
JRB - Fotolia
Network monitoring systems best practices include centralized data
With the help of a centralized data store and modeling language, network monitoring systems can both separate and unify data collection and analysis functions.

In my last article on network management design and network monitoring systems, I adapted the carpentry maxim: Measure twice, cut once. But, in networking, I would say: Measure many times, never cut.
In reality, every time we want to discover something new about the network, we build a new tool that requires us to measure more stuff in more ways. Ultimately, we end up with something that looks like Figure 1 -- see below.
As seen in Figure 1, information is gathered from the network device by several different collectors, some of which retrieve overlapping information. For instance, much of the configuration state can be inferred from the routing state and interface state. Much of the interface state can be inferred from the routing state, and so on.
Each system stores the information in some format specially developed to optimize the collection and analysis of that kind of data. And each system has a separate analysis module to determine if something is wrong with the network device. The operator can use a single pane of glass, or perhaps a single pain of glass, to mentally correlate everything together into a larger picture.
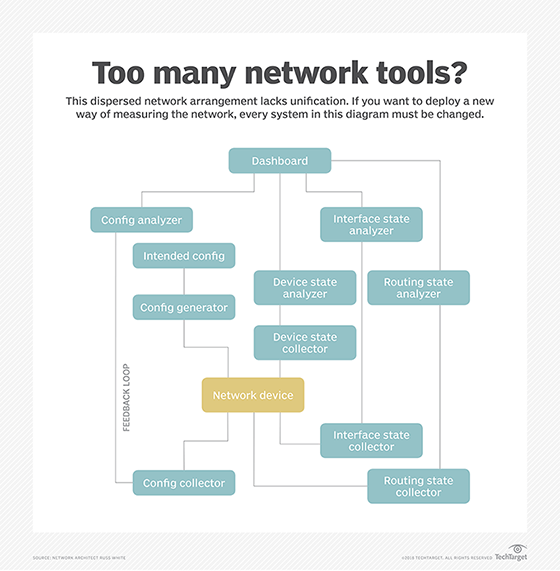
In this mode of operation, DevOps can do much to automate the network configuration and even pull information from multiple systems and correlate them into a unified image of what the network is doing. If you want to deploy a new way of measuring the network, or a new device or a new way of looking at the information, every system in the diagram must be changed.
Is there a better way? There is -- but, fair warning, working toward a better way and achieving best practices for network monitoring requires discipline, planning and patience.
Best practices for reorganizing network monitoring systems
If you consider the IP stack, a wasp waist -- or hourglass-like network design -- is needed. Namely, some centralized component or set of components needs to unify the data collection, analysis and presentation of telemetry. The single pane of glass -- at the top of Figure 1 -- serves this unification purpose in most network monitoring systems today. Although, technically, any real unification takes place in the operator's mind, rather than on the single pane of glass.
What one component could be inserted into this diagram to make this set of systems scale better and produce better results? To answer that question, consider another phenomenon occurring in the network engineering world, namely, the move from command-line interface configurations to programmable interfaces. In particular, Yet Another Next Generation, or YANG, and JavaScript Object Notation, or JSON, are starting to do a lot of heavy lifting.
One crucial point behind this move to programmable interfaces is not so much the standardization of the data itself, but rather the standardization of the way in which data is represented, including the metadata that makes the information accessible.
If you insert a centralized data store into the diagram above, with all the information passing through that store marshaled through a fully marked-up modeling language, such as YANG, the diagram looks much different, as seen here in Figure 2.
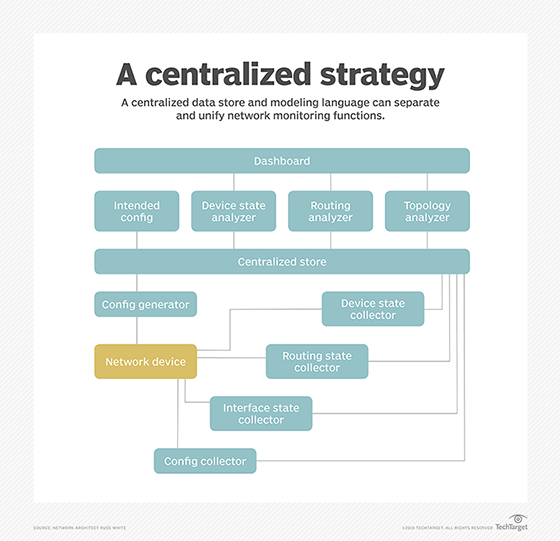
With a centralized data store, you can separate the collection functions from the analysis functions. This allows both functions to be more agile to current needs. Deploying a new piece of network gear means understanding how to gather and marshal the information needed. Creating a new analysis unit becomes a matter of thinking of new ways to analyze existing data, or perhaps gather incremental data that's not already being collected.
The bottom line is: Think about telemetry systems as systems, rather than a collection of disparate tools. By breaking network monitoring systems into layers of collectors, data storage and analysis, you can break the logjam of network management, empower DevOps and revolutionize the way networks are operated. These kinds of tools and best practices for network monitoring have been promised for years, but the pieces are starting to come together to make them a reality.
Dig Deeper on Network management and monitoring
-
![]()
Pure Storage hands channel fresh data management pitch
-
![]()
Podcast: How customers use multi-cloud and mitigate key challenges
By: Antony Adshead
-
![]()
CWDN series: Dev-eXperience – Cockroach Labs: Building for the 99% in day 2
By: Adrian Bridgwater
-
![]()
3 ways to troubleshoot using Wireshark and tcpdump
By: Damon Garn



