caching

What is caching?
Caching -- pronounced "cashing" -- is the process of storing data in a cache, which is a temporary storage area that facilitates faster access to data with the goal of improving application and system performance.
A common example of caching is a web browser that stores page content on a local disk for a designated period of time. When the user first visits the website, the content is downloaded from the web server and saved to a local directory. If the user revisits the website, the content comes from the local cache rather than the server. In this way, page content loads much faster into the browser than it would if it were downloaded from the web server. This saves the user time, reduces network traffic and minimizes the load on the web server.
The idea behind caching is to temporarily copy data to a location that enables an application or component to access the data faster than if retrieving it from its primary source.
A web browser, for example, can access data faster from a local disk cache than it can through an internet connection to a web server.
What are different kinds of caching?
The same principle that applies to internet caching pertains to a variety of other types of caching:
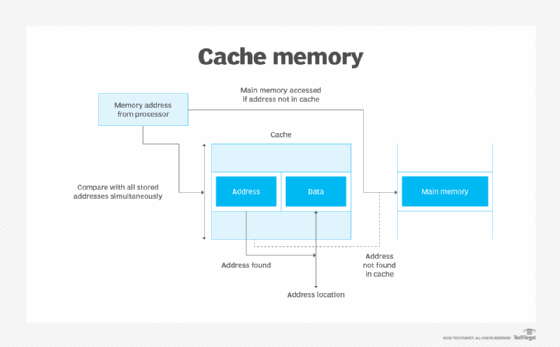
- CPU caching. Most central processing units (CPUs) include high-speed caches, such as L1 and L2, that sit between the computer's main memory and the processor, providing the CPU with faster access to program instruction sets than the main memory can deliver.
- In-memory caching. Applications often use a system's main memory to cache data stored on disk. For example, a database management system (DBMS) might use caching for read-heavy workloads or complex query
- Virtual memory caching. A computer's memory management unit (MMU) often includes a Translation Lookup Buffer (TLB) to cache recent translations between virtual and physical addresses.
- Server-side caching. Web applications often cache data that comes from other systems. For example, a web application might cache data it retrieves regularly from a back-end database.
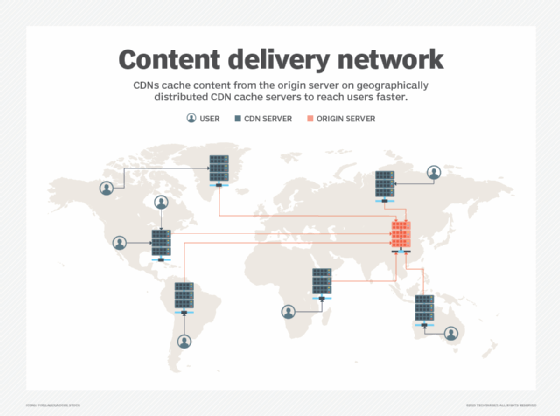
- CDN caching. Content delivery networks (CDNs) store cached data in multiple proxy servers that are geographically distributed to serve content to users in closer proximity to where they reside, helping to improve a web application's performance.
- Storage controller caching. A storage controller might include a local cache to help streamline input/output (I/O) operations. A controller cache can improve operations between the controller and application, as well as between the controller and disk.
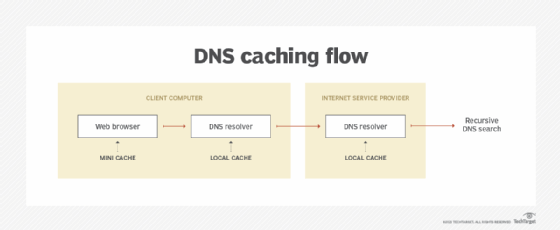
- DNS caching. Domain Name System (DNS) servers often cache DNS lookup data to help resolve host names to Internet Protocol (IP) addresses more quickly.
These are only some of the ways caching is used to improve performance, which is why the technology is so pervasive. Caching, however, can also have its downsides. For example, a browser might cache sensitive data that can be compromised, or cached data might become outdated or out of sync with the source data. If a cache grows too large, it can negatively affect performance.
Caching can also degrade performance if the wrong data is cached. When caching is used, an application will first check the cache for the data it needs. If it finds the data, it's a cache hit. If it doesn't find the data, it's a cache miss and the application must retrieve the data from the primary source, adding an extra step to the data retrieval process. When there are too many misses, the application might perform worse than if caching hadn't been implemented.
Caching should be carefully planned for optimal selection of both data to cache and the length of time the data should be retained. For example, if data changes frequently, you might limit how long the data is retained in cache or perhaps not cache it at all. Your approach to caching will depend on the type of cache, the nature of the data and the applications accessing the data.
Learn the difference between cache and RAM, discover how to get the most out of cloud caching appliances and gateways and explore the top CDN benefits for today's enterprise.