What is fault management?

Fault management is the component of network management that detects, isolates and fixes problems. When properly implemented, fault management keeps connectivity, applications and services running at an optimal level, provides fault tolerance and minimizes downtime. Fault management systems are platforms or tools designed specifically for this purpose.
Faults result from malfunctions or events that interfere with, degrade or obstruct service delivery. Examples of faults include hardware failure, connectivity loss or port status change. Once the fault management platform detects a fault, it notifies the administrator and any additional authorized or designated parties with an alarm or alert.
Many platforms forward alerts via email, text or a mobile app. These notifications are viewable in the fault management system's GUI. Network administrators can also configure fault management systems to automatically fix or prevent certain events using programs and scripts.
Fault management is one component of FCAPS (fault management, configuration, accounting, performance and security), a network management framework established by the International Organization for Standardization.
Fault management functions
Network fault management comprises a variety of functions to keep the network operational. Fault management systems perform the following actions:
- Define thresholds for potential failure conditions.
- Monitor system status and usage levels while scanning for threats, such as viruses and Trojans.
- Provide general diagnostics.
- Control system elements remotely -- including workstations and servers -- from a single location.
- Trace the locations and notify administrators and users of impending and actual malfunctions.
- Correct potential problem-causing conditions and fix malfunctions automatically.
- Log system status and actions taken.
Types of fault management
Two types of network fault management exist: active and passive.
Active fault management
Active fault management uses various tools to continually query devices and determine their status. Some of these strategies include using ping or checking port for Transmission Control Protocol and User Datagram Protocol.
Active fault management is akin to a person asking, "How are you?" to every person in a room at repeated intervals. This enables the system to identify and rectify potential issues in real time, sometimes before they even become problems. The trade-off, however, is more network chatter.
Passive fault management
Passive fault management systems monitor network environments for events that indicate whether a fault or failure has occurred. This information comes from many sources, including error logs or Simple Network Management Protocol traps.
Passive fault management is akin to a person who quietly listens until someone calls out for help. This type of fault management is more conservative with resource use. However, the drawback is that it might not discover faults until it's too late.
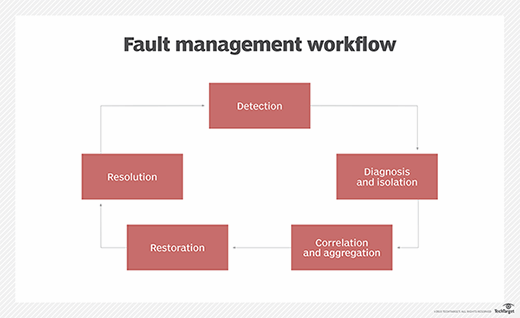
Fault management process
The fault management process used in commercial platforms might vary slightly among different vendors. However, all fault management systems typically follow the same lifecycle:
- Fault detection. The system discovers that something interrupted service delivery, or its performance has degraded.
- Fault diagnosis and isolation. The system identifies the source of the fault -- such as a component failure or power outage -- and its location in the network topology.
- Event correlation and aggregation. A single fault can cause multiple alarms. Fault management systems often group related events for administrators and provide a root cause analysis.
- Restoration of service. The network management system automatically executes any preconfigured scripts or programs to run services as soon as possible.
- Problem resolution. The system corrects, repairs or replaces the source of the fault. In some cases, manual intervention might be necessary.







