4 phases to build a network automation architecture
The implementation of a network automation architecture involves several elements, including a core orchestration engine, assorted databases and proper network testing.
Most network managers are interested in network automation because automating repetitive tasks like device provisioning and configuration management lets them focus on strategic initiatives. But how should they plan their network automation architecture, and which elements should be tackled first? The trick is to create an architecture that's independent of any commercial or open source product.
A network automation architecture provides the scalability and resilience needed to adapt to the network's evolving demands. This article presents an architecture and suggests an order for implementing the elements.
Start with a set of requirements that reflect architectural functions, such as the automation engine and telemetry system. Each function has inputs and outputs that determine how the various elements interact. Then follow a phased approach that increases automation capabilities as the new technology and processes in the preceding phase are integrated and adopted.
The architectural functions and phases
Like so much else in life, most network automation implementations follow a "crawl, walk, run, fly" progression. The early phases provide basic capabilities to perform read-only operations on network devices, while later phases modify device configurations. The final phases automate complete processes, including tests on virtual instances of the production network before the final rollout. Some functions might be moved to other phases to match the organization's needs.
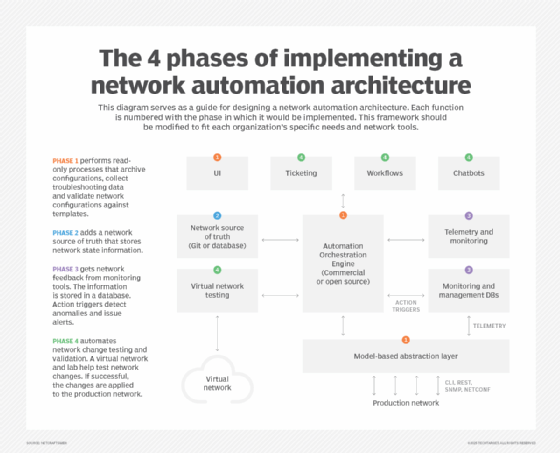
Phase 1. Start read-only processes
Phase 1 provides basic functionalities to view data without modifying the network device's underlying configurations. This phase starts with automated read-only processes that archive configurations, collect troubleshooting data and validate network configurations against templates.
Elements in Phase 1 include the following:
- Automation orchestration. This is the core orchestration engine. It controls how tasks are executed (e.g., scheduling data collection from devices) and includes scaling features like parallel processing and distributed agents. Tool examples include Ansible, SaltStack and commercial platforms like Cisco Network Services Orchestrator.
- UI. Commercial products usually feature a dashboard, API or CLI.
- Abstraction layer. The abstraction layer provides a standardized way to interact with different network device vendors, greatly simplifying the network device interface. It might be built into some orchestration systems.
Phase 2. Add a network source of truth
Phase 2 adds a network source of truth (NSoT) that's tightly integrated with the automation orchestration system to build device configurations from stored templates. Elements in this phase include the following:
- NSoT database or Git repository. The NSoT stores information about the desired network state the automation orchestration system uses to validate -- and, in later stages, correct -- the network's operation. This data might include address assignments, network protocol neighbors, interface operational state and reachability information. This can be stored in the database of a network device or in a Git repository containing infrastructure as code (IaC) YAML definitions, for example. Tool examples include GitLab, GitHub and Nautobot.
Phase 3. Implement network telemetry and monitoring
In this phase, the network provides feedback through telemetry data and monitoring alerts. Up to this point, the network has provided little feedback aside from syntax validation checks when writing configurations that have been input into the NSoT. Elements in Phase 3 include the following:
- Telemetry and monitoring. Historically, network monitoring has relied on the Simple Network Management Protocol (SNMP), but more modern implementations use telemetry data such as logs, metrics and traces. Networks today need to use both mechanisms. Most of the platforms used to collect telemetry data also support a way to send monitoring alerts. An example is the Prometheus Alertmanager, which can send alerts to an email or Slack channel.
- Monitoring and management databases. The monitored data needs to be stored somewhere. Data stores might include a document store database for logs, a time-series database for metrics, a distributed tracing database for traces and a relational database for relationship-type data, such as device type and interface list. Popular open source platforms that support databases to implement network telemetry include the following:
- Prometheus: a metrics platform that uses time-series databases.
- Elasticsearch: a logs platform that uses a document store database.
- Jaegar: a tracing platform that uses a distributed tracing database.
- NetBox: a management platform that uses a relational database.
- Action triggers. Network monitoring is beneficial only if the results drive responses. Action triggers use either rule sets or machine learning to detect anomalies, issue alerts and open trouble tickets. More advanced implementations trigger automated workflows to begin remediation without human intervention, such as routing around a failed link.
Phase 4. Automate change testing and validation
This last phase in the architecture automates change testing and validation. Here's what's involved:
- Virtual network testing. The principal driver of network change control is the practice of testing a change in the lab before deploying it into production. The lab uses virtual, software-simulated devices to model the production network's key parameters. Proposed changes instantiate the virtual network, run pre-change tests to validate the lab is functioning as intended, apply the change and run post-change tests to validate that the desired result was achieved.
- Workflows. Workflows can be triggered by executing scripts -- for example, Python or Ansible playbooks -- that are version-controlled within a Git repository or any source code management system acting as a single source of truth. Commercial products often provide multiple mechanisms to control workflows, including graphical editors and APIs. The most popular workflow for infrastructure automation is GitOps, a subset of DevOps. The following is a typical example of this workflow:
- A GitOps agent from Flux CD, Argo CD or Jenkins watches the Git repo.
- A new network configuration is committed to the Git repo.
- When a change is detected, the agent pulls, tests and applies the configuration using a CI/CD pipeline like Flux CD or Jenkins.
- Routers are configured automatically.
- If a device's configuration drifts from Git, automation corrects it.
- Change validation testing. If the virtual network testing is successful, the change is applied to the production network. The release follows a three-step process:
-
- Validate the pre-change state to ensure all configurations and connections function as intended.
- Apply the change to introduce new configurations or updates.
- Validate the resulting state to confirm that the network is operating smoothly and meets performance expectations.
- Automatic trouble ticketing. An interface to a trouble-ticketing system lets the automation orchestration system create tickets when the network state and the NSoT differ. Remediation is initially manual but becomes increasingly automated as the organization matures. A CI/CD system like GitHub Actions can also be used to open a request for a merge change to the code repository using a feature such as a pull request.
- Chatbots. Tools like GitHub Copilot can assist in reviewing pull requests by generating summaries, suggesting improvements and even automating comments based on predefined criteria. This reduces the burden on developers during code reviews.
The end goal
The network automation architecture described in this article is a framework. Network teams can modify it to fit their organization's needs and accommodate the capabilities of the tools selected.
The eventual goal is to build a continuous integration, continuous delivery and continuous deployment process in which small, well-defined network changes are automatically deployed only after passing stringent tests. This practice, known as NetOps or NetDevOps, enables teams to migrate their network to IaC using many of the same concepts and techniques as successful software development methods.
Editor's note: This article was updated in February 2025 to reflect the latest developments in planning and building network automation architectures.
Charles Uneze is a technical writer who specializes in cloud-native networking, Kubernetes and open source.
Terry Slattery is an independent consultant who specializes in network management and network automation. He founded Netcordia and invented NetMRI, a network analysis appliance that provides visibility into the issues and complexity of modern router- and switch-based IP networks.






