baseline operations can indicate a potential security problem but are not uncommon, so users will need to tune intelligent storage systems to detect variations that are indicative of a potential failure, security breach or other threat to operations. For example, machine learning engineers can collect performance data generated during controlled ransomware attacks to build models that can predict when an attack has started.
These features -- as described -- are task-specific, such as optimizing data placement. But, in practice, organizations implement them across a range of infrastructure components. For this reason, it is important to understand the overall architecture of intelligent storage systems.
The architecture of intelligent storage systems
Storage systems, including those of the intelligent variety, are part of a larger infrastructure that includes servers, networks and the storage systems themselves. Intelligent storage systems have four main components: a front end, a cache, a back end and a persistent store, such as a disk or SSD.

The primary role of the front end is to communicate with the storage system network. Front ends are made up of ports and controllers. Front-end ports enable host servers to connect to the storage system. Ports are designed to support transport protocols, such as SCSI and Fibre Channel. Front-end controllers are responsible for routing data to and from the cache. They are also responsible for optimizing I/O operations, which is typically done using command queueing algorithms that optimize the order in which I/O commands are executed.
Cache is low-latency memory used to reduce the time required to perform I/O operations, at least from the perspective of the application or service using the storage system. Caches store both data and information about the location of data in the cache and on disk.
Different strategies are used to manage data in a cache depending on what aspect of I/O operations should be optimized. With a write-back cache, for example, data is written to the cache and an acknowledgment is sent to the application. After the acknowledgment is sent, the data is written to disk. This minimizes the time the application waits for an acknowledgment, but at the risk of losing data if the cache should fail before writing the data to disk. Under the write-through strategy, data is written to the cache and immediately written to disk. This reduces the risk of data loss, but at the expense of longer latencies.

The back end is the interface between the cache and persistent storage, such as HDDs or SSDs. Like the front end, back ends consist of ports and controllers. Disks are connected to ports, and controllers manage the read and write operations to the disk. Intelligence in the back end includes error detection and correction.
While intelligence is important for optimizing operations within a storage system, to globally optimize storage and compute operations one needs to consider storage in the broader context of the full range of infrastructure that is in place. Today, that includes both on-premises infrastructure and cloud infrastructure.
Intelligent storage in hybrid cloud infrastructure
Potentially the best use of intelligence with storage management is when it is applied to optimize for workloads with applications and across hybrid cloud infrastructure.
Applications depend heavily on databases to manage structured data. Data-aware devices can use data about application-level operations to improve the storage performance of those databases. For example, a data-aware device can use data generated by a database management system to predict which data will be needed in the future. But applications and databases are rarely used in isolation. Instead, they are often parts of larger workflows.
The top level of storage intelligence is the ability to monitor workloads and optimize storage across multiple storage devices by using information collected across compute, networking and storage devices. This level of intelligence can help control cloud storage costs, which are often difficult to manage and too often lead to unexpected charges.
Improving storage performance and cost-effectiveness is no longer a matter of improving hardware. The most important advances are now being driven by intelligent software that spans low-level I/O operations on a single device all the way to monitoring workloads and optimizing data placement across hybrid cloud infrastructure. How intelligent is your storage infrastructure?

























