How to tackle network automation challenges and risks
Automation makes networks more efficient, but engineers must first mitigate the risks. With planning and training, enterprises can take advantage of automation's capabilities.
Many network engineers and managers are still reluctant to deploy network automation. One major concern is that automation can disrupt network operations.
Anyone who has run a network for a reasonable length of time has likely experienced a major network outage. Outages are stressful and unpleasant, so teams try to avoid circumstances that might cause one. Even simple changes can cause major outages, so it's reasonable to question why teams would consider automating the process. A bad configuration could wreak havoc across an entire network.
To that end, if automation causes a broken network, teams likely won't consider the technology as the answer. Instead, the go-to remediation tool is typically the CLI, which teams use to configure one device at a time. However, this method has a major drawback: it's time-consuming.
For example, if a team updates 100 devices, with a minute per configuration, the changes will take over an hour and a half. Multiply that time by the number of minutes the process actually takes and by the number of devices that need correction. With the amount of time and devices, it's easy to see why managers might shy away from using automation if they fear a glitch would damage the network.
But do network automation risks really outweigh the benefits? Can teams mitigate those challenges and risks? To start, let's examine why enterprises need to use network automation and the risks of not adopting it.
Why teams should use network automation
Network automation provides several advantages for enterprises.
Standardized designs, not snowflakes
Complex network designs, or snowflake designs, add risk because one part of the network is configured differently than another part. The lack of standards increases the risk of changes in each part of the network. Standardization is important simply because the network deals with fewer or no special cases. It can better determine failure modes and develop standard procedures to handle them.
Standardized building blocks for network designs simplifies automation because they are easier to automate. Automation assistance includes initial configuration, configuration updates, physical connectivity validation and troubleshooting. Equipment might cost a little more for building-block designs, but the tradeoffs are reduced Opex and greater resilience. By using standard operating procedures for troubleshooting and remediation, teams can more easily understand and mitigate failures.
Network agility
Network automation has lagged automation technologies that underpin compute and storage systems, but it's catching up. Companies that delay complete IT automation adoption face the risk of losing out to their more agile competition.
Automation means the entire organization's use of IT resources is more efficient. Efficiency enables organizations to reap greater productivity and profits with the same number of employees. A more stable IT environment means more stability for customers and greater customer satisfaction. In many cases, this translates to higher prices and larger market share.
Agile networks also adapt more easily to new network technologies. To integrate new technology, network teams only need to make incremental changes to a few building-block designs and associated automation tasks.
Network automation challenges
Modern network engineering is full of technical, operational and organizational challenges. As businesses adopt cloud computing, containerization and network automation, engineers face numerous obstacles that demand both innovation and adaptation.
Technical challenges
Below are some common technical challenges associated with network automation.
Writing unit tests for code. Writing Python code for network devices or Golang code for a container network interface (CNI) in a Kubernetes cluster is one thing. Unit testing the code is another. Testing code is as important as translating business requirements into code. Network engineers struggle with writing unit tests because it takes a lot of time and extra skill to learn a new library.
No real-time mapping of IP addresses to services. In Kubernetes networking clusters, this issue occurs because some CNI tools don't support defining a static IP address. As a result, services can frequently change IP addresses due to downtime or scaling in the cluster. Constant swapping makes maintaining an up-to-date service registry difficult and can cause service-to-service communication failure when they come back up. DNS, which resolves hostnames to IP addresses, doesn't work here.
Lack of ease of scalability. When running cloud workloads, each cloud provider has its service mesh tool for service discovery. To that end, managing consistent network automation configuration across these clouds becomes a problem.
Pinpointing Layer 7 failures. Modern applications require an understanding of application protocols running at Layer 7 of the OSI model. Native network automation features in Kubernetes, for example, cannot currently work at this layer.
Operational challenges
Lack of centralized visibility is the most prominent operational challenge.Network teams are segmented to either handle network devices or microservice networking. But the lack of centralized visibility is a huge challenge. For example, a company can have Kubernetes resources across multiple clusters. Not being able to easily visualize a network policy's influence across the cluster hamstrings operations.
Organizational challenges
Organizational challenges, such as learning new technologies and skills, give many network managers pause. Early on, the shift to using Python for automating network devices came as a shock, but network engineers are adjusting.
Now, increased cloud adoption adds a new wrinkle. Network managers are asking engineers to set up cloud connections and migrate workloads there as well as set up communication between these cloud-based microservices. These demands fuel a skills crunch for network engineers.
Network automation risks
Automation is best rolled out by beginning with simple tasks. Adopting automation isn't without its own risks, however. Any ill-prepared and poorly implemented process can break the network, and automation is no exception.
Here are some points network teams can consider reducing network automation risks.
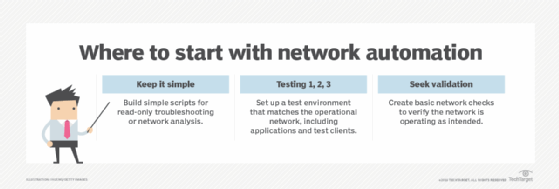
Start small and simple
Begin by building simple scripts that perform basic, read-only troubleshooting or network analysis. Some examples are tracking down a media access control address, finding the root bridge in a spanning tree domain or viewing a pod's ingress network policy. Automate frequently used and time-consuming investigative or diagnostic tasks. Don't make any automatic changes at this stage. Instead, focus on learning the automation tools that provide real value to network operations.
Testing
Network automation needs to rely on the same extensive testing process used with application development. Application developers can quickly bring up server and client testing VMs and automatically run extensive analyses.
In contrast, network testing has historically been problematic. Test labs were too expensive and time-consuming to set up, but building-block designs reduce variations that need testing. Vendors also offer virtual instances of many device types at little or no charge but with limited performance. Thus, it's important to verify configuration changes on these devices.
Network teams and the rest of IT might need to collaborate to create an accurate test environment of the operational network. Ideally, the test environment includes applications and test clients to generate network traffic. One example is Containerlab.
Network validation
Verifying the network state is a great way to reduce automation risks. Verification is also a helpful tool to validate that a network is functioning as intended, even before adopting automated change.
Adopting automation isn't without its own risks. Any ill-prepared and poorly implemented process can break the network, and automation is no exception.
To validate network connection and operation, consider the network state. This includes device interface state, address assignment and neighboring devices as well as Layer 2 and 3 protocol information. In this phase, there are no changes to the network. The intent-based validation script should create an alert when a check fails, enabling teams to take appropriate action.
Network validation scripts become tools for a future change process to perform pre- and post-change network validation checks. If any pre-change validation check fails, abort the change. Similarly, if a post-validation check fails, alert the network staff and potentially back out of the change. Repeat the pre-change validation after reversing it to make sure the network returns to the pre-change state.
Making it work
The most important concept with any network change system is to adopt processes that reduce risk. Manual changes use change control boards and review cycles, and these processes are still necessary. But automation adds additional processes, such as pre- and post-change automated validation or coordinating microservices in network architectures.
Below are a few other ways to address existing network automation challenges.
Technical approaches
Use automation libraries. Learn to use libraries like pyATS, Pytest and Moto to write more unit tests for code. Carefully read the documentation and contribute back when possible.
Service mesh. Use service mesh tools to improve service-to-service communication. A service mesh tool, such as AWS App Mesh, Consul, Cilium, Istio or Linkerd, can abstract this communication's complexity by providing a service discovery feature. Vendor-neutral service meshes can also help with easy integration across multiple clouds.
Operational approach
Network managers can gain the visibility they need to effectively manage the complexity of environments by implementing centralized monitoring and observability. Tools like Prometheus, Grafana and DataDog are popular in Kubernetes environments. When dealing with hardware network devices, ThousandEyes, Splunk and similar competitors are viable options.
Organizational approaches
Ease resistance to change. Some teams might hesitate to automate their networks because of concerns about complexity or disruption to existing workflows. To overcome this, clearly communicate the benefits of automation, such as improved reliability, better scalability and reduced manual effort. Involve stakeholders in the planning process. Suggest tech conferences around network automation to attend.
Break down siloed teams. Network, DevOps and application teams often work in isolation, making it difficult to coordinate network automation efforts. Break down these silos by fostering cross-functional collaboration and establishing clear ownership and responsibilities for network automation.
When starting with automation, limit work to simple tasks that won't affect the network. Get started with network automation now.
Editor's note: This article was originally written by Terry Slattery. It was updated and expanded by Charles Uneze to reflect industry changes.
Charles Uneze is a technical writer who specializes in cloud-native networking, Kubernetes and open source.
Terry Slattery is an independent consultant who specializes in network management and network automation. He founded Netcordia and invented NetMRI, a network analysis appliance that provides visibility into the issues and complexity of modern router- and switch-based IP networks.