Computational and edge storage are changing the way we manage data at the network edge. Understanding the terminology around this technology can help clarify how it works.
As more applications generate massive amounts of data -- think IoT, AI, analytics -- the time taken to transfer, analyze and process that data is becoming a significant factor, slowing storage networks and systems. Computational storage is a way to update storage architectures and strip out latency, making the storage-compute process more efficient.
This emerging technology provides a new generation of devices that pairs SSDs with compute capabilities, bringing the compute closer to where all that overwhelming data originates. Much of this data isn't vital to the functioning of the business or needed with any urgency. With compute capabilities closer to the sources of that data, it can be preprocessed and sorted, so only the valuable data is sent over the network for further analysis or processing.
As Salil Raje, executive vice president and general manager of Xilinx's Data Center Group, said in a presentation at 2019 Flash Memory Summit, with computational storage, "you work on the data in the inner loop of the SSD, improving latency and performance for all the lower-level functions so the high-level functions can be done in the CPUs." The CPUs are freed up to handle the most important data.
The bottom line: This storage technology facilitates parallel computing, reduces network traffic and mitigates other constraints on compute, I/O, memory and storage. And it's coming to enterprise storage systems soon.
What follows is the computational storage terminology you'll need to know to understand computational storage and how it works before it becomes part of your work life.
Computational storage array
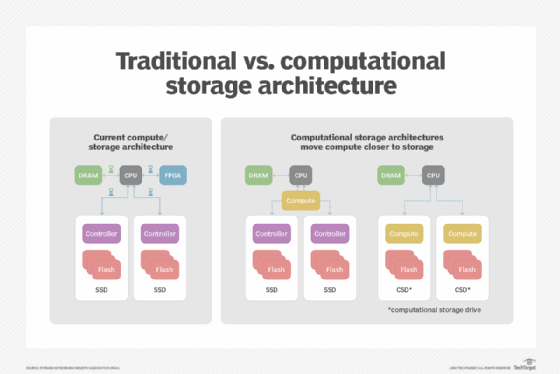
The Storage Networking Industry Association (SNIA) defines a computational storage array (CSA) as a device that combines computational storage devices, such as computational storage drives (CSDs) and computational storage processors (CSPs), with other optional storage devices and control software. In these arrays, the field programmable gate array (FPGA) acts as an accelerator, sitting in between the CPU and the SSD arrays. These arrays can use any vendors' SSD, and the accelerators and SSDs can scale independently. Bandwidth can be optimized between the accelerator and the SSDs.
Computational storage drive
A CSD is a device that has an FPGA or an application-specific integrated circuit (ASIC) embedded in an SSD to act as an accelerator. CSDs provide compute services and persistent data storage, such as NAND flash. The number of FPGAs or ASICs in a CSD can scale with the number of SSDs; as capacity is added, accelerators are also added. There is a dedicated link between the SSD and accelerator, which enables the optimization of bandwidth between the accelerator and flash storage. This approach provides much higher bandwidth than is traditionally available to SSDs. CSDs can be customized for specific workloads.
A CSP provides compute services to a storage system but doesn't provide persistent data storage. In a CSP, the accelerator and storage are on the same PCIe subsystem. The drive used as the accelerator plugs into the standard SSD slot and communicates with the SSDs over the PCIe subsystem using PCIe peer-to-peer transfers. This setup also provides high bandwidth. CSPs use vendor-independent SSDs.
Computational storage service
A computational storage service (CSS) refers to a compute task or service that a CSD, CSP or CSA provides. According to SNIA, a CSS can be a fixed storage service that provides a specific function, such as compression, RAID, erasure coding or encryption. A CSS can also be programed to provide multiple services, such as an OS image, a container, a Berkeley packet filter or an FPGA bitstream.
Edge computing
Computing at the edge involves distributed technology that makes it possible to process data close to where it originates and is collected at the network periphery. Mobile devices were the original driver behind edge computing's development; the proliferation of IoT sensors and devices has made it an even more critical element of IT infrastructure.
Edge computing has a variety of architectures. Time-sensitive data at the edge can be processed where the data originates, using an intelligent device. Or data can be sent to a nearby server for initial processing. With the massive amounts of data generated by IoT devices, it makes sense to use edge computing and computational storage to do initial processing at the edge and send only the most valuable data to the central data center. This approach conserves network resources and reduces response times.
Computational storage facilitates parallel computing, reduces network traffic and mitigates other constraints on compute, I/O, memory and storage. And it's coming to enterprise storage systems soon.
Edge device
An edge device is any piece of hardware that controls data flow at the network periphery or at the point where two networks meet. These devices usually serve as network entry and exit points, and they provide functions such as transmission, routing, processing, monitoring, filtering and storage. Examples of edge devices include edge routers, routing switches, firewalls, as well as IoT sensors, actuators and gateways.
Edge storage
Storage at the edge involves devices, such as CSDs, used to capture and store data at the network's edge and close to the originating source. Early examples of edge storage were storage devices in remote offices and DAS for laptops used in the field. Automating backups was the primary concern of early edge storage administrators.
Today, edge storage is all about what to do with all the data coming from IoT devices, how to deal with limited connectivity to some IoT devices and where to put the raw data that must be archived. As the volume of data generated from IoT devices and other applications explodes, organizations use computational storage methodologies and tools to sort data close to where it originates and send it to where it makes the most sense for next-step processing or storage.
Hyperscale computing
Hyperscale computing is an approach used in data centers that handle massive amounts of data and have changing demand for IT resources. Distributed, flexible infrastructure is used to quickly respond to an increase in demand for computing resources without adding latency or requiring additional space and power resources. Hyperscale computing and computational storage are connected, because hyperscale computing requires the ability to scale storage independently from compute. This storage-compute independence provides the flexibility hyperscale data centers need to quickly respond to changing data storage demands.
Multicore processors
Computational storage devices take the unique approach of using multicore processors, which can index data as it enters a storage device. Multicore processors can screen for specific entries, an approach that can be helpful with AI and other more advanced applications.
Real-time data analytics
As more data is collected at the network edge from IoT sensors and devices, the interface between the storage controller and the storage bus has become a chokepoint. Computational storage solves this problem. With compute capabilities placed directly on the storage device, data can be processed or analyzed where it resides in real time and only a subset is moved to the host.
SNIA Computational Storage Technical Working Group
SNIA established the Computational Storage Technical Working Group in November 2018 to facilitate the use of this new technology in application environments. The working group was charged with creating standards to enable the interoperability of these new devices and defining interface standards and protocols for system deployment, provisioning, management and security. As of December 2019, the group released a draft of its Computational Storage Architecture and Programming Model for public comment. SNIA also has a Computational Storage Special Interest Group that highlights the technical working group's work.