5 predictive storage analytics features you'll want to watch for
Predictive storage analytics tools are becoming standard equipment in the enterprise. Get to know the features you'll need, how they work and the benefits they provide.
We're all familiar with the power, convenience and borderline creepy accuracy of predictive data analytics. Whether it's looking for something new to watch on Netflix, browsing items related to an item bought last week on Amazon or cursing our phone's autocomplete misfire, predictive analytics is increasingly used to automate routine tasks, filter information, make better decisions and improve customer support.
These same features have come to the data center under the rubric of AIOps, a new genre of infrastructure management features with significant implications for storage.
Most early uses of predictive analytics centered on consumer applications where massive amounts of data could be collected from millions of users, making it easier to justify the large investment in data acquisition, processing and model development. The predictive analytics ROI hurdle is high because it's a sophisticated undertaking. It goes far beyond traditional statistical and probabilistic techniques, using machine learning and, in some cases, neural network-based deep learning to train models and make predictions based on massive data sets. The data-driven approach is perfect for automating IT systems management given the massive size of event logs, systems telemetry and performance metrics today's infrastructure spews out.
Manufacturing, logistics and facilities control systems have pioneered the industrial use of predictive analytics -- for example, Rolls-Royce uses predictive analytics to proactively schedule maintenance and improve the efficiency of its aircraft engines. In storage, predictive analytics is used to predict and proactively remediate device failure, identify performance bottlenecks and optimize system configuration based on historical measurements.
Digesting all that data
Whether it's Netflix or Google Assistant, you've undoubtedly seen that the more you use a system, the better its recommendations, because incrementally improving accuracy primarily depends on having more data to work with. The same applies to predictive storage analytics. The software is only as accurate as the data it has, and both quantity and quality matter; a predictive model based on inaccurate or imprecise data will fail.
For predictive storage analytics software, the need for data translates to collecting massive amounts of system events, internal parameters, performance measures and workload-specific metrics. Baseline telemetry includes:
performance measures, such as total and per-volume IOPS, throughput for various operations -- such as sequential read, random read and sequential write -- and latency;
bandwidth usage and latency, broken out by workload; and
working set (hot data) and cache utilization.
The larger the data set used for model development and training, the higher the accuracy of a predictive statistical or machine learning model. Given that, many vendors aggregate and anonymize data from all their customers. Using data from a much broader and diverse sample of installations enables vendors to significantly improve their predictions and better detect performance, security and hardware anomalies.
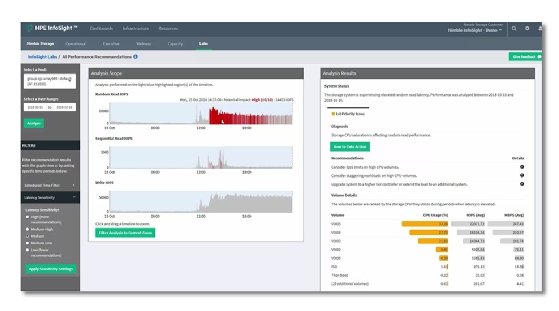
For example, Hewlett Packard Enterprise InfoSight, an outgrowth of HPE's Nimble acquisition, collects 30 million to 70 million sensor data points a day from virtually every deployed Nimble array. The company claims that 90% of the problems it identifies can be remedied before customers detect an issue.
Hewlett Packard Enterprise's InfoSight collects as much as 70 million sensor data points a day from deployed Nimble arrays.
Since the training data set is only used by the storage software vendor for predictive model development, it doesn't need information identifying particular customers, and each customer deployment can benefit from the experiences of others. First, storage vendors use the aggregated data to improve predictive models during the so-called training phase of machine or deep learning. Then, they push the models out to systems management software that pulls real-time monitoring data from individual systems during the inferencing phase. Other models are used for system configuration, capacity planning and troubleshooting to perform root cause analysis.
Predictive algorithms are becoming standard equipment on storage platforms, offering many benefits over reactive approaches to storage management.
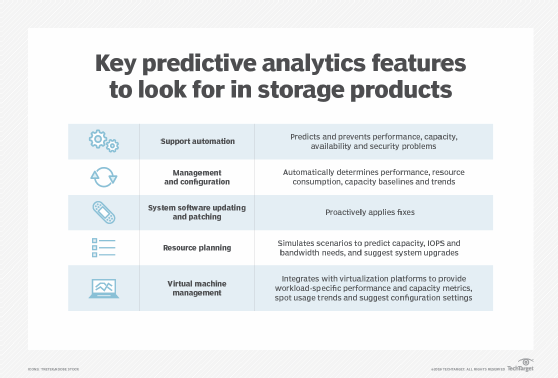
Predictive storage analytics software is typically used to improve a number of tasks. When evaluating products, see how each measures up in terms of these five key features and capabilities:
Support automation predicts and prevents performance, capacity, availability and security problems. Capacity management is the most common application of predictive storage analytics software. Models can analyze usage per device, volume and application in real time and proactively alert when they hit utilization targets. At the administrator's discretion, systems can automatically add allocated space or rebalance existing capacity to prevent it from running out.
Predictive storage analytics can also assist in problem troubleshooting and root cause analysis by correlating and identifying events related to a particular issue. Using aggregated customer data is particularly useful for troubleshooting, because it provides the management system with visibility to the superset of problems from all customers and enables detecting even subtle, previously unseen issues that share a forensic signature with similar problems that have happened elsewhere.
Management and configuration capabilities show up in models that can automatically determine performance, resource consumption, capacity baselines and trends. These include ones that don't fit simple statistical models, such as linear, polynomial regression or periodic temporal fluctuations (seasonal, monthly, weekly). Baselines and trends can be used to automate storage system setup and management and improve resource use and efficiency by optimizing configuration settings and assisting with workload placement.
System software updating and patching features proactively apply fixes -- subject to administrator approval -- including hotfixes that address previously identified system problems. Some vendors use analytics to make beta- or alpha-level code available only to sites that experience a particular problem and meet hardware or other system requirements in hopes that the fix will address urgent problems without needlessly jeopardizing the reliability of other customers.
Resource planning capabilities use the same trend-spotting predictive algorithms to power planning simulations and what-if analysis that enable storage administrators to quickly simulate various scenarios and predict capacity, IOPS and bandwidth needs and suggest system upgrades.
Virtual machine management features integrate with various virtualization platforms -- notably, VMware's vSphere -- to provide workload-specific performance and capacity metrics, spot usage trends and suggest storage configuration settings.
Benefits and recommendations
Predictive algorithms, often paired with other automation and configuration management tools, are becoming standard equipment on storage platforms, offering many benefits over reactive approaches to storage management. These include:
reducing operational expenses by automating storage tasks related to capacity and performance management;
increasing availability by proactively fixing problems, such as running out of capacity on a particular volume; and
increasing resource utilization and efficiency and improving application performance by recommending optimal configurations.
For example, besides predicting and resolving problems before customers realize they have them, HPE claims InfoSight reduces the time spent managing and resolving storage-related problems by 85% and saves 79% in operational expenses.
Storage vendors typically provide management software; therefore, we suggest making predictive storage analytics and other AI-derived techniques a key point of future product evaluations. The same holds for organizations using device-agnostic software-defined storage, such as Cohesity, DataCore, Red Hat Ceph and Gluster, and VMware vSAN. Use the feature list above as part of a product evaluation checklist to determine those that best fit your needs and broader infrastructure management environment.