Understanding code smells and how refactoring can help
It works, but does it pass the sniff test? Code smells can be the canary in the coal mine for poor coding, which calls for refactoring. Explore how to identify and deodorize code smells.
One thing that most application developers and testers eventually encounter -- especially when working with complex applications or across large teams -- is code smells.
"Smelly" code means that the code is inefficient, nonperformant, complex and/or difficult to change and maintain. Code smells might not always indicate a serious problem, but teams that investigate them often discover bad code, drains on application resources or even critical security vulnerabilities embedded within the application's code. At the least, it requires teams to perform code reviews with in-depth tests -- and often reveals a deeper problem with a critical area in the code that needs remedial work.
Explore how software teams can identify code smells and use them to maintain clean code. Specifically, examine how software engineering techniques, such as code refactoring and regression testing, play integral roles in dealing with code smells and fixing the underlying problems.
What are code smells?
Code smells are tangible and observable indications that there is something wrong with an application's underlying code that could eventually lead to serious failures and kill an application's performance. They are usually the result of antipatterns in code, in that they are bad solutions to common software engineering problems.
Code smells signal potential underlying issues with code quality, maintainability and performance. Keep in mind that a code smell is not a bug -- it's likely that the code still compiles and works as expected. Code smells are simply indications of potential breaches of code discipline and software design principles. Put another way: Bugs are faulty code, and they impede the code's functionality. Code smells are code that runs but impedes maintenance, and they signal potential bugs.
What causes code smells?
Put simply, code smells are a result of poor or misguided programming. Teams can often trace these blips in the application code directly to mistakes the programmer made during the coding process. Typically, code smells stem from a failure to write source code in accordance with necessary standards. In other cases, it means that the documentation required to clearly define the project's development standards and expectations was incomplete, inaccurate or nonexistent.
There are many situations that can cause code smells, such as improper dependencies between modules, an incorrect assignment of methods to classes or needless duplication of code segments. Code that is particularly smelly can eventually cause profound performance problems and make business-critical applications difficult to maintain. It's possible that the source of a code smell may cause cascading issues and failures over time.
Smelly code is also a good indicator that a code refactoring effort is in order. Refactoring is a restructuring process that attempts to make code cleaner, more concise and more efficient without altering its core functionality.
Types of code smells
There are many tangible indicators that code might be harboring a more serious problem. Some common code smell examples are the following.
Code smell
Description
Duplicate code
Repeated code segments that appear in multiple locations, violating the "don't repeat yourself" principle and making maintenance challenging.
Dead code
Code segments that are written but never executed, cluttering the codebase and adding unnecessary complexity. This is sometimes the result of speculative generality, in which programmers create code to support an anticipated feature that never materializes.
Large classes
Adding tangential lines of code to an existing class that creates another responsibility for that class. This adds unnecessary complexity and potential duplicate functionality.
Long methods
Excessively long methods that perform multiple responsibilities, making the code difficult to understand and maintain.
Long parameter list
Methods with an excessive number of parameters that decrease readability, suggest poor design and limit code reuse potential.
Long comments
Extensive comments that attempt to explain a complex or poorly written piece of code, indicating a lack of clarity in the implementation.
Unnecessary primitive variables
Overuse of primitive data types when more structured objects could better represent the data and improve code expressiveness. This tendency is sometimes referred to as primitive obsession.
Data clumps
Groups of data items that frequently appear together across multiple methods or classes, suggesting a need for a more cohesive abstraction.
Shotgun surgery
A single change or bug fix that requires multiple small changes across different classes, indicating a lack of well-defined boundaries between components and an excess of dependencies between classes.
Object-oriented abusers
A category of code smell in which code misuses object-oriented programming principles -- encapsulation, inheritance, polymorphism and abstraction. Examples of object-oriented abusers include the following:
Refused bequests, where subclasses don't use the properties or methods inherited by parents, taking on unnecessary responsibilities.
Alternative classes with different interfaces, where two classes with different method names perform the same functions.
Complex conditionals, where the code for a conditional, such as if or switch statements, is needlessly complex.
Temporary fields, in which data fields are created for one specific use case -- often for an algorithm that requires many inputs -- and go unused outside of that specific use case. This adds complexity and violates the single responsibility principle, which states that a class, module or function should only have one well-defined responsibility.
Middle man
When a class's only function is to delegate work to other classes, creating bulkier code. Some design patterns use these intentionally to avoid dependencies; other times, they signal a potential problem with code.
By understanding these indicators, identifying them and responding with systematic refactoring techniques, development teams can proactively improve their codebase, reduce technical debt, and create more reliable and secure applications.
How to eliminate code smells with refactoring
Code refactoring is one of the most effective ways to eliminate code smells and maintain good code hygiene. Regular refactoring helps ensure that code meets a team's guidelines and aligns with a defined architecture.
The best time to refactor code is before adding updates or new features to an application. It is good practice to clean up existing code before programmers add any new code. Another good time to refactor code is after a team has deployed code into production. After all, developers have more time than usual to clean up code before they're assigned a new task or a project.
One caveat to refactoring is that teams must make sure there is complete test coverage before refactoring an application's code. Otherwise, the refactoring process could simply restructure broken pieces of the application for no gain. Regular refactoring is not a good idea when facing tight release schedules -- the tests required take significant amounts of time and might prevent the team from releasing the application on schedule.
There are plenty of tool options available to automate the code refactoring process, including SonarQube, Visual Studio, JetBrains Rider and Eclipse IDE. Many of these tools and their associated plugins enable programmers to execute code restructuring alongside the actual development process. That approach can help teams speed up release cadences when needed.
Rather than viewing refactoring as a burdensome task, teams should see it as an essential investment in their software's long-term health.
Refactoring techniques for code smells
Refactoring encompasses several code hygiene practices. When it comes to eliminating code smells, however, there are three particularly effective techniques: one that focuses on methods, another that focuses on the method calls and a third that focuses on classes.
Composing methods
Composing aims to eliminate redundant methods. There are two ways developers can do this:
Break code down into smaller blocks. Isolate fragmented code, extract it and place it into a separate method.
Identify broken or unnecessary methods, as well as the calls to those methods. Replace the method calls with the method's actual code, and then delete the original method.
Simplifying method calls
The next technique is to simplify method calls that, over time, have become buried in large amounts of code that are daunting to work with. Programmers have several ways to simplify method calls, including the following:
Adding or removing certain parameters.
Renaming methods with ambiguous names.
Separating queries from the modifying component.
Parameterizing methods and introducing parameter objects.
Removing the methods that assign objects certain values.
Replacing the parameter with explicit methods or calls.
Refactoring by abstraction
Finally, refactoring by abstraction comes into play when large chunks of code contain duplications or redundancies. There are two techniques that constitute this approach, both of which focus on class inheritance:
Pull up. The code behind methods that are shared among an entire group of subclasses is extracted into a superclass.
Push down. Method code that lives within a superclass but is only used by a few of the subclasses is pushed down to those respective subclasses.
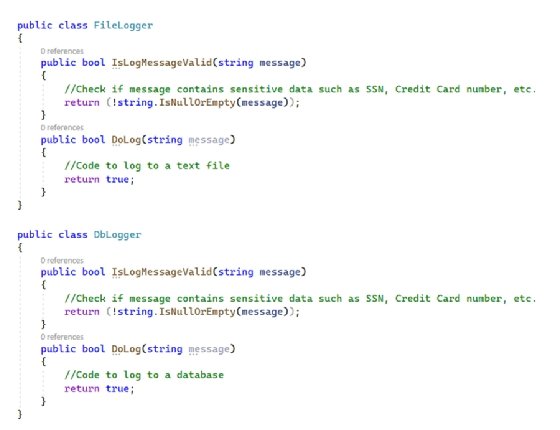
Consider the code snippet in Figure 1 that illustrates two classes: FileLogger and DbLogger. As the names suggest, FileLogger is responsible for logging data to a file, and DbLogger logs data to a database.
Figure 1. An example of code redundancy
The IsLogMessageValid method returns true if the log message is valid and false if it is not. In this case, a log message is not considered valid if it contains a null or empty string. Likewise, the log message is considered invalid if it contains any sensitive data, such as a Social Security or credit card number.
Unfortunately, this approach is a little redundant. Coders need to write the same logic twice -- one for each of the two classes -- to check if the log messages are valid.
A better way is to refactor these two classes and create an abstract class. In Figure 2, the IsLogMessageValid method has moved to an abstract class, which helps mitigate potential code redundancy.
Figure 2. An example of refactoring by abstraction
The role of testers in refactoring
It's critical to ensure that code is testable before refactoring begins. This includes -- but is not limited to -- unit tests, regression tests and integration tests. To this end, it helps to involve the testing team throughout the refactoring process because tests might fail once development teams start to change the code. Regression testing is particularly important in refactoring because it ensures that the application's functionality remains intact.
Refactoring should be a recurring activity, and it's critical that it be a collaborative effort. By regularly performing code hygiene tasks together, software teams can create centralized strategies to identify code smells and learn from mistakes. It's also valuable for testers to learn about the code restructuring process since it can help them improve existing test cases and procedures. This coordination might even help them write better test automation code and cut down on manual maintenance tasks.
The key to successful refactoring lies in collaboration between developers and testers, comprehensive test coverage and a commitment to good code hygiene. Rather than viewing refactoring as a burdensome task, teams should see it as an essential investment in their software's long-term health. It enables more nimble development, easier maintenance and ultimately higher-quality software products.
Editor's note: Matt Grasberger contributed to updating this article in 2025.
Joydip Kanjilal is a developer, author and speaker who has written numerous books and articles on development. He has more than 20 years of experience in IT, particularly in .NET.
Matt Grasberger is a DevOps engineer with experience in test automation, software development and designing automated processes to reduce work.