NOC best practices include using standardized network designs and automation. But don't forget to identify performance metrics that help track and measure operational success.
Top-performing network operations teams rely on best practices and KPIs to drive improvements in network operations.
Network teams can gauge how efficient their network operations centers are by evaluating the NOC best practices and performance metrics below and identifying areas for improvements.
NOC best practices
Standardized network designs
The most important best practice for network operations is to use simple, standardized network designs to the greatest extent possible. Remote branches should use similar designs, with only slight variations to handle different sizes or specific requirements. The same strategy applies to larger offices and data centers. Using standard building-block designs simplifies the entire system lifecycle from procurement through installation to operations. Teams can also reduce policies, configurations, operations, monitoring and troubleshooting to standard procedures, which automation can further simplify.
Network redundancy
Network architecture must incorporate the right level of redundancy to make the network resilient to failure. Failures will occur -- links will break and devices will fail -- and teams must design the network to gracefully handle those failures. As an added redundancy benefit, top-performing network teams can perform maintenance and upgrades on parts of the network without affecting the business. This creates a much less stressful environment and enables the network to keep up with changes in applications and supporting IT systems.
Comprehensive network management
Top-performing organizations use network management systems to provide an overall view of the network, supporting proactive handling of problems before they affect the business. Teams can act on failure and brownout reports in a timely manner to prevent a subsequent component failure from affecting the business. A comprehensive network management architecture is required to provide the required level of visibility.
Automation and ChatOps
Automation of common tasks is another best practice. These tasks include provisioning, performing network equipment OS upgrades -- to address bugs or security holes -- and modifying configurations. Machine learning tools, such as Moogsoft, Splunk and Elastic, can greatly enhance event management by consolidating and correlating large numbers of events into a few actionable items. Organizations can use automation to regularly verify network operations and augment troubleshooting processes.
A more recent addition to network teams is the use of ChatOps to streamline staff communications, trouble ticketing and incident resolution.
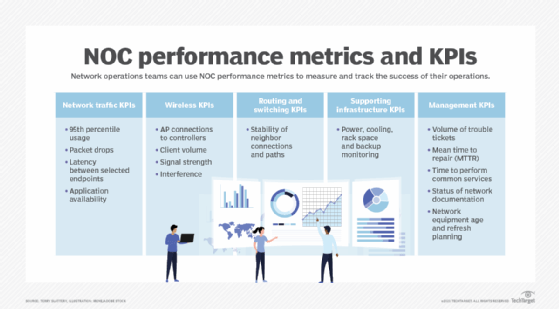
NOC performance metrics and KPIs
KPI dashboards are key to helping network operations teams measure their success and identify where to focus improvements. The specific KPIs teams use depend on business functions and the supporting network. Data centers, cloud, SaaS, remote sites, wireless, internet connectivity, call centers and others have both common KPIs and unique KPIs.
Common metrics include network traffic statistics, like 95th percentile usage, packet drops, errors and latency between selected endpoints. Network availability is tricky to define and measure, so it's often easier to measure application availability and performance using tools like digital experience monitoring.
Unique metrics depend on the underlying network technology. Wireless network KPIs track access point connections to controllers, client volume, signal strength and interference. Routing and switching -- with Spanning Tree -- use KPIs to measure the stability of neighbor connections and paths.
Less obvious metrics include monitoring the elements of supporting infrastructure, like power, cooling, rack space and coverage of system backups. Teams don't want to unexpectedly run out of supporting resources, nor do they want to find that saved network device configurations are not usable.
Top-performing NOC teams use KPIs to measure and improve the network and their ability to run it, not to assign blame.
There are also management KPIs, such as the following:
the volume of trouble tickets of a given type or severity;
the mean time to repair, or MTTR, for a class of failures;
the time to perform common services, such as measuring the efficacy of automation;
the status of network documentation; and
network equipment age and refresh planning.
Top-performing NOCs vs. underperforming NOCs
Top-performing NOC teams use KPIs to measure and improve the network and their ability to run it, not to assign blame. The staff are well trained, work together as a team and work well with other IT teams. They employ processes that reduce human error and streamline tasks, preferring tools and automation to make their tasks easier, faster and more consistent.
An underperforming NOC operates in firefighting mode, going from one crisis to another and using manual processes that are seldom documented. They likely don't standardize their network designs where possible, which hampers operations. As a result, the network experiences unexplained outages, has highly variable times for problem remediation, is difficult to automate and has a poor reputation.
Making the transition
It's possible for teams to transition from an underperforming NOC to a top-performing one by taking the following steps:
Start by implementing standard network building blocks.
Examine the current network management tool suite, and identify key metrics to track.
Develop and document processes for common operations, and incorporate automation to reduce human error and the time to perform those operations.
It is best if teams have management support to make these changes. Even if such support doesn't exist, however, teams should be able to make small changes that don't cost anything and that result in better performance for the team and the network.