Designing and Building Security Operations center
In this excerpt of Designing and Building Security Operations Center, author David Nathans reviews the infrastructure needed to support a SOC and maintain SOC security.

The following is an excerpt from Designing and Building Security Operations Center by author David Nathans and published by Syngress. This section from chapter three outlines the security needed to maintain SOC security.
If you ever thought you could just sit back and wait for the screen to tell you something bad happened on your network or with a host system and have lights and sirens go off when someone accesses something they should not, then you are about to have a rude awakening. In most cases, there is no silver bullet to security that will show you an attack has taken place. Most times to catch the bad guy an analyst will need to be patient and also be very determined not to give up looking for that "needle in a hay stack" that will lead them to find security issues needing to be addressed. When it comes to building a SOC, it can be as simple as one person looking at an IDS all day long or it can be as complex as a disperse team of 2500 people all managing and maintaining hundreds of different types of devices around the world. In either case, large or small, you have to take into consideration the same three areas of infrastructure when you are building your SOC.
ORGANIZATIONAL SECURITY INFRASTRUCTURE
As defined above, the organizational infrastructure deployed at the enterprise level is the actual infrastructure you are going to use to protect all the required areas of your organization. These are the devices and technology that will be deployed across the entire enterprise in key locations that will perform the actual job of protecting, detecting, or stopping malicious behavior or attacks. This can be the firewall used at the perimeter or in your network or even at third-party companies and cloud service providers all the way to the antivirus software on a user's endpoint computer. When you look at a defense-in-depth approach to security, you will find many different systems that all need to be managed and monitored by trained security professionals to ensure they all work and are configured properly, they are being looked at and important alerts are being addressed. This section is not here to help you design or build the security of your network. Instead it is here for you to get a feeling, appreciate, or to help others understand the daunting task your SOC may face in managing and monitoring your organizations security. Some people believe that it is not a big deal to run a SOC, you just sit in front of the computer and read whatever the screen tells you and then call someone. I wish it was that easy because then we would not see so many data breaches in the news. When we look at a typical organizational security infrastructure, some people like to talk in terms of a defense-in-depth strategy because it is easy to break down the things needed for security into areas that will be deployed on the network infrastructure.
Let us take a quick look at some of the organizational security infrastructure that would be needed at various levels of that defense-in-depth strategy. This is not a complete or exhaustive list but rather just a sampling to help your thought process around what is really going to be needed by your SOC if you have to manage, maintain, or monitor all this stuff. Keep in mind that I am not going to explain the function of these devices but rather how these technologies are viewed from a SOC perspective or how they would integrate, be managed by, or be utilized within your SOC.
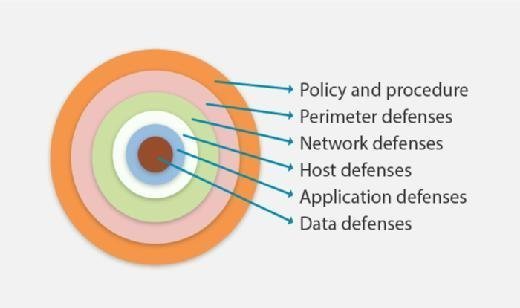
PERIMETER DEFENSES
At your perimeter, there are a few different types of technologies that you may want to use. But first understand that the perimeter is where your organizations control and management stop and some other service provider, business partner, or untrusted connection begins. The security model here is to prevent as much getting into your network as possible and detect all that you can if you cannot specifically stop it.
The first type of device in this area that you may think of is a firewall. Firewalls are vital to a SOC, they can tell you a lot about what is going on and what is coming into your network. The logs from a firewall need to be collected and analyzed, they are where you are going to find performance issues related to denial of service attacks, attempts by systems to violate access rules or devices being denied access due to many other reasons. But it is not always what is being denied on your firewall that is important. You almost always need firewall logs to help you determine the real IP address of an external system that is accessing your network if you are using Network Address Translation. When you translate real routable internet addresses to internal non-Internet routable addresses, you have to have a way to lookup the relationship to determine who is doing what. Without your firewall logs, the SOCs task of translating back and forth is going to be nearly impossible.
Designing and Building Security Operations Center
Author: David Nathans
Learn more about Designing and Building Security Operations Center from publisher Syngress
At checkout, use discount code PBTY25 for 25% off these and other Elsevier titles
Next, we can think about a VPN or remote access system, this is where members of the organization will connect from outside the network to access internal resources. It is vital to maintain this system to ensure appropriate access is granted to users and that when people leave or no longer need the access it is revoked or taken away. So, monitoring users that access this resource is very important but also looking at where someone is accessing the system from may be even more important. If you see someone logging into the VPN from half-way around the world but they are currently in the office and you just saw them getting a cup of coffee then you may have a problem. Your SOC should be able to utilize these basic systems to gain valuable visibility into what security issues may be impacting your organizations network perimeter and who may be getting unauthorized access. Of course there are many more devices like proxy servers you may find in the perimeter of your network but let us move on.
NETWORK DEFENSE
The next ring or layer deep in your defense strategy is the internal network. This is the internal portion of your organization that communicates together in potentially one or more different segments or areas. Security-relevant items you will typically find here are things like intrusion detection or prevention systems, network access control (NAC) systems, along with data loss prevention systems and behavioral or anomaly detection systems. IDSs should be set up wherever there is a network segment that can communicate with another network segment and data traffic passes between those two different networks or areas. This will act like a choke point and allow you to see all the network traffic that are successfully passed and evaluated by signatures internal to the IDS and determined if anything was bad or not. This could be traffic such as hackers trying to exploit vulnerabilities. The output of the IDS is vital for the SOC to review and evaluate but to also manage and to keep the system updated with the latest signatures to detect bad network traffic. NAC systems are also great at helping to prevent systems that are not owned by the organization to connect to an internal network. The SOC should keep a close eye on the changes to a network and what devices are connected or not connected. An attacker does not need to be outside the network in some far off place, they could be inside an organization's own four walls trying to get access to data and resources or they could be from an unattended conference room. Logs and alerts from these types of systems are important information that should be collected and analyzed by the SOC, this could also include systems that attempt to connect to any wireless networks or try to impersonate the real wireless network the organization is running.
HOST DEFENSES
Quickly thinking about host defenses you would want your SOC to manage and monitor would include systems like antivirus, device controls for USBs or host-based data loss prevention systems. When antivirus software detects the presence of a virus there are a number of things that happen, one of which is hopefully cleaning the virus. But often times there are viruses that get detected that cannot be cleaned. There are many reasons for this but more importantly there has to be some notification of this type of condition that gets back to the SOC so that manual intervention can take place and the impacts of the virus will not cause any real issues. Often viruses are designed to steal data or open up doors to allow attackers easier access into protected networks. When data are going to leave your network, you should evaluate them to ensure they are supposed to leave and that they are being sent by the right person who has permission to send it and that its going to a known or reliable destination. Data loss prevention systems can operate at the network level and the host level, these systems are configured with rules to detect important data that an organization owns and ensure it is being moved across a network properly. The rules that these systems operate with have to be maintained and alerts for violations of those rules need to be reviewed and acted upon by the SOC.
APPLICATION DEFENSES
Applications that perform critical functions or store important data for your organization need to be protected as well. These applications can live almost anywhere in your network at your organization from individual hosts to primary servers or mainframe computers. This is a fairly large and broad area for security as there are many different considerations in how to protect different applications but also for how a SOC would interface with those protection systems. It is important that applications are patched, a SOC that runs regular vulnerability scans should be able to detect when an application is out of date with its patches and escalate that information as a notification to the application owner in order to get it updated. Viruses, shellcode, and other malicious logic can take advantage of your applications and make them do things that they were not supposed to. Being able to detect when application files are inappropriately being modified or when a user keeps trying their password over and over again 1000 time per second are all things that the SOC needs to be on the look out for.
DATA DEFENSE
You have all these layers of defense but it all comes down to the data and the resources storing that data. What kind of protections will you put in place to protect your data? Will you use file and volume encryption on your endpoint devices, secure vaulting on your servers, special group access, or even physical protections? Regardless of how you decide to protect your data, someone has to watch and react to alerts or modify the systems rules as needed.
POLICIES AND PROCEDURES
Although not as technical as a ring like we have just been reviewing, policies and procedures will have large impacts to not only how your SOC operates but also what they are able to do and how they will do it. When you have a web proxy in place to protect your users from going to malicious sites, your SOC needs to review those events to ensure there are no infected systems with malicious software causing systems to access bad websites but your organization may also have policies on what can be download or what an employee is allowed to view on their computer. If you have a policy that says nobody is allowed to research guns and weapons while at work on a work computer then it may be the responsibility of your SOC to catch that and to properly report it to the HR department. There are many other policies and procedures that will impact the operation of your SOC, carefully review what your organization has and see what can be included into the SOC as part of their business objectives and help business controls. The policies and procedures will touch every aspect of not only how the SOC operates but how devices are configured, tuned, and deployed to protect against.
SECURITY ARCHITECTURE
Now that we have talked about some of the enterprise level devices and organizational infrastructure out there that your SOC may be responsible for or get information from we need to talk about how this all comes together. If you were starting off from scratch or if you really need to take a good look at what you have and want to make sure you have the right equipment to protect your network, you would need the help of a security architect. This is someone who understands the needs and goals of the organization and who has a good understanding of where potential weaknesses could be. They will then work to recommend technology or configurations of existing systems to improve the overall security posture of a network. They will work with the larger IT organization to purchase, configure, and install security products that will monitor and protect the infrastructure. The architect should design countermeasures for different types of attacks such as unauthorized user access, data loss, hacking, malware, and many others. It is worth mentioning this role here because it is vital to the organization but will not always be a part of the typical SOC unless you are an MSSP. In many MSSPs, you will indeed find or should find security architects in the SOC. This does not mean that architects cannot be a part of the SOC but they are typically part of a larger security organization and will work along with the SOC to identify areas of weakness or areas that need improvement. These architects need to be responsible for understanding industry standards and best practices and be able to convert those to realistic technical controls. They have to keep up with not only networking trends but also emerging security technology as it relates to your core organizational security needs. They should be able to work effectively to help an organization design, size, and scale security solutions specific to organizational needs on a project by project basis or as part of an overall security strategy. Your architect will know what tools are out there to achieve security goals.
There is too much security technology that can be implemented at an organization to be covered in this one small chapter. Whether it is the access management system, network-based intrusion system, or core information technology infrastructure, you have to understand the size of the overall infrastructure you are protecting in order to make the right decisions on sizing your security solutions to be implemented. Basic example of this is if you plan to implement an access management system, you need to know how many users you have so that you can install the software on the right sized hardware meaning, memory, hard disk drive, as well as processing power, then you need to buy enough licenses to cover all of your users who will be accessing the system.
Read an excerpt
Download the PDF of chapter three to learn more!
In keeping with the same example when we start to look at the structure required to run your SOC, we also need to know what the expectations are for the SOC in utilizing the implemented organizational security infrastructure. The requirements for your SOC will be very different if your access management system is fully automated opposed to a system where the SOC will be managing access grants and revocations from the system. You also have to consider if the access management system will talk to other systems such as sending logs to an SIEM infrastructure. So, for each IT system implemented in your organization, you need to have an honest and open discussion about what needs to be protected how it is to be protected and what the expectations are for the SOC in protecting those systems. For some companies, this is a standard risk assessment. In many cases, there may be systems where the SOC may not be directly responsible for managing such as a web server, but there may be very real and specific requirements for the SOC to protect that web server from intrusions. Different organizations will employ different technologies for this purpose, all depending on the risk assessment of that device and the organizations desire to protect it. This could mean the implementation of application layer firewalls all the way to just collecting logs in a centralized log management system. But you do not need to boil the ocean when looking at your organizational infrastructure and how it is secured before you set up your SOC. You do, however, need to create a positive forum in your environment in which information technology, security, and business representatives can openly discuss what needs to be protected and what the risks are to an organization compared with the level of security currently being provided for a specific asset. Once you get a good idea about the entire organizational security infrastructure that needs to be either managed, control or utilized by your SOC can you then start to think about what is needed for your SOC in order to perform the job. Even if you think you have everything covered and you were correctly sized in your environment you still need to make sure that you allow enough capacity to grow. You want to make sure that as you develop your security infrastructure you are flexible enough to scale up or even down depending on your company or organizational needs and financial condition.
SIEM/LOG MANAGEMENT
There are a ton of papers and books written on the topic of SIEM or just security event management, whichever you choose to call it. There are also a ton of papers and books written about log management. Since both are very heavily covered topics there is no real reason to cover them in-depth in this book except for the fact that they are critical and extremely functional components to a SOC and deserve a review.
Years ago when the function of security was really just starting out people who were trying to protect a network from hackers would build a basic IDS or a file integrity checker. They would build this system, get it up and running, connect it to the right part of the network, and watch it like a hawk. Their eyes would be glued to the screen waiting for something to happen and then pounce on every alert like a cat chasing a mouse. After a while, it tends to get boring or you have to install several systems on different parts of your network and the review of the information gets very tedious. I am talking about a time when we did not have fancy graphical interfaces and webpages to look at. Everything was command line and stored in files. When you have several different systems, going back and forth to each system looking for events and chasing down potential issues becomes difficult and very time consuming. To help resolve these issues programs were created to generate emails when changes were detected. Similar to the way email groups worked these messages could be sent for every alert or digest versions could be sent once a day. This helped make things a bit more manageable but there was just too much information to consume. Now, fast forward time to today where we have more advanced systems each with their own graphical interface, dashboards, and charts along with raw data visualizers, all viewed as a web page or inside a custom application, it does not make things any easier. Although these systems have come a long way to provide better value in managing their data and events, a typical security infrastructure can employ hundreds of different types of security systems, and thousands of rules that all generate an amazing number of events 24 h a day. To really manage these events properly you need to be able to prioritize and address as many of the most critical ones as close to near real time as possible. SIEM tools have really helped in this area. By creating a system that can consume events from hundreds of different types of devices and systems and then build rules around those events, the SIEM has become what is known as a force multiplier, meaning it can make a few people do the job of many. By collecting all these events and building rules around them, you can really ensure that your SOC works what you want as a priority and stays on top of events. The SIEM can handle reporting to your ticket system and even perform any additional communication or notifications you need. Today, a SOC that operates without some kind of a SIEM tool is seriously handicapped. A SIEM tool is one of the best ways to utilize security intelligence data to proactively monitor for suspicious indications of threats. Additionally a SIEM tool is going to be able to provide you a significant ability in metrics reporting and security analytics that may be required to not only spot problem areas but to also provide reports to management. I am not saying that every organization needs to go out and buy their SOC the best tool money can afford, and there are even some low cost if not free ones out there, you can definitely find champagne on a beer budget, but to not aggregate and collect events from your security tools into a central repository that has been built with your organizations workflow, priorities, and objectives in mind will significantly reduce the efficiency of your SOC and reduce the effectiveness of your overall security strategy.
Log management is a bit of a different story and I want to separate it out from SIEM because they are really two entirely different things. Some people believe or understand log management and SIEM to be relatively the same but they are really not and should not be considered the same in any way. I would like to place a clear definition on each for the purpose of how a SOC and your organization should view these systems.
SIEM should be considered as a system that is capable of the short-term collection and storage of security-relevant data and information that has functions and controls to aggregate like events, correlate multiple events in a series or chain in order to build new security-relevant events to be investigated by trained security personnel. High speed and performance are going to be your two primary concerns for the hardware running your SIEM solution.
Log management should be considered as a system that is capable of the longterm protected collection and storage of complete raw event data that has advanced search and reporting capabilities for auditors to ensure compliance with organizational controls and for security personnel to perform forensic and historical research. Large storage and backup capabilities are going to be your areas of focus for your log management solution.
All too often I see organizations trying to use a log management system to perform the tasks that a SIEM was created to do and vice versa. This does not mean that the two types of systems do not have similar capabilities but they will usually approach the problems from different perspectives. A system that is designed to evaluate events against hundreds of rules at high speeds will be a very expensive system to use as a log aggregation repository. A log management solution should be able to store logs at a much cheaper cost.
Let us look at a typical scenario where this difference can be expressed. When a hacker attacks a server, there can be hundreds of unique requests to that server being made and can typically be very noisy as far as the volume of events. In a log management system, this noise can be very difficult to see with thousands of other logs all being collected at the same time. With a SIEM tool, rules can be created to see this type of activity automatically and create a single new alert that notifies your SOC that a potential attack is in progress. A more difficult example of this may be an attacker who tries to disguise a server attack by initiating requests very slowly and waiting long amounts of time between attack requests. In this case, reviewing a single day or week's worth of logs may not show you any recognizable trends, like a needle in the haystack. But with the right rules and properly trained SOC staff, they will be able to recognize these trends when they are analyzed over a week, or month inside a SIEM. The attackers source IP address may even be automatically captured by the SIEM tool immediately upon the first detected event and then as the attacker gets more aggressive or performs other threat-based events the system will automatically raise the criticality of what that IP address is doing on the network to raise the awareness, whereas the log management system will just simply collect all the events.
I do not want to diminish the needs of collecting logs at all, it is a vital part of any complete and robust security operation. You must be able to collect the right data in your logs, monitor for anomalies and store them for a reasonable amount of time. Not only do logs need to be collected they also need to be protected especially if an attacker is able to compromise a server. A log management system serves a great purpose as it gives you the ability to move log files off of a system so that an attacker who wishes to cover their tracks cannot alter those logs. This goes well beyond setting permissions on a system log or encrypting the logs, it takes them well out of reach by ensuring they are safe on a completely separate system. Most all servers and systems today provide some kind of log or Syslog capability and these logs are what tell you something has gone wrong. The logs, regardless of how or if you collect them will tell you very important information, if configured correctly. They can tell you when suspicious activities have occurred and that something requires further investigation, they can also tell you what an attacker is doing by recording their commands or actions. Last but not least, your logs can become the subject of legal proceedings and therefore should be captured and stored in a safe and sound place. Most larger organizations will have audit departments that will work with a SOC and will help provide guidance on what reporting they need, how long to store the logs and what kind of storage system is acceptable from a legal perspective.
SIEM and log management can become a very expensive, systems can generate a ton of logs and these logs take up huge amounts of storage. For larger systems, this could be billions of events per day and when designing a system, it is very easy to under estimate the space that would be required to keep these systems running. Typically auditors and regulators like to see storage of specific logs for a year or more, when looking at the storage needs for billions of daily events over the course of a year the storage will get expensive. A log management system will understand the long-term storage needs and will be able to address that with data compression and other interesting and inexpensive ways to achieve your goals. The storage needs can fluctuate depending on what you are doing and what investigations you are performing, for example, you may decide to pump up the log detail on a specific device to get more information temporarily, this can easily become a concern for storage. Administrators of these systems have to closely monitor the size of the storage systems in the log management and SIEM environments to ensure they continue to operate properly. It is also worthwhile to note that as an organization grows systems, servers and networking equipment being used in an organization can grow in numbers or drastically increase in event rates, you need to take that into account and plan for storage growth in these tools and consistently revisit those plans. To help combat increasing log sizes and running out of storage, your SOC should work with your organization and auditors if you have them, to level set what is actually needed, and what can be removed from being captured in the logs. What is relevant and what can be eliminated are important items to review as some types of network devices and servers will allow you to select what types of events get logged and have the capability to turn off what you do not want. By eliminating what you do not need will help you store those important events at a lower cost. Do not just collect everything, make sure that your SOC, engineering, and management work together to ensure you get what you need.
OPERATION CENTER INFRASTRUCTURE
TICKETING SYSTEMS
An issue tracking system or ticket system is a vital part of your operation center. You need to be able to create, update, and resolve reported issues as well as track work progress. Just using a single security tool in your infrastructure may not be sufficient to properly analyze an event, though using all of the tools you have available combined to effectively monitor the network will empower the analyst to be successful. Each analyst over time will develop his or her own style of monitoring. Using a ticketing system will allow for a central repository of all notes and data used to perform each events analysis. This will not specifically instruct an analyst on how to do a particular job but help contribute to a better understanding of work flow and best practices and will allow others to follow behind them, read their notes, and validate their findings.
A ticket system can often also contain a knowledge base containing information on resolutions to common problems or may even have indicators about what true positive event looks like opposed to a false positive and can include ticket numbers that were previously solved as actual references. Consistent use of a ticket tracking system is considered one of the fundamentals of a good operation team. As such, we are going to spend some good time talking about different systems and what are some needed and optional components to your ticketing system for your SOC. This is such a vital resource to the SOC that you need to spend some good time thinking about what the requirements are before you implement anything. You need to know what the SOC team members will need and what kind of metrics you would like to get out of the system.
One of the primary features of a ticket system that you should look at is its ability to capture analyst's notes. This is critical as you analyze events, you need to make sure that notes are properly captured, time stamped, and easy to follow. The flow of notes can be cumbersome, you need to make sure you know what works for you. One time I worked in a SOC that had a ticket system that took me forever to find notes, they were buried somewhere and you could only see one note at a time. So I had to open the note, see if it was the one I wanted, then close it and open another. Each opened a new screen, it was a huge hassle even after I figured out how it worked. Some systems make you click on every note to see what is written, whereas other system list out all the notes in a very long linier way then there are other systems that have separate notes but as you click on each a text box activates with the information that you can easily see.
If you have a lot of devices in your security infrastructure or are protecting a large device list then it may be important for you to have your ticket system include an asset database to collect information on devices under management or being protected by the SOC. This is optional as this can also be accomplished if your organization already has an asset database so your needs may vary. Having an asset database included in your ticket system may afford you additional automation, workflows or easier access to information customized inside every ticket.
An array of communication methods such as text, email, or SMS text is also a major requirement you should think about with your ticket system so that you can automatically notify people of required actions. Additionally you will want to see what other systems or integrations are possible with your ticket system. For example, maybe your ticket system can automatically communicate with a change database or asset database. This will help you deconflict issues that arise looking like a security problem but is really an authorized change. There may be many different types of communication integrations possible with your ticket system so spend some time evaluating the possibilities as this will only extend your capabilities and improve the performance of your SOC.
A good basic ticket system will allow team members to create new entries that are individually numbered for easy tracing, and then allow the members of the SOC to make free form text entries regarding a specific case, events, or issue. The ticket system should track who made the entry, what time and date the entry was made and allow for different ticket statuses. Ticket statuses can be as simple and as basic as open or closed but can be also be very complex and detailed such as "waiting for system administrator call back" or "escalated to management".
Event analysis/investigation is a time-sensitive process and crucial information can be flushed or overwritten from security devices or sensors lacking large storage devices. if the processes take too long to retrieve the information you need. No matter what, you are going to work against the clock if you are under attack and you want to reduce the impact of that attack. Quickly reacting to threats and attacks may allow you to get an intrusion prevention block in place or shut down a system to prevent the spread or escalation of an attack. The SOC needs to always perform work quickly, but not hastily. They should not have to think about the current process and what the next steps should be, the ticket systems and workflows should be there to support them. In order to make your ticketing system work best for you, think about your events and what problems or malicious activities might cause a certain set of system alerts to be ticketed, then build your ticketing system to match those events and the workflow you will need to be the best at effective analysis, communication and ultimate conclusion of those events your SOC will address.
When an analyst has used all of the security tools available to them and determined that an incident has occurred or further validation is needed, entering information into a ticket should always be the next feasible step an analyst will need to do. It is crucial that all of the information available is put in the event ticket that was generated or created and the information should be in great detail. Capture all of the logs, screen shots, and network flows as possible during the investigation and include it in the ticket. There should be no issue with information overload inside your ticketing system. The robust information you include in each and every ticket will only help when more than one person in the SOC gets assigned to work a ticket so that everyone can better understand what the original analyst was seeing or what they are basing decisions on. You should also consider that tickets may need to be reviewed hours, days, or even months after an incident and it can be difficult to remember all the gory details, good data in your ticket will help. Multiple people working a ticket is common as this can happen for example, if an event gets created during first shift and another analyst picks up and works the event on second shift. Or if an analyst needs to escalate a ticket to a more senior person such as an engineer, that second person who gets the escalation should not have to redo all the original research as all the required information needs to be in the ticket.
You should also consider using the concept of queues. This will allow you to split up your tickets into different areas for either team focus or organization. For example, you may want a general queue where all tickets get automatically created or created by your tier-1 analysts. Next you may want a separate engineering queue, this is where your analysts can place existing tickets that need the attention of the engineering team. This type of queuing will allow different teams to focus and see only the tickets they are concerned about and remove extra information and noise that they do not.






