Part of:Navigating CrowdStrike: Lessons from the outage
Software testing lessons learned from the CrowdStrike outage
After the recent CrowdStrike outage, organizations are keen to prevent and prepare for potential future disruptions. These key security and quality lessons can help.
The initial confusion has cleared since CrowdStrike's software caused a Windows system outage on July 19, 2024.
Since then, enough time has passed that a retrospective could be valuable, not just for CrowdStrike, but for the greater software community. In this article, we cover what happened, why, who was impacted and what your organization might be able to learn from this incident.
What happened in the CrowdStrike outage?
Antivirus and security software typically needs to run in a privileged mode, something other applications cannot touch. If security software runs with the same security as everything else, then malevolent software could act like a biological virus, finding the security software and overwriting or destroying it.
In a 2009 decision, the EU claimed that Microsoft's antivirus software, Windows Defender, had an unfair, monopoly-like advantage in that it could run in the kernel -- the most privileged and incorruptible memory and disk space. The EU forced Microsoft to allow third-party developers, such as CrowdStrike, to run in the kernel.
CrowdStrike's initial incident report claimed that it was not new code, but a "content update" -- similar to the signature of a virus -- that caused a crash in the software. Because this was running in the kernel, or OS, this exception could not be trapped. Because the software ran on bootup to check for viruses, a simple reboot could not fix the issue. Apple and Linux computers do not run antivirus software in this privileged mode and did not manifest the issue.
What impact did the CrowdStrike outage have?
The dysfunctional security update affected only about 1% of the total number of Windows computers. Yet, as of 2023, CrowdStrike has 15% of the software security marketplace. That means that CrowdStrike's high-end security software is deployed on computers that are considered mission-critical.
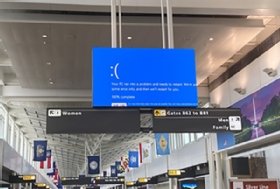
The CrowdStrike outage caused digital signage at Dulles International Airport to display the blue screen of death on July 19, 2024.
On July 19, 2024, all four major air carriers, as well as hospitals; 911 operators; and local, state and federal government agencies, all experienced outages, as they were unable to access servers and clients that ran Windows. Delta Air Lines was particularly affected, with six days of direct service interruptions responsible for a total of $500 million in impact.
CrowdStrike has denied these allegations through a spokesperson, capping its liability in the "single-digit millions" and pointing out that other airlines were up and running again within 24 hours. An estimate by Parametrix of the direct losses to all companies is $5.4 billion. This does not count damage to reputation or lost revenue in the future.
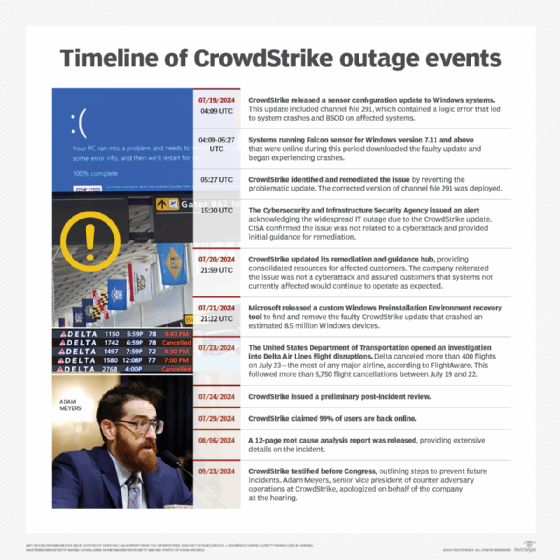
A timeline of the CrowdStrike outage events
Takeaways from the CrowdStrike post-incident report and root cause analysis
While the incident report itself is more than a little ambiguous, using high-level terms that could have multiple meanings, a few things are clear. The company has the source code, some of which runs in the Windows kernel, as well as content updates. The content updates include both Rapid Response Content, which needs to be deployed as soon as possible due to serious security vulnerabilities, along with more routine changes, which go through a more rigorous process. TheRapid Response Contentappears to be so critical that it skips the line and deploys to all systems, bypassing any staged rollouts that customers try to put into place. The point of having two processes was to balance the risk of introducing a problem with the need for an urgent fix. Of course, a change that went through as Rapid Response Content turned out to introduce the bug that took out any system running it.
It's easy to jump to exactly where the defect was -- CrowdStrike itself claimed it was a bug in its test system. Specifically, the report stated: "Due to a bug in the Content Validator, one of two Template Instances passed validation despite containing problematic content data." This is a bit of an odd statement, putting the bug in the test system instead of framing it as a bug in the data that the tests missed. According to the later root cause analysis, released Aug. 6, 2024, there was a missing test for a scenario where the signature was literal text, instead of a pattern match using wildcards. There was also a mismatch between the expected number of inputs, which caused the software to access memory that was out of bounds.
DevOps and automation, at least in theory, resolve several risks that reduce the reliance on humans, who can be inconsistent and prone to error. Yet, as it turns out, it is humans who write the computer programs doing the automating -- those programs are prone to error, too.
First, the test data itself was malformed. Then, the test software was a missing test. Then, the architecture failed to trap the failure with something like a try/catch block or some other form of structured exception handing. Running code inside an exception handler causes it not to crash, but to jump elsewhere in the code -- the handler -- in the event of a divide-by-zero or other type of error that causes a crash if unhandled.
Companies could not choose to do a staged deploy even if they wanted to. One can argue this sort of "alignment of the stars" is so rare it could only happen once, but there are other explanations. Most analysts of the Space Shuttle Challenger disaster, for example, concluded the system was so incredibly well protected and redundant, with standards that were so conservative, that it was thought impossible to fail. Thus, it was easy to allow an exception that was a little bit outside the rule, as the rule was overprotective. One term for this is normalization of deviance.
One comment buried in the post-incident report is the suggestions for improvement, including "local developer testing," as well as "content update and rollback testing." The implication of these comments is that developer testing was not occurring -- that, had a programmer tested the change on a machine, real or virtual, they would have seen the error and been able to prevent it.
If that comment does not lead to more questions and better answers about the CrowdStrike incident, hopefully, it might at least lead to questions for your organization.
What can your organization do in the wake of the CrowdStrike outage?
It can be helpful to think of testing and quality efforts as a bit like insurance -- spend a little money now to reduce the impact if something goes wrong later. Like health insurance, the hope is to never need the benefits -- yet the risk of going uninsured is not worth it. That said, here are seven lessons to consider, at a time in history when, perhaps, the idea of risk and its impact might be something management is willing to consider and take action to mitigate.
Perform impact analysis
Look at the worst possible outcomes, and then work backward to measure them and see how to assess risk. Soap opera tests and soap opera analysis are two ways to do this in a couple hours in a cross-functional workshop.
Reexamine the balance between reliability and resilience
Reliability focuses on continuous uptime, high availability and the absence of defects. Resilience sees failure as inevitable and focuses on fast issue discovery, service restoration, backup, cutover and redundancy to minimize the impact of failure. It is arguable that CrowdStrike overly embraced the DevOps values of "move fast and break things" with the option to roll back -- without considering just how different 1% of Windows kernels are from, say, an average website. This is a chance to reevaluate the production systems, as well as the human analysis work, for new changes.
Ensure independent humans are doing testing and perform end-to-end testing
In an age where people see tester as a bad word or overhead, organizations keep introducing defects that an actual person doing testing would catch. If the organization is not ready to have a tester role, developers can check each other's work or implement cross-team testing, where teams test each other's work with a beginner's mind.
Implement a test strategy
Look at the last dozen defects in the bug tracker that escaped all the way to production. Arguably, most testing failures -- coding failures and requirements failures -- are not failures of automation. It is not that the team did not have time to automate the process of checking for the defect. Instead, they are failures ofimagination; no one thought to test for that.
The CrowdStrike issue might prompt you to reconsider where the organization's test ideas come from, as well as how they are filtered and selected. In other words, you might reconsider what the test strategy is. You might find there is no coherent, explicit test strategy. Note that a list of types of testing -- unit, functional, stress, end to end and so on -- is not a coherent test strategy under this definition. This could be an opportunity to create one.
Reconsider the risk potential and investment in quality and testing
Odds are the amount your group invests in testing is not a conscious choice, but instead the result of a thousand small, unconscious choices combined with the status quo. That is a bit like handling risk like an untended garden and then complaining about the quality, size and flavor of the fruit. After completing a test strategy, measure the investment of time the organization is spending as a proxy for cost, and ask if it is the right mix.
Own up to mistakes
After the outage, CrowdStrike reportedly sent $10 gift cards to partners and teammates helping customers through the situation as a gesture of goodwill and thanks for their patience. This sort of disproportionate response created conflict and confusion. To be fair, it might have been the move of a rogue publicity team. Still, consider how your organization would engage external partners in the face of a serious outage. That might be something to workshop before it happens.
Lessons for commercial software integration post-CrowdStrike outage
Finally, let's consider what organizations can do to limit the risk and effect of failure for commercial software:
Reevaluate preproduction stage testing. Again, the issue here is balancing risk, reward, effort and timing. In some cases, stage testing is not even possible for SaaS products. In that case, consider reviewing what the vendor does to limit risk and what you can do as well.
Contemplate incremental rollouts. For desktop software and OSes, consider incremental rollouts to parts of the enterprise at a time. Roll out updates first for systems that are safe to fail and then up to high availability systems and mission-critical systems last.
Find out if the vendor can "skip the line" on updates. Incremental rollouts don't help if the vendor can force-upgrade any computer connected to the internet. If that is the case, additional measures might be called for, such as investigating the possible impact and, in life-critical systems, separating them from the public internet.
Consider cyber insurance. Some organizations provide not quality assurance but cyber insurance. This could be especially valuable for outside organizations that do not build their own software, but are reliant on a vendor for operations.
DevOps and automation, at least in theory, resolve several risks that reduce the reliance on humans, who can be inconsistent and prone to error. Yet, as it turns out, it is humans who write the computer programs doing the automating -- those programs are prone to error, too. Through CrowdStrike and other issues, there's a chance to rethink security and quality.
Let's take it.
Matt Heusser is managing director at Excelon Development, where he recruits, trains and conducts software testing and development. The initial lead organizer of the Great Lakes Software Excellence Conference and lead editor of How to Reduce the Cost of Software Testing, Heusser also served a term on the board of directors for the Association for Software Testing.
Dig Deeper on Software testing tools and techniques