13 API security best practices to protect your business
APIs are the backbone of most modern applications, and companies must build in API security from the start. Follow these guidelines to design, deploy and protect your APIs.
An application programming interface enables software applications to interact with each other by controlling how requests are made and handled. Thanks to the rise of cloud computing and a shift from monolithic applications to microservices, application programming interfaces are a pivotal element in today's digital world.
There are likely millions of public APIs in use by developers and organizations around the globe. Thousands upon thousands of public APIs are available in online collections and repositories such as GitHub, publicapis.io and Postman.
In a 2024 Postman survey of over 5,000 developers, 74% of respondents (versus 66% in 2023), said they are API-first, meaning they look to build and integrate application services that are open and heavily API-dependent. The same survey also found that the average application uses between 26 and 50 APIs.
APIs are the backbone of most modern applications, and their successful execution is essential to many organizations' revenue and growth. Therefore, API security is paramount to modern information and application security strategies.
What is API security?
API security refers to the protection of APIs from cyberthreats, unauthorized access and data breaches. APIs bridge different software applications, enabling seamless communication and integration. As organizations increasingly rely on APIs for cloud services, mobile applications and IoT devices, securing them becomes critical to prevent data leaks, unauthorized transactions and business disruptions.
API security aims to ensure API requests are authenticated, authorized, validated, cleansed and can still be processed when the service is under load. A modern application or service has numerous API endpoints that use different protocols and request formats, so the characteristics of API security differ from those of standard web servers, which only need to protect a few standard ports and requests.
API security comes from the following:
- Network security, identity and access management controls.
- Effectively coded APIs that handle and drop invalid and malicious incoming requests to maintain the confidentiality, availability and integrity of the data and resources the APIs expose.
Why API security is important
As more businesses enable access to data and services through APIs, these vectors present an attractive target for data theft and software attacks due to several factors:
- APIs often handle sensitive data such as personal information, financial transactions and healthcare records. A compromised API can expose this data to attackers, leading to compliance violations, reputational damage and financial losses.
- Threat actors exploit API vulnerabilities through attacks including broken authentication, injection attacks, excessive data exposure and improper rate limiting. Without adequate security controls and testing, attackers can potentially manipulate API endpoints, gain unauthorized access, or disrupt critical business operations through denial-of-service (DoS) and other attacks.
- API sprawl -- when an organization's use of APIs outstrips efforts to manage them effectively -- creates data conflicts, excessive resource use and (especially with public APIs) use of standards and protocols beyond the organization's purview.
Surveys of organizations worldwide underscore the scope and seriousness of the problem.
In a 2025 survey, Traceable found that 57% of organizations reported at least one data breach related to API abuse in the previous two years, and only 38% were testing their APIs regularly for security vulnerabilities. And in a separate survey in 2024, Salt Security found that API use increased 167% from the previous year and 95% of respondents experienced security challenges in production APIs.
API security and AI
While there's quite a bit of chatter in the industry about tools such as generative AI (GenAI) causing more API security risk, it remains to be seen. Any data input or output using AI tools and services should be carefully reviewed for accuracy and potential AI-specific risks, such as data tampering. To date, however, this has not proved to be an AI-specific issue.
API security best practices
The following 13 best practices can help expand and elevate the security of an organization's APIs:
1. Authenticate and authorize
To control access to API resources, you must carefully and comprehensively identify all related users and devices. This typically requires client-side applications to include a token in the API call so that the service can validate the client.
Use standards such as OAuth 2.0, OpenID Connect and JSON Web Tokens to authenticate API traffic and to define access control rules or grant types that determine which users, groups and roles can access specific API resources. Specific API keys can also be used securely, particularly for machine-to-machine interactions.
Always follow the principle of least privilege (POLP). If a user just needs to read a blog or post a comment, assign only those permissions.
2. Implement access control
Organizations that want to enable third parties to access internal data and systems through APIs must introduce and test controls to manage that access: who, what and when, as well as checks on data access, creation, update and deletion -- reflecting the zero-trust security model. Many organizations might require some combination of role-based access control (RBAC) and attribute-based access control (ABAC).
Well-designed APIs can also apply rate limits and geo-velocity checks and act as an enforcement point for policies such as geo-fencing and I/O content validation and sanitization. Geo-velocity checks provide context-based authentication by determining access based on the speed of travel required between the previous and current login attempts.
All these checks are applied by middleware code that's part of the API application. Middleware handles requests before passing them on to be fulfilled.
3. Encrypt requests and responses
All network traffic should be encrypted -- particularly API requests and responses, as they'll likely contain sensitive credentials and data. All APIs should require HTTPS, ideally with TLS 1.2 or above (mutual TLS, or mTLS, is also common for API-to-API communication). Enabling HTTP Strict Transport Security where possible is better than redirecting HTTP traffic to HTTPS, as API clients might not behave as expected.
4. Validate the data
Never assume API data has been sanitized or validated correctly. Implement your own data cleaning and validation routines on the server side to prevent standard injection flaws and cross-site request forgery attacks, and use parameterized queries and prepared statements in database queries. Debugging tools such as Postman and Chrome DevTools can help examine the API's data flow and track errors and anomalies.
5. Assess your API risks
Another important API security best practice is to perform a risk assessment for all APIs in your existing registry. Establish measures to ensure they meet security policies and are not vulnerable to known risks. The Open Worldwide Application Security Project (OWASP) "API Security Top 10" vulnerabilities list is a good resource for keeping tabs on existing attacks and malicious software.
A risk assessment should identify all systems and data affected if an API is compromised and then outline a treatment plan and the controls required to reduce risks to an acceptable level.
Document review dates and repeat assessments whenever new threats arise, or the API is modified. Ideally, review this documentation prior to any subsequent code changes to ensure security and data-handling requirements aren't compromised.
6. Share only necessary information
API responses often include an entire data record rather than just the relevant fields, relying on the client application to filter what a user sees. This is lazy programming, and it not only slows response times but also provides attackers with additional information about the API and the resources it accesses.
Responses should contain the minimum information necessary to fulfill a request. For example, if an employee's age is requested, the date of birth shouldn't be returned as well.
7. Choose your web services API
There are three dominant options to access web services through APIs: SOAP, a communications protocol; REST API or RESTful API, a set of architectural principles for data transmission; and GraphQL, a query language and runtime for APIs that allows clients to request exactly the data they need. They use different formats and semantics and require different strategies to ensure effective security.
SOAP. SOAP security is applied at the message level using digital signatures and encrypted parts within the XML message itself. REST relies heavily on access control rules associated with the API's universal resource identifier, such as HTTP tags and the URL path.
Use SOAP if your primary concerns are standardization and security. While both options support Secure Sockets Layer/Transport Layer Security (SSL/TLS), SOAP also supports Web Services Security, identity verification through intermediaries rather than just point-to-point verification provided by SSL/TLS, and built-in error handling. However, SOAP exposes components of application logic as services rather than data, which can make SOAP complex to implement and might require an application to be refactored.
REST. REST, meanwhile, is compatible with various data output types -- including JSON, comma-separated values and HTTP -- while SOAP can only handle XML and HTTP. In addition, REST merely accesses data, so it's a simpler way to access web services. For these reasons, organizations often prefer REST for web development projects. However, security must be built in for data exchanges, deployment and client interactions.
GraphQL. GraphQL is gaining momentum for web services and APIs, particularly for applications that require high flexibility, efficiency and complex data request models. GraphQL is well suited to the following:
- Front-end API queries that allow developers to only request specific data without a need to modify back-end data sets or components.
- Apps with different clients -- web, mobile and third-party partners -- that can request customized data from the same API without separate endpoints.
However, GraphQL allows for almost infinite nesting of queries, which can lead to DoS scenarios. It is also susceptible to broken object-level authorization (BOLA) attacks because it exposes a single endpoint (/graphql), making it easy to overlook authorization checks at the object or field level.
8. Record APIs in an API registry
Nobody can secure what they don't know. It's therefore essential to record all APIs in a registry to define characteristics such as its name, purpose, payload, usage, access, live date, retired date and owner. This will avoid shadow or silo APIs that have been forgotten, never documented or developed outside of a main project, possibly through mergers, acquisitions or test or deprecated versions.
Record details of the information to be logged, such as who, what and when. This will help meet compliance and audit requirements and aid forensic analysis in the event of a security incident.
Good documentation is particularly important for third-party developers wishing to incorporate those APIs into their projects. The API registry should include links to the document or manual that contains all technical API requirements, including functions, classes, return types, arguments and integration processes.
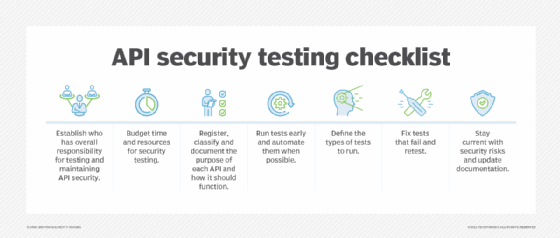
9. Conduct regular security tests
In addition to thoroughly testing APIs during development, security teams must regularly check the security controls that protect live APIs to ensure they're functioning as expected and behaving as documented. Ideally, API security testing is comprehensive and continuous to address vulnerability discovery and remediation.
Incident response teams should create a plan for handling alerts produced by threat detection and other security controls that indicate an API attack.
10. Stash your API keys
API keys identify and verify access for the application or site that calls an API. They can also block or throttle calls made to an API and identify usage patterns.
API keys are less secure than authentication tokens and require careful management. To prevent accidental exposure, avoid embedding API keys directly in their code or in files within the application's source tree. Instead, store them in environment variables or in files outside of the application's source tree. Better still, use a secrets management service that protects and manages an application's API keys.
Even with these measures in place, always delete unneeded keys to minimize exposure to attack and periodically regenerate keys -- particularly if a breach is suspected.
11. Add AI to API monitoring and threat detection
AI-enabled behavior analysis can significantly improve overall API security. It benchmarks regular API traffic and provides visibility into how users access and consume APIs, which can help developers fine-tune threshold settings for context security checks. Threat detection tools can use this information to look for anomalous behavior to flag or to stop misuse or a potential attack.
Attackers probe an API repeatedly to find vulnerabilities or logic they can exploit, so real-time monitoring is essential for attack detection and response. This approach requires no predefined policies, rules or attack signatures, so it reduces the need for constant updates to stop new and evolving attacks.
12. Understand the full scope of secure API consumption
API security also covers the third-party APIs it consumes. Before building an application or service that handles third-party data using APIs, it's necessary to understand how they work and how to integrate them fully.
Read API documentation thoroughly, paying attention to the process and security aspects of the API's function and routines, such as required authentication, call processes, data formats and any potential error messages to expect. A good approach is to build a threat model to help understand the attack surface, identify potential security issues and incorporate appropriate security mitigations at the outset.
APIs create countless opportunities for organizations to improve and deliver services, engage customers and increase productivity and profits -- but only if they are securely implemented.
For more information on API security best practices, follow these examples of API documentation best practices and learn the importance of an API versioning strategy.
13. Implement API security gateways and tools
Keep APIs behind a firewall, web application firewall or API gateway -- accessed through a secure protocol, such as HTTPS -- to provide baseline protection, such as scanning for signature-based threats and injection-based attacks.
In recent years, a new category of security platforms has emerged, known as Web Application and API Protection (WAAP). This combines web application firewall (WAF), runtime application self-protection (RASP), API and microservice protection and bot protection, among other capabilities.
Most common API security risks
Organizations should address the following API security risks during development and whenever an API is updated:
- Broken object-level authorization. BOLA occurs when a request can access or modify data the requestor shouldn't have access to, such as the ability to access another user's account by tampering with an identifier in the request.
- Broken function-level authorization. This arises when POLP isn't implemented, often due to overly complex access control policies. It results in an attacker being able to execute sensitive commands or access endpoints intended for privileged accounts.
- Broken user authentication. Like BOLA, if the authentication process is compromised, an attacker can impersonate another user on a one-time or even permanent basis.
- Excessive data exposure. API responses to a request often return more data than is relevant or necessary. Even though the data might not be visible to users, it can be easily examined and might lead to a potential exposure of sensitive information.
- Improper asset and configuration management. API development and deployment are usually fast-paced, and thorough documentation is often omitted in the rush to release new or updated APIs. This leads to exposed, deprecated and/or shadow endpoints. It also contributes to a weak understanding of how older APIs work and need to be implemented or maintained. Poor configuration of APIs and related components and services might also lead to unnecessary exposure or exposed vulnerabilities.
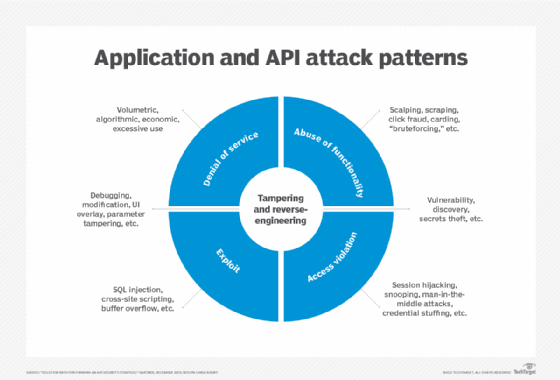
- Lack of rate limiting and possible resource exhaustion. API endpoints are usually open to the internet and, if there are no restrictions on the number or size of requests, are open to DoS and brute-force attacks.
- Injection flaws. If request data isn't parsed and validated correctly, an attacker can potentially launch a command or SQL injection attack to access it or execute malicious commands without authorization.
- Mass assignment. Software development frameworks often provide the functionality to insert all the data received from an online form into a database or object with just one line of code -- known as mass assignment -- to remove the need to write repetitive lines of form-mapping code. If this is done without specifying what data is acceptable, it opens a variety of attack vectors.
- Insufficient logging and monitoring. Many API and application implementations lack effective logging and monitoring, which leads to security "blind spots" for security and application development teams when APIs are attacked.
Editor's note: Michael Cobb originally wrote this article in 2021, and Dave Shackleford expanded it in 2025 to add information and improve the reader experience.
Michael Cobb, CISSP-ISSAP, is a renowned security author with more than 20 years of experience in the IT industry.
Dave Shackleford is founder and principal consultant at Voodoo Security, as well as a SANS analyst, instructor and course author, and GIAC technical director.







