
Alex - stock.adobe.com
How to ensure network performance and reliability
Network reliability is critical to network performance. Network administrators should follow reliability best practices to understand how to build and maintain reliable networks.

Network reliability is critical to networking. Reliability ensures minimal disruption, which is essential for businesses to avoid financial losses and reduced productivity.
This article discusses best practices for maintaining network reliability and improving performance, including network protocols, performance optimization strategies, quality of service (QoS), microservices and configuration tools. Network professionals can follow these guidelines to avoid network downtime and mitigate poor performance.
Use network protocols to ensure reliability
Network protocols, a critical component of network communication, are essential to maintaining network reliability. Network protocols establish rules that define how data transmits over a network. These rules enable devices to communicate and exchange information efficiently within a network.
Key network protocols that safeguard reliability include the following:
- First Hop Redundancy Protocol (FHRP).
- Open Shortest Path First (OSPF).
- Border Gateway Protocol (BGP).
First Hop Redundancy Protocol
Redundancy involves adding an extra mechanism that acts as a backup in case of failure. It's critical to determine if the point of failure is a low-risk or high-risk point in the network.
FHRP provides redundancy by automatically rerouting traffic to a backup device when a failure occurs. It has vendor-specific implementations and non-vendor implementations, such as Virtual Router Redundancy Protocol (VRRP).
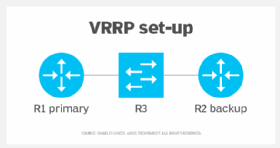
VRRP is configured on the interface of the primary and backup devices. The primary and backup devices share a virtual IP address. The primary device typically handles traffic. However, if the primary device fails, VRRP reassigns the virtual IP address and reroutes traffic to the backup device. When the primary device recovers, it takes over from the backup and resumes its role.
If VRRP is on a Layer 3 switch in a data center network, consider the Spanning Tree Protocol (STP) configuration. The VRRP primary switch should function as the STP root switch to maintain network stability. Additionally, object tracking monitors the state of non-VRRP interfaces. The backup device takes over if it goes down, which further enhances reliability.
Open Shortest Path First
OSPF can quickly detect failures on a router's link and recalculate optimal routes with the Shortest Path First algorithm. It then advertises these routes to all neighboring OSPF routers with a link state advertisement (LSA) packet.
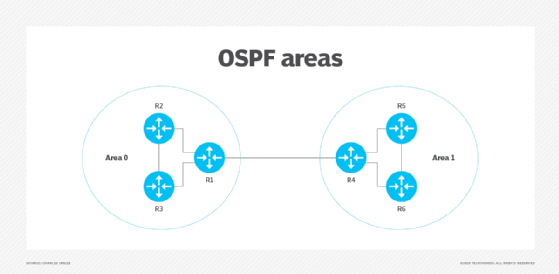
However, OSPF can have scalability challenges. Routers dedicate bandwidth as they flood LSA packets and recalculate routes, which strains the router's CPU. In a large enterprise network with hundreds of routers, one topology change -- such as a link failure -- could trigger an LSA flood and cause each router to recalculate routes. To fix this issue, group routers into OSPF areas to reduce unnecessary updates.
Border Gateway Protocol
BGP is the backbone of internet routing. Network professionals can group routers and place them in a common administrative control and routing policy to form an autonomous system (AS). Each AS, typically managed by an ISP, has a unique number. These unique numbers, or ASNs, enable multiple ASes to interconnect and maintain routing control.
A best practice when configuring BGP is to form a BGP neighborship within an AS with a loopback interface rather than a physical one.
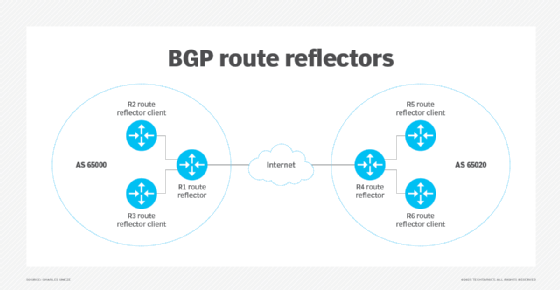
However, BGP has a scalability issue: All routers must form BGP neighborships between themselves. Techniques that can help with this issue are the following:
- Route reflectors. A designated router forms neighborships and reflects routes to other routers. For example, instead of having three routers that need three connections, a route reflector reduces this to two connections.
- BGP confederations. Network professionals can divide a large AS into smaller sub-ASes, known as a BGP confederation, to make routing more manageable. An ISP can do this on a wider scale by dividing a continent-wide network into regional sub-ASes to simplify routing.
Network performance optimization strategies
In addition to improving performance, network performance optimization strategies can also ensure reliability. Examples of strategies that can enhance network performance include the following:
- Bidirectional Forwarding Detection (BFD).
- Route summarization.
- Load sharing.
Bidirectional Forwarding Detection
OSPF sets a default dead time interval at 40 seconds, which means a router must wait that long before it can declare a neighbor is offline. Network professionals can reduce this interval to one second to improve failure detection and significantly increase CPU load. The control plane must process frequent HELLO packets, update the neighbor table and constantly recalculate routes.
However, BFD works with routing protocols and achieves subsecond failure detection as low as 50 milliseconds without overwhelming the CPU. BFD runs at the data plane level and offloads failure detection to dedicated hardware, which enables the hardware to respond quickly without excessive computation.
Route summarization
Route summarization takes different interface addresses on a device and summarizes them into a single prefix. It then advertises this summary to a device in another part of the network, such as the OSPF area, BGP AS or data center layer.
Route summarization eases performance because it reduces the size of the routing table. When a device failure leads to route recalculation, it minimizes the router's CPU load. Summarization reduces the number of individual route updates the router needs to process.
Route summarization also ensures reliability and improves performance by summarizing multiple routes. However, it can create routing loops. To prevent this, preserve the AS path attribute. For example, if AS 65001 summarizes a route and AS 65002 advertises it back, AS 65001 can detect its own AS in the AS_PATH and reject it.
Load sharing
Load sharing ensures that traffic can use multiple exit points simultaneously. This differs from VRRP, which uses one exit point device until it fails.
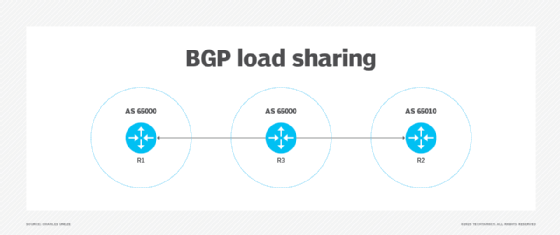
Load sharing is only possible in BGP when BGP multipath is enabled. This feature installs multiple equal-cost BGP routes into the routing table. OSPF uses the same practice when several destination interface costs are equal.
Quality of service
QoS ensures network reliability and improves performance by managing congestion and prioritizing critical traffic. QoS techniques that manage congestion include the following:
- Queue management.
- Traffic shaping.
- Bandwidth policing.
Queue management
Queue management optimizes traffic flow during congestion by buffering some traffic and allowing others to flow. Many queuing types exist, such as low latency queuing, which prioritizes real-time traffic -- such as VoIP -- over others.
Traffic shaping
Traffic shaping regulates traffic by buffering excess packets and releasing them at a controlled rate. This prevents sudden traffic spikes that could overwhelm routers.
To verify if a QoS policy functions correctly, use Wireshark's I/O Graphs to visualize traffic patterns and identify any anomalies, such as packet drops and latency spikes.
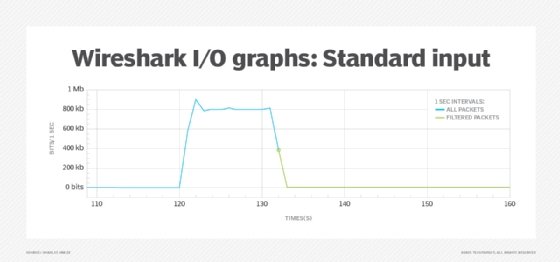
Figure 5 simulates shaping in a virtual lab. Set the throughput limit to 800 kbps on a router. This is a low throughput; in a real environment, expect something higher. Next, perform an iPerf throughput test between two end devices with a bandwidth of over 800 kbps. Finally, use Wireshark packet capture filtering for iPerf packets.
After the initial traffic spike just after 120s, it stabilizes at around 800 kbps. This suggests the QoS policy actively controls the traffic flow.
Bandwidth policing
Bandwidth policing enforces bandwidth limitations and drops or re-marks packets exceeding that limit. Bandwidth policing doesn't enable buffering.
For example, an ISP might charge extra for exceeding an internet link order over 100 Mbps. To avoid incurring extra charges, configure policing to strictly enforce the 100 Mbps cap.
Microservices
Microservices rely on fast and stable networks for communication. Common issues leading to an unreliable network with low performance include undetected failures, uncontrolled IP address allocation and high latency. Ways to improve reliability and performance include the following.
- Monitor workloads.
- Control IP address allocation with quotas.
- Optimize network interface cards (NICs) in cloud deployments.
Monitor workloads
Metrics, logs and traces can give teams a complete picture of the entire network when troubleshooting. Metrics offer insight into the health and performance of the network and its applications. Logs chronicle these events to provide a detailed history of when events occur, analyze past activity, and identify and predict future network behavior. Traces track data flow across the network to ensure data can be transmitted between devices properly.
Control IP address allocation
In large-scale Kubernetes deployments, uncontrolled IP address allocation leads to exhaustion. Without available IP addresses, teams can't schedule new pods, network communication breaks down and critical services fail. This ultimately reduces the reliability and performance of the entire cluster.
To remedy this, use IPv6 if the cluster supports it. If it doesn't, use an IPv4 /8 prefix like 10.0.0.0/8. If the network uses a Container Network Interface (CNI) like Calico or Cilium, control the IP address allocation by defining specific IP address ranges per node in a cluster.
Optimize cloud VM NICs
In a multinode Kubernetes cluster, microservices running on the nodes (cloud VM) frequently exchange data. Without high-performance networking, each packet passes through the hypervisor, which increases latency.
If network administrators have a VM that supports an enhanced networking capability like Single Root I/O Virtualization, they can use it to improve performance. With this feature, packets bypass the hypervisor and flow directly between the NIC and the VM.
Configuration tools and troubleshooting techniques
Certain tools will come in handy when network administrators deal with network reliability and performance issues. Useful network troubleshooting tools include the following:
- Ipconfig and ifconfig. These tools are usually on end devices, such as laptops and PCs, with a CLI. Once they set up internet access and configure an end device interface and default gateway, network administrators can use ipconfig and ifconfig to verify configurations.
- Ping. A CLI tool that can test packet reachability in the network.
- Wireshark. A packet capture tool that can capture packets as they traverse the wire.
Charles Uneze is a technical writer who specializes in cloud-native networking, Kubernetes and open source.







