A Deep Dive Into Border Gateway Protocol
0:00:00 Speaker 1: This video on Border Gateway Protocol is brought to you by TechTarget through partnership with Global Knowledge.
0:00:07 Johnny Bass: Alright, welcome everyone to our little webinar here on BGP. What is it and why should I care? My name is Johnny Bass, I'm a senior instructor at Global Knowledge. I've been teaching and in the industry for a long time. I've been doing networking since the 80s, I've been working on Cisco gear since 1990. I've been teaching since the late 90s, consulting in the provider space, large enterprise, things along those lines. I teach a lot of different classes. There's lots of variation of classes, from data center, route switch, service provider types of things; a little bit of collaboration stuff as well, cloud, this, that and the other thing. And I've been working with BGP in the provider space for quite a while. So, we're going to talk a bit about what this thing's all about.

0:01:00 JB: So, our agenda here is to figure out what BGP is, where did it come from and really, why do we care. And then we get into a little bit about some nuances between different variations of BGP, how we can implement that, how does BGP compare against other protocols, and then some basic configuration, and a little bit of not-so-basic configuration. So, what attributes are all about and a little bit of manipulation of attributes. And then, how do we know that the thing's actually working? So okay, so we'll just jump right in.

0:01:38 JB: So, where did it come from, and why? Border Gateway Protocol, it's a protocol that was developed by, you can see, a couple of people from Cisco and IBM, back in the late 80s. And its purpose, initially, was to replace something called EGP, the Exterior Gateway Protocol. So, when the internet basically started to evolve -- and it started with the whole DARPA project and DARPANET -- and then once the Department of Defense realized that this Defense Advanced Research Projects Network was starting to become a little bit less controlled than they would like, they basically handed it over to the National Science Foundation to kind of evolve it into becoming more of a public infrastructure. And so, the NSF basically took that existing infrastructure that they inherited from DARPA and from the DOD, and evolved it into this NSFNET, and EGP was the routing protocol at the time that was working for NSFNET.

0:02:41 JB: But one of the things that they realized very quickly was that they needed a protocol that could scale up to some pretty decent numbers and be able to detect routing loops. So, BGP's first main claim to fame was that it could do that. It could actually detect routing loops, prevent those routing loops. Now it wasn't an overly complex mechanism to do that, but still it was more than what EGP could actually handle at the time. BGP then has evolved a lot since those days. The number of RFCs, or request for comments that have come out that are related to BGP is significant. I mean, there's books that are just about the RFCs that are 1,000 pages long because there's been so many modifications to the protocol over the years to be able to add additional functionality, to be able to give us more capability, more features, more function. And one of the biggest things that was added was the ability to do things like Classless Inter-Domain Routing, which gives us a lot more flexibility in the way that we actually advertise routing information. And BGP was kind of the first one to do that. Other protocols could do as well, but again, BGP was the first.
0:03:54 JB: And then from there, the addition of multi-protocol functionality was huge. And so, in 1998, with the introduction of RC2283, it allows us to be able to not only advertise information about IPv4 routing information . . . So IPv4 unicast, but it also added the capability for things like IPv4 multicast, and then IPv6 unicast and multicast and other things that we'll take a look at here in a second. But that was a huge addition then to the protocol, which all of a sudden kind of was setting a new spec, a new way of being able to handle how we advertise things and add a lot more flexibility to the protocol itself.
0:04:47 JB: As the protocol evolved, it went from one version to the next to the next. And basically, BGP version four, the 1654 that added the CIDR, is the foundation that gives us our multi-protocol BGP. Prior to the multi-protocol BGP, BGP versions were backwards compatible. So, if you're running version four and you have an older box running three, they could actually work together until the multi-protocol functionality was introduced. And so, then once that was introduced, then we can no longer go backwards as far as versions are concerned. It needs to be version four for the stuff to function.
0:05:25 JB: And again, with that introduction we got additional address families. And so, the address family just allows us to be able to identify the types of things that we want to advertise. We have IPv4, which was the original intent, the original protocol that it could support, in v4 unicast. But it also added, again, a multicast support, IPv6 support, supporting multi-protocol label switching, dynamic GRE, generic routing encapsulation, doing Layer 3 virtual private networks, support for Layer 2 VPNs, segment routing, virtual extendable LANs with ethernet VPNs, and there's more. There's more that we can do with it. So there's . . . And they can keep on adding additional functionality to it because of just that modification, the capability would be able to handle more than one address family with the protocol.

0:06:25 JB: So again, a very flexible protocol. And yeah, okay, it can be complicated. It definitely can be complicated, and there's lots of RFCs that are tied to it to be able to give us all this different functionality. The more flexible something is, the more complicated it tends to be. But okay, you don't have to make it complicated in your configuration. So, the basic configuration can be fairly simplistic, and adding basic support for different protocols, again, doesn't have to be overly complex.
0:06:57 JB: Yeah, there's lots of what I would refer to as "nerd knobs" when it comes down to BGP, lots of things that you can tweak, but you don't have to. Just because you can doesn't mean that you should. The protocol does scale to, again, very large numbers. So, you can see there, let me grab some numbers from a route collector back on February 27th. And so, yeah, 800,000+ routes for IPv4, 83,000 routes . . . And we're talking about the internet at this point. So again, we're talking about some pretty big numbers here. It's the only routing protocol right now that is capable of scaling to these kinds of numbers. So, it's definitely a complicated protocol, it does a lot for us. It can support a lot of different types of functionality. And yeah, again, flexibility typically means complexity, but again, you don't have to make it complex. Keep it simple. That principle, the thought behind it, trying to get the configuration as simple as you can possibly make it, you don't need to artificially make it more complex than it has to be.
0:08:02 JB: BGP is also very much a policy type of protocol. And what I mean by that is that we can manipulate things within BGP through policy. We're going to take a look at how we do things relative to Cisco platforms, and so we'll take a look at some IOS stuff, we'll take a look at a little bit of IOS XR, and we can basically manipulate just about anything that we choose to within BGP through some type of policy. With IOS and IOS XE we do it through route maps, through the XR platforms. The IOS XR boxes do route policy language. And so, we can use those things then to be able to manipulate things within BGP.
0:08:45 JB: Okay, so... Okay, that's basically where it came from. It came out of a need to be able to scale up to bigger numbers, and basically, really, to be able to detect routing loops. That's where it started. So, the internet of today having a routing protocol that could scale but not be able to detect routing loops, I mean it just wouldn't be stable. It would crash all the time, it'd just . . . Yeah, it wouldn't function. So, BGP's first main claim to fame was that loop prevention mechanism.
0:09:13 JB: So, great. So, what exactly is BGP? BGP is a protocol. And per Wikipedia, it's like, "Okay, it's a standard exterior gateway protocol. Okay, great." So, it basically is talking about autonomous systems, and . . . Okay, what is an autonomous system? It's a grouping of routers within the same administrative domain. So, think like a large enterprise or service provider, and the internet is made up of all these different autonomous systems that are all interconnected, and BGP basically is the protocol that makes all that stuff work. And decisions are based off a path and attributes and policies and rule sets, and that all sounds really complicated. And it's like, "Yeah, that's perfectly clear." Right?
0:09:58 JB: So, my definition of it is basically, it's a routing protocol that's designed to talk about a lot of stuff. And stuff is a technical term, at least the way that I use it, and so it scales to big numbers. And the stuff can be IPv4 routes, IPv6 routes, all those different address families, things. And it can support other types of implementations, other types of applications. Again, multi-protocol label switching, we have different things we can do within there to be able to do either Layer 2 or Layer 3 VPNs, and BGP can help us to scale to bigger numbers in those environments. If you're dealing with large data center environments then we could be doing something called virtual extensible LANs, which theoretically, can support up to 24 million things hanging off of the network fabric within a data center, or even outside of their data center within a given campus across a wide area network. And so, we have different potential implementations out there. Again, BGP can help us scale to those kinds of numbers. So, it scales to big numbers, and it has this ability to be able to advertise things, stuff.

0:11:10 JB: So where is it typically used? Well, I think the internet is probably the most obvious use case for BGP. It makes the internet work. If we didn't have BGP, the internet couldn't scale to the kinds of numbers that we have today, or the numbers that we're going to see in the future. So, the internet is not getting any smaller. We're adding more and more stuff to the internet, not just people, but the internet of things. So, probes and sensors and relays and whatever that are being added out there. And so, we have a lot of things that we have to be able to advertise, and again, the only protocol that scales to big enough numbers to be able to do something like that is going to be BGP.
0:11:52 JB: Other use cases for BGP, well, as a core protocol. So, if you're dealing with a large enterprise, agency, government, whatever, provider space, the core of those environments has to be able to scale up to bigger and bigger numbers. And so, again, it's the only protocol that can scale to really large numbers. So, when you're talking about like a large multinational enterprise where they have tens of thousands, hundreds of thousands of routes, then the only protocol that can really deal with that would be BGP. And so, it's the only one that can scale up to those kinds of numbers.

0:12:28 JB: And so, what you typically would end up seeing is you have other routing protocols that are kind of on the edge like OSPF, so Open Shortest Path First, or Intermediate System to Intermediate System, or the enhancement to your gateway routing protocol, in these domains that are hanging off the edges. And then they redistribute their routes into BGP. And then, typically what we'll do is we'll inject a default route back the other direction. And so, BGP, the core protocol, the core network would know about everything, and then the domains that are hanging off of it just know about what's within those domains and then a default route that points them towards the core, which is a fairly typical way to be able to implement something like that.
0:13:09 JB: With multi-protocol label switching, well, with the introduction of Layer 3 VPNs, they needed something that wasn't necessarily something that had to be able to scale, but had the flexibility to be able to advertise some information across a interconnecting network, this cloud, this MPLS environment, that carries routing information from one edge device to another edge device. And the only protocol that really kind of made sense to be able to do that was BGP. And so, BGP was modified then to be able to help support the advertisement of labels for certain routes between the edge routers within an MPLS cloud. With the introduction of Layer 2 VPNs, they initially started off without really kind of involving BGP, and just using some type of interior gateway routing protocol to give us connectivity from edge to edge, and things were done fairly statically initially as far as creating these pseudo wires, these virtual connections across from one edge router to the other edge router that then presents what looks like a Layer 2 connection to the customer. But they -- "they" as in "providers" -- and even in the private clouds. So, in the provider space and even in private MPLS clouds, they realized fairly quickly that static configurations for Layer 2 VPNs doesn't scale.
0:14:35 JB: So, to be able to scale to bigger and bigger numbers, they involved BGP, and so again, an address family was introduced specifically to be able to help support Layer 2 VPNs with BGP. And so, it just allows us to be able to have more pseudo wires, more virtual connections across the MPLS cloud to make that happen. Again, with the introduction of virtual extensible LANs to be able to deal with very large data centers, large to what we would now refer to as mega data centers, where we have hundreds of thousands, millions, tens of millions of potential things that might be . . . And things could be servers, virtual machines, physical hosts, legacy networks, whatever it happens to be. And again, virtual extensible LANs give us the ability to be able to identify uniquely these things that are hanging off of this cloud. And we have to have a protocol then that can help us support the number of identifiers that VXLANs can introduce. And so, we can have up to 24 million unique identifiers within VXLANs. And again, BGP is the only thing that really can scale up to those kinds of numbers.
0:15:50 JB: It's expanding beyond the data center environment. And so with Cisco's introduction of software-defined access, in the campus view we're using VXLANs outside of the data center realm, and again, BGP has a role that it can play within that environment as well to help us scale to bigger numbers across a campus view. So again, things keep on evolving with this protocol, and we keep on finding new use cases as to where BGP can be used.
0:16:23 JB: How does BGP compare with other protocols? Because it is a routing protocol. Now the thing is, is that BGP, it falls into a category, and when we talk about routing protocols we look at them from several different ways. At the CCNA level, we talk about comparing routing protocols for classful versus classless, which just basically means do they advertise the mask. As far as IPv4 is concerned, there's no concept of classful versus classless for IPv6. But for IPv4, do we advertise the mask or not? If we don't, that's classful, if we do, that's classless. All routing protocols today are classless routing protocols. So, they all advertise the mask.
0:17:07 JB: We talk about if they are distance vector routing protocols or if they are link state protocols. And so, distance vector is hop-by-hop type of behavior, link state is more of a topology view, and so we get to see everything. And the only protocols that are link state is the Open Shortest Path First and the Intermediate System to Intermediate System. Everything else by definition really kind of falls into the category of distance vector because they're hop-by-hop. Now typically, we don't like to lump BGP with RIP and EIGRP with RIP because, I mean, okay, RIP is really very kind of basic and it doesn't scale very well and so on and so forth. So, they talk about BGP and EIGRP as being either an enhanced version, an advanced distance vector protocol, or with BGP, they'll call it a path attribute vector protocol. Something that sets it apart that sounds a little bit more fancy.

0:18:07 JB: So again, we try to make BGP sound a little bit more complex, a little bit fancier than RIP, to try to set it apart. So again, there's two major categories, distance vector versus link state, but yeah. And really by definition, BGP would fall into that definition of distance vector but it's more advanced than RIP, it's more advanced than EIGRP. The other way of classifying the routing protocols are exterior gateway protocols and interior gateway protocols. Okay, so EGP, IGPs, interior/exterior to what? Well, relative to autonomous systems. And so again, an autonomous system is a grouping of routers, networks within the same administrative domain, so underneath the same control. A provider's network is an autonomous system. A large enterprise would be an autonomous system. And then we interconnect those autonomous systems through exterior gateway protocols. And again, the only EGP that's available today is going to be BGP.
0:19:07 JB: Now, some of these other protocols could be used between autonomous systems privately if you're not talking about large numbers of routes. But again, when we're talking about the internet, then we're talking about, "Okay, BGP is the only one that can do that." It's the only one that can scale to big enough numbers. The IGPs are typically designed to talk more detail and to be more reactive to change. Though RIP is really very, very slow, it's very simplistic, it doesn't scale well, and it's the slowest protocol of all of them. But otherwise, when you're talking like OSPF, you're talking about EIGRP, you're talking about IS-IS, these things react to change a whole lot faster than BGP does, and we'll take a look at that here in a second.
0:19:53 JB: So, our different protocols have different uses. And we're not going to run just one protocol. So, even within a given autonomous system, we're going to have some protocol that's working within that autonomous system, but we could also have BGP involved as well. So if you look at a provider space, then you use an IGP to be able to interconnect all the routers within that autonomous system, but then BGP is talking over the top of that environment to be able to pass routing information from one edge device to another edge device within that same provider space if that provider is a transitive type of autonomous system. So, an internet service provider that's supporting large enterprise and other service providers, then it would be transitive, and those routes have to be able to transit across that, and we are using BGP as a way to be able to carry that information. But then, we have an underlying environment that we have to be able to move across that is running OSPF or that is running IS-IS as its protocol to be able to just navigate across from one edge router to other edge router.
0:21:07 JB: So BGP, it scales the big numbers. I think I've beat that to death. BGP is not a speedy protocol. Okay? We have to assume at least a minute by default for change. So BGP is designed for scaling. I think, again, I've beat that to death. But it's not exactly built for speed. So, one of the things about BGP is that it's, again, for the scalability, we have to worry about stability, we have to worry about how much impact it's going to have on the platform that's running it. And so, we don't want to be totally reactive to change with BGP. So, we assume a minimum of a minute for change to happen. And it's not a triggered event, it's something that's actually scheduled. So, there's a scan process that runs every 60 seconds that's looking for change that's happened to the tables.

0:22:08 JB: And so, when we receive something . . . Alrighty. So BGP scales to big numbers, I think I've talked about that enough, and yeah. Okay, I guess, yeah, we'll talk a little bit more about that, but just for comparison's sake. But the time that it takes for BGP and routing protocols to accept change is referred to as convergence. And so, that time that we have to accept change and basically get back to a point of a steady state of what the network looks like. BGP is not designed for speed, it's designed for scalability. And to help with the stability of all those routes, it's not a reactive type of protocol, we have to wait for the scan process to actually run to determine that there's actually been a change. And the scan process is a scheduled event that happens every 60 seconds. So, we have to basically assume then that change is going to take at least a minute then for stuff to happen. Now, it could be fast in that it could be longer than that. It kind of depends on when things happen and how things happen.
0:23:13 JB: So, if something happens and we just ran the scan process just before that happened, then it's going to take us a minute to pick up on that. Now, depending on what that change was, it may actually take multiple scan cycles for it to figure out how to deal with change and figure out what the new best path is going to be. But if it's something that is a little bit more simplistic, if we're not talking about the internet, if we're talking about more like an MPLS implementation that we're supporting, or a core protocol, we're not dealing with a lot of different changes that are happening at the same time. The internet is not stable, it's never technically converged, there's always change that's happening and the changes could have more of a ripple effect and having multiple things that could be impacted by those changes. And that's why it could take longer for routing information to start working again for different destinations.
0:24:10 JB: But if I'm dealing with a smaller kind of implementation, if I'm dealing with something that's a little bit more stable environment, then if the change happens just before we're about to run the scan, it could look like it actually . . . It picks up on that change very quickly. So, it all depends on where we are within the scan process. Once it picks up on the change, then usually a second later it's actually determined what the best path would be again to be able to get to that destination. Again, if it has enough stable information to be able to do that.
0:24:42 JB: When you're talking about the IGPs, on the other hand, the IGPs' convergence time is based off of different mechanisms. And so, RIP has a whole timer that impacts how long it has to wait before it can consider a new path if the primary path fails. And unfortunately, by default, the whole timer is 180 seconds, so three minutes for it to accept change. OSPF, it's a flooding action, it's a triggered event. So, something happens, and we flood the information out very quickly within milliseconds across all the different routers within the same area. But then, Cisco, somebody within Cisco, recognized that there could be an impact on the router itself whenever there's change, and so there's an automatic throttling that happens within OSPF that waits five seconds before it runs the Shortest Path First algorithm to determine the new best path.
0:25:41 JB: And so, we have to bank on five seconds, but it could be longer than that depending on what's happening and how big the infrastructure is. But generally speaking, five seconds is a pretty decent number. IS-IS doesn't have that same throttling effect. IS-IS does scale to bigger numbers than OSPF does, and it can react more quickly than OSPF. It runs the same algorithm that OSPF does. And so Open Shortest Path First and Intermediate System to Intermediate System both run Dijkstra's shortest path first algorithm but they run it in slightly different ways. And the way that IS-IS does is a little bit more efficient, so Cisco didn't bother putting in that throttling. So, it takes about a second or so for IS-IS to determine a new best path.
0:26:29 JB: But again, it's dependent on the size of the topology. But again, for typical implementations that's a pretty decent number. EIGRP, the Enhanced Interior Gateway Routing Protocol, it tends to be sub-second behavior. Now, it is dependent on the size of the network, and it's dependent on other characteristics. So EIGRP tries to pre-select an alternate path. In EIGRP terminology, the primary path is known as the successor, and the secondary path is known as the feasible successor. And so, if it's able to mathematically guarantee that this alternate path is loop free, then it pre-selects it and gives us that sub-second type of behavior. And so, we're talking about tens of milliseconds or maybe hundreds of milliseconds in accepting that change.
0:27:19 JB: Worst case, we're still talking around a second or so if it's not capable of pre-selecting that thing. So again, typically, if you exclude RIP then you're looking at a much faster type of convergence time compared to BGP. Again, just going back to scale, BGP can scale to very large numbers. Now, these numbers you have to take with a grain of salt. It is dependent on the platform that you're talking about as to how big the protocols can actually scale to. So BGP theoretically could scale to millions, where the IGPs not so much. So, IS-IS scales to in the 100,000 range, again, depending on the platform that you're talking about, OSPF, EIGRP in the 50,000 range, and RIP, yeah, maybe you can hit about 10,000 routes, but why? Why would you want to? But it is dependent on the platform that you're actually running the things on.
0:28:17 JB: Okay, now when you're looking at BGP you might hear that, "Okay, you can run it as IBGP or EBGP" Well, BGP is BGP. Okay? Border Gateway Protocol, it runs on top of TCP, so we have reliability, and everything's done reliable within the protocol. The difference between IBGP and EBGP really is just, "Where am I running BGP?" And so, when I peer up between routers, and so BGP neighbors or BGP peers are routers that were neighboring to each other, if I'm within the same autonomous system, that's known as IBGP. If you're between different autonomous systems, it's EBGP. And so that's the initial difference between them, is just where is it running. Is it within the same autonomous system, or between different autonomous systems? So, like in this example here, CT-5000 would be a transitive autonomous system, and so we're passing the routing information through us to get to another autonomous system. So maybe I'm a service provider that's interconnecting other service providers or a large enterprise to be able to get to the internet.
0:29:28 JB: So, I had to pass that routing information through me. And I'm going to have some type of IGP running within that space that allows me to have that reachability from one edge router to the other, from one BGP speaker to the other. EBGP is a neighbor relationship then that's between directly . . . Well, between different autonomous systems. And so exterior, interior. Okay? Now I just added this note in here that EBGP with IOS XR platforms requires route policy. Okay, why do I add that? Because with IOS, IOS XE, once I form the relationship, it doesn't matter if it's EBGP or IBGP, I'm allowed to advertise routes, I'm allowed to accept routes. With the IOS XR platforms, with IBGP, again, that's still a true statement. I'm allowed to advertise routes, I'm allowed to accept routes without any special additional configuration. But for external connections between different autonomous systems with IOS XR, it does require route policy language to be applied that permits the advertisement of routes and the acceptance of routes. It will not accept or advertise routes by default to an external peer unless you apply policy.
0:30:46 JB: EBGP versus IBGP, there are some differences in behavior. So again, within the same autonomous systems versus between different autonomous systems. EBGP, the time to live by default is set to one, so we assume that we're directly attached between neighbors. With IBGP, we have a TTL 255. So, we assume that we're going to get routed across that space to get us from one edge router to the other. Now we don't have to be, we could be directly attached. And with EBGP, we can change that TTL to be something bigger, so we could do multi-hop EBGP to be able to get us from one edge router to the other if we had to, or one autonomous system, so maybe there's some interconnecting router that's between them. But again, it's typical that they're directly attached to each other.

0:31:34 JB: Certain attributes are meaningful to EBGP versus IBGP. We'll talk a little bit about the attributes. So local pref is used within the autonomous system to influence how we leave the autonomous system, but it's not something that we look at for EBGP relationships and routes that we're learning through EBGP. The AS path is modified, so the autonomous system path is an attribute and gets modified with EBGP, it does not with IBGP. The next hop attribute, so who do I have to go to to get to that destination network, is typically modified with EBGP, it's not by IBGP. Again, the way that we advertise routing information is a little bit different, the way that we pass information between peers. The loop prevention mechanism for BGP is the AS path, so we look at the AS path for our own AS number within the path. If we see that AS number, then we reject the route. So that's the normal loop prevention mechanism. And we modify the AS path for EBGP, well, IBGP, we don't. And so, there's a loop avoidance mechanism that we do with IBGP that basically says that we're not allowed to advertise an IBGP learned route to another IBGP speaker. Which does turn out to be a little bit of an issue because it requires then a full mesh of adjacencies between routers within the same autonomous system.
0:33:07 JB: Okay, so we'll talk about that here in a second. The administrative distance is a level of trustworthiness of a routing source. So when we get this information in from different routing protocols, if we have the exact same route known through more than one source, so I know it through EIGRP, I know it through OSPF, I know it through IS-IS, I know it through BGP, then the admin distances a mechanism that's used within the router to identify which one is the most trustworthy. And the lower the number, the more trustworthy the route source is. And by default, EBGP has an administrative distance of 20, IBGP has an administrative distance of 200.
0:33:50 JB: Okay, and this, again, is just how I'm going to contribute information into the routing table. The full mesh is an issue that we have to deal with. Full mesh doesn't scale very well, but it's the loop avoidance mechanism. So, loop prevention is the AS path. And we look at the AS path, but since we don't modify the AS path within a given autonomous system, then every edge router then assumes to have a relationship with every other edge router that's speaking BGP. And if we have other routers in between that are also speaking BGP, then they would have to be part of this full mesh.
0:34:26 JB: Again, full meshes don't scale well. Each one of these things would be a separate TCP relationship that a session that has to be established with a BGP neighbor relationship over the top of that. It's a lot of stuff that the routers have to maintain as far as those relationships, it's a lot of configurations that we have to do. So, to get around the full mesh we have two possibilities that we can introduce. We can either break up this real autonomous system into smaller chunks. And so, the smaller chunks are little mini autonomous systems, also known as confederation members. And the confederation member is not a router, it's a sub autonomous system, and so we can break it up into different smaller groupings of routers, and then we form relationships between the confederation ASes. We then advertise the confederation AS between the different members, and we have our normal loop prevention mechanism back again, between different confederations.

0:35:34 JB: Now confederations aren't done a lot any longer because it adds a lot of complexity. You have to change the way that you actually neighbor things up, it gets confusing as to what your autonomous system number is supposed to be and how you're supposed to neighbor up. So, Cisco introduced an idea of route reflection years ago as an alternative to confederations. And route reflection then breaks the rules of the full mesh. And it's referred to as the IBGP split horizon rule, which basically says that you're not allowed to advertise an IBGP learned route to another IBGP neighbor. So, you can go from EBGP to IBGP, you can go from IBGP to EBGP, you can go from EBGP to EBGP. So, the only one that's not legal by default is IBGP learned route to another IBGP neighbor, because again, we don't modify the AS path by default. So, route reflection adds new attributes that we can then use for loop prevention.
0:36:32 JB: Every router has a router ID to uniquely identify them, and so the route reflector then will add to the route the originator ID, which is the router ID of the box that sent it to the first route reflector. And then the router reflector then can reflect the route, which is in the IBGP learned route, to another IBGP router, but with that originator ID tied to it. So, if it ever gets back to the original router, it can reject the route. The other thing that the route reflector is going to add is another attribute called a cluster ID. And the cluster ID is either the router ID of the router that is acting as the route reflector or is a configurable value that we can set to a group of route reflectors. So that way, if it ever gets back to the route reflectors, they can see their own cluster-ID as part of the list, and they can reject the route. And again, we have a couple of different loop prevention attributes that are added. Now those are only for IBGP. And when we hit an external peer, the originator ID and the cluster list gets removed before it gets advertised to an external peer. So, they are only many for internal environments that have route reflection.
0:37:53 JB: The configuration for confederation, again, it is a little bit more complicated, because we actually have to configure the autonomous system to be the confederation AS number, not what the real AS number is. And so, I belong to AS 100, but I'm not configuring AS 100, I'm configuring 65,000. And then my confederation identifier is 100, which is my real AS number. If I have another confederation sub autonomous system, then I have to identify them as a peer. And so, the other confederation AS is 65,001, and so we're going to form a relationship between 65,000 and 65,001, and again, that's going to add to the AS path those confederation identifiers. And they're listed within parentheses when you take a look at their BGP table to indicate that they're not real AS numbers, they are confederation AS numbers. They get stripped out before we actually go to real external peers.
0:38:58 JB: Confederation relationships are kind of in between IBGP and EBGP. And so, when we're neighboring up between routers within two different confederation ASes, the TTL is set to 1 by default. So, we have to worry about whether or not we need to do EBGP multi-hop or if TTL 1 is going to get me there. But like IBGP, it doesn't change the next hop attribute. Things that normally would get stripped out between external peers stays because they understand that these are really part of the same autonomous system. And so, I just show a couple different examples here between the IOS platforms and IOS XE. And so just slight variation here, but this does the exact same thing. So we have our confederation identifier, which is our real AS number, we're peering up to a router that's within a different confederation AS, and so we have to identify that as being a peer, and then just the configuration of the neighbor. And again, any attributes that we have to do to be able to make the relationship actually function.

0:40:09 JB: For route reflectors, again, things are a little bit different. So now in this example here the 65,000 is my real AS, and I'm not hiding what that AS number is. I'm not technically hiding the real AS number over here, just I'm using a different AS number internally than what the external world actually sees. Where in this example over here, this is my autonomous system number. And so, then the neighbors that are facing towards the route reflector just has a normal BGP relationship to that route reflector, and then the route reflector itself has this additional statement in there of route reflector client. And so that just says that, "Okay, this device over here," or in this case, the IOS XR example, "This neighbor over here, is a client of mine." By the way, the next hop self is to change the next hop attribute when I go from an external peer to an internal peer. It has no effect on routes that were reflected. Okay? So those routes will still have the original next hop value, the next hop attribute, as it's being reflected through the route reflector.
0:41:24 JB: Alrighty. Address families, again, how do we configure these things, how do we use them? Now, there are some differences between IOS, IOS XE, and IOS XR. So IOS and IOS XE are the same basically, it's just the difference is that IOS XE has IOS running over a Linux kernel and it's a modular multitasking operating system, where IOS is a multitasking operating system, but it's monolithic, and so everything kind of stacks on top of each other and, yeah. So, theoretically, IOS XE is just a more stable version of IOS, but the basic behavior and a lot of the commands are basically the same between the two of them. XR, different operating system, kind of intended for more the carrier class type of environment type of platforms.
0:42:23 JB: We are dealing with multi-protocol BGP across the Cisco platforms, but with IOS and IOS XE it assumes that we're going to deal with IPv4 unicast. It doesn't assume any other protocols. You have to tell it that you're going to support IPv6 unicast, or you're going to do VPN v4s or whatever. So, you're going to support Layer 3 VPNs across a MPLS cloud, you have to tell it that it's going to do those kind of things. With IOS XR it doesn't assume any address families. We have to specify which address family it is that we want to actually run with IOS XR. So, everything is manually set up then with the carrier class type of platform.
0:43:07 JB: Looking at the possible address families, this is kind of a busy slide. We're not going to go through it all, but it's just to introduce that yeah, there's . . . Again, there's complexity here. So, we have a lot of different address families that we can support. Again, IPv4 unicast is assumed, everything else is not. And so we basically have to tell it that we want to support IPv6 unicast, or that we want to support multicast, or we want to support tunneling, or we want to support our VPN operations. With XR it's a little bit shorter list of this, there's just more variables tied to the list for . . .

0:43:42 JB: So, when you take a look at the address families relative to IOS XR, it's a shorter list compared to what we have with IOS and IOS XE. But technically, all the things that we can support for the address family for IOS is also supportable over here with XR, we just have variations of the syntax. So what they've done is they've given us address families, base address families, so that we can then modify depending on what the needs are to be able to do our IPv6 unicast, to be able to do our Layer 2 and Layer 3 VPNs, to support multicast. So those things are still supportable here it's just the syntax is different with XR compared to IOS.
0:44:27 JB: Our basic configuration, again, with EBGP we assume the TTL of one, it is the default. So, we assume that the neighbors are going to be directly attached to each other. And so typically, we use the physical interfaces that are directly attached for the neighbor relationships. Now you might find that, okay, some are using the loopback interfaces of the router so they directly attach to each other, and they're either using a static route or they're using some type of dynamic protocol to be able to advertise those loopback interfaces, but they're still directly attached to each other. With IOS XR, we don't have to make any changes to make that work. They will actually form a relationship without any problem. With the IOS and the IOS XE, because of the TTL of one there, the neighbors won't form by default. If you're trying to neighbor up between directly attached neighbors using loopback interfaces, you have to tell them that they can get to each other.
0:45:24 JB: So, the routers basically assume that since I have to route myself there then a TTL of one won't get me there. So, it won't even attempt it. So, you can either change the TTL to be something bigger than one, and in which case then it will try, or you can just disable the connect check, which is saying that, "Okay, is this thing directly connected to me or not?" And so then if you disable that with IOS and IOS XE, it will attempt to get there even though it has to route itself to it, and because the loopback interface is on the router that you're directly attached to, it will work. With XR, that connect check, that checking to see if the things are actually directly connected or not, isn't there by default, you can't even turn it on on XR platforms.
0:46:10 JB: With IBGP we assume a TTL of 255. And so typically we are going between loopback interfaces, and typically we're routing between those devices. And so, we're going across a cloud of devices within a given provider space or your core environment, and we have a core IGP that gives us that reachability then between those different BGP speakers that are doing IBGP. So, it's most typical to use loopback interfaces for IBGP. It's most typical to use the physical interfaces for EBGP. Now, that doesn't mean that we can't use loopback interfaces for EBGP, that doesn't mean that we have to use loopback interfaces. We could use physical interfaces for IBGP relationships. So we have the typical versus what can you do.

0:47:05 JB: Now, yeah, I just added this little note over here that we normally do static relationships with BGP. So okay, we have to do a static neighbor statement on both sides to be able to form a relationship between each router. If you think about the internet, and the number of routers that cross the internet are speaking BGP. That's a huge number of stack configurations. But that's what we have to do to be able to make those things work. With IOS and IOS XE, there is an option for dynamic peering. It doesn't exist with the XR platforms. It's not exactly very dynamic though, because what you're doing is you basically have kind of a hub or simplified router that you define something called a peer group. And a peer group, it allows us to set up a policy that would be in common against a group of routers, a group of neighbors. Well, one of the things you can do within the peer group is you can identify a range of acceptable addressing, so where are the neighbors coming from. You can identify one or multiple AS numbers they could be coming from, and then you can assign policy against that. And so that's a way of doing a dynamic peering on that hub device so you don't have a static neighbor statement pointing towards the other devices. Now the other routers have to be statically pointing towards it though.
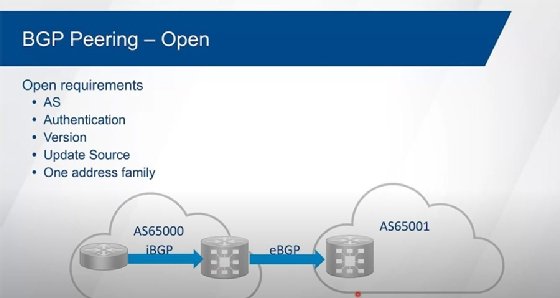
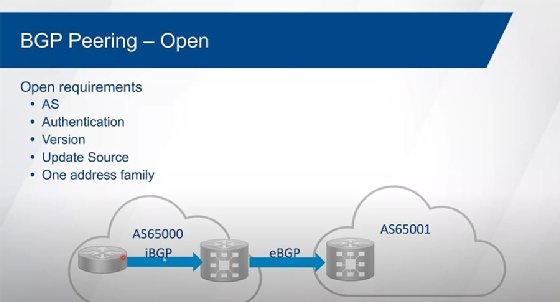
0:48:28 JB: So, it's static on one side, but dynamic on kind of this hub device. It's not typically done. It's most typically done as a static configuration from neighbor to neighbor. I've only actually seen dynamic used in a couple of production networks. Again, it's not something I see very often at all. But okay, it is an option, so I thought I'd just throw that in there. Now, when we're forming the relationship between neighbors, it doesn't matter if it's IBGP or EBGP, the first thing that we have to do is we have to, well, check to see that we actually have reachability to that neighbor. So, is it directly connected to me or do I have to route to it? And then I try to form a TCP session between them first. So, they go through the three-way handshake for TCP, and try to form that relationship. And then for TCP, and then once TCP comes up, then we send what's known as an open message. And the open message carries certain attributes or capabilities between the neighbors. And so, we send an open message, and the open message carries things like, "Who am I?" So, my unique router ID. It carries what my autonomous system number is. It carries any authentication information, it carries my version information, it carries the address families I want to support. And it carries other capabilities, but these are the ones that have to match for us to form an adjacency.
0:50:04 JB: Okay, for us to be able to form a relationship the autonomous system numbers have to be correct. And so, what I think your AS number is has to be what you're configured for. What you think my AS number is has to be correct. If we're doing authentication, and for a long time the only authentication that we had was MD5. On some platforms today, we can support SHA, but that would have to match up. Or no authentication at all. The version has to be version 4 now, we don't have any choice any longer. Version 4 supports multi-protocol BGP, and we're no longer backwards compatible. The IP addressing that we're using for the source of these messages has to be what I'm pointing towards as a neighbor. And so, whatever my neighbor statement is that I'm pointing towards you has to be the address that you're sourcing your messages from, otherwise we won't form a relationship. And we have to have at least one address family in common. Again, IOS/IOS XE assumes IPv4 unicast, XR doesn't assume anything. If we don't have at least one address family in common there's no point in us having a relationship. Okay? So, what you'll end up seeing is, if that's the case, it'll just sit there and flap. It'll attempt to bring the relationship up and then doesn't find the address family in common, so the relationship goes back down again.
0:51:20 JB: And then it'll go through that process of the three-way handshake again for TCP, send the open messages, can't find the address family in common, it goes back down again. And it'll just sit there and flap. Everything else is considered to be optional attributes or capabilities. So, any other function that we want to be able to handle, additional address families, those are all optional. We don't have to match those things and have relationships still come up. As long as we have at least one address family in common we're good to go. So, the basic configuration of it. So, we have to start off with the remote AS command on IOS. IOS and IOS XE, we go into our routing process here, so router BGP at whatever our autonomous system number's going to be. Then we identify a neighbor. And so, the neighbor, if it's the same autonomous system as me, that's IBGP. If this is different, it's EBGP. Since we typically use loopback interfaces for IBGP relationships, the default behavior is the source of all the messages from the interface closest to the destination I'm trying to go to. And so whichever interface is the outgoing interface towards this 192.168.100.1 is what I'm going to source those messages from.
0:52:38 JB: So I need to change that to be the loopback interface. I'm assuming that I'm going to be passing EBGP routes to this IBGP peer, so I need to change the next hop attribute to be myself. By default, when I go from EBGP to IBGP, I don't change the next hop attribute. So, it would normally carry the external neighbor's address for next hop. And it's not common, then, for that internal peer I'm passing the route to to know how to get to that. So, the common typical type of configuration is that we would add this next hop self. The XR example over here, we start the process, again router BGP 65,000, we have to tell it that we want to support address family IPv4. So, this is done underneath the main process. If we're going to support v6, we'd do the same thing. Okay? And then from there we identify the neighbor, the remote AS that it belongs to, that we're going to use the loopback zero as our update source, and then we have to identify the address family that we're going to support with this neighbor. So just turning on the address family underneath the process isn't good enough. This just turns on the potential then for BGP on this router, but then we have to also identify that specifically for the neighbor. So we're going to advertise v4 routes to this neighbor. And because it's an IBGP relationship, again, we assume that we're going to go from EBGP to IBGP, and we add the next hop self.
0:54:09 JB: For external peering, again, we typically go between directly attached interfaces, so the only command that we had to worry about is the remote AS command. And because the AS number is different than mine, then that's an EBGP relationship. And that's... Really here's no special command to set one apart from the other. Now, with XR, it's a little bit more complicated. And so the reason for that, again, is because with IOS XR we don't assume that we're going to advertise anything to a neighbor that's external, or accept any routes in. So IOS and IOS XE automatically will advertise routes and accept routes, but XR will not for external peers. For internal peers, yes, but not for external peers. And so we have to have a route policy language then to be able to allow us to be able to advertise and accept routes.
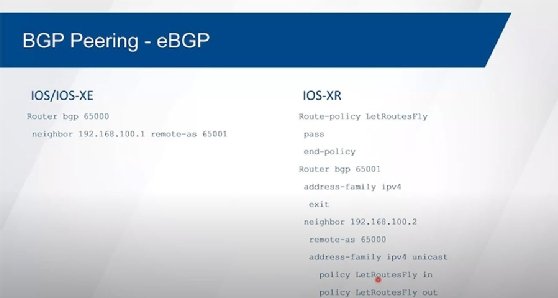
0:54:57 JB: Now, it doesn't have to be overly complicated. In this case here, this is the most basic and simplest route policy you can come up with that just says, "Okay, allow everything." So, pass. There are no conditions to it, we don't have to match on anything. It's just everything is going to be allowed in or out, depending on how this thing's going to be applied. And then we have our BGP configuration, our address family, our neighbor, the remote AS over here. And you can see that they're different here between these two over here. And then we have the address family, IPv4 unicast, and we're applying that policy. So, this just allows then for routes to come in, this allows for routes to go out. Without that application, without this policy, then the neighbor will come up because we have the address family there, but you won't see any routes being accepted, you won't see any routes being advertised.
0:55:53 JB: To get routes into the process we have basically two choices. We can either do a network command, or we can do redistribution. A network command has to match on an exact match within the routing table. So, when you do a show IP route you see what I'm referring to as the IGP table, but it's the routing table that's used as a foundation to forward traffic through the router. It has to find a match against that table. If I don't find a match, I don't inject the route into BGP, I can't advertise it. And so, the network statement has to find the exact match.

0:56:33 JB: Redistribution is from another protocol or from static or from connected into BGP. Now it also feeds from the routing table. And so, from the IGP table, I should have probably actually put the RIB in here, the routing information base as being more correct. But it feeds from that table based off of whatever that protocol is. So, if I redistribute OSPF into BGP, it's going to look for all the routes that have Os as a code within the routing table. But it also finds the interfaces that that routing protocol is running on. Okay? So whichever interfaces OSPF is attached to, those are going to be connected routes, they're not going to be learned routes. And so those are also going to get advertised into BGP.
0:57:18 JB: Now, auto summary for IPv4 is disabled by default on IOS and IOS XE, it's not something that ever existed with IOS XR platforms, and you can't turn it on because it doesn't exist for XR. With IOS and IOS XE, you could turn auto-summary back on again. And it does impact both the network statement and the redistribution as to how it functions. With redistribution, when you turn on auto-summary it now summarizes the routes to the classful boundary. So, it no longer injects subnets, it now injects the classful information.
0:57:55 JB: So, if I had the 10 space and I have a bunch of subnets of 10 within a routing table, and I just do a redistribute OSPF, and I see all these 10s with slash 24s and 30s and whatever, if I turn auto-summary on then what I'm going to find in the BGP table then is 10.000/8. So, it'll automatically summarize that information. With the network command, if I do a network of 10.0.0.0 and I assume a mask of 255000, it won't inject anything into the BGP table if auto-summary is disabled and I've got subnets of 10. I don't actually see the individual route of 10.000/8 in the routing table, I'd see all the 24s and 30s and whatever. But if I turn on auto-summary and I do that never command that is classful, a subnet is good enough to be able to trigger the route to go into the BGP table. So, auto-summary is disabled by default, it's not something that we typically will turn on any longer. We like to have all those individual subnets if we're redistributing and then manually summarize if we need to. The way that we do summarization within BGP is called the aggregate address command. And so, doing an aggregate then allows us to control how we summarize things as we choose. So, it gives us just better control. So, yeah.
0:59:33 JB: So, network command, again, we're looking at an exact match. And so, I'm looking for that /24 within the routing table. Again, the auto-summary is disabled by default, or I can do a redistribute. And again, auto-summary is not going to have any impact, so we're going to pick up on all the Os in this case plus the connected routes that the OSPF are running on. All the individual subnets are going into the table. With XR, again, network commands or redistribution is done underneath the address family. Now I show it over here underneath the address family for IPv4 on IOS and IOS XE because I assume that we're going to be doing multi-protocol BGP, but technically, because IOS and IOS XE assumes IPv4, you could do these commands underneath the main process. And it will accept it there. And if that's the only protocol you're supporting, you're only doing IPv4, then you don't need to deal with the address family IPv4. It'll just . . .

1:00:31 JB: You can just put it underneath the main process and it'll just keep it there. But if you do start doing multi-protocol type of functionality -- so if I add the address family for IPv6 for instance -- it will automatically also add the address family IPv4 and it'll move these commands from the main process to underneath the address family. So, the router will automatically do that for you. Again, we assume that we're doing multi-protocol BGP, but again, because IOS and IOS XE assumes that we're doing IPv4 unicast, and that's the only thing it assumes, then again, the behavior is a little interesting. Again, when you do add another address family, a little bit of magic happens and the configuration changes automatically for you to add the address family for IPv4 unicast. And the unicast keyword over here, for whatever reason, we can type it in there, it'll accept it, but it doesn't show it to us when we take a look at the running configuration. Yeah, when you do the address family IPv4 multicast, that will stick, it just assumes the unicast keyword that's out there. And it'll take it, but it just . . . Again, it doesn't show it to you in the configuration.
1:01:49 JB: Here's our v6. So here, we're doing a neighbor command, a little bit more cumbersome address base, IPv6. Now this does assume that we've actually enabled IPv6 unicast routing because IOS/IOS XE does not assume that you're going to support IPv6 as a router. You can apply v6 addressing to an interface without any special additional commands, you just go to the interface and apply the addressing. But if you want to turn on any routing protocol for IPv6, you first need to do IPv6 unicast routing into the global config, then it'll let you turn on OSPF version 3, or it'll let you turn on RIP Next Generation, or it'll let you configure BGP to support IPv6. The neighbor relationship over V6, remote AS command over here, so this is an EGBP relationship. It could be IGBP, address family, IPv6 unicast. Now again, because we don't assume anything but IPv4 unicast, you have to tell it to advertise v6 routes even though we're running over the top of v6 over here. So, you have to activate the neighbor underneath the address family for IPv6. And then the network commands would go underneath the address family as well. We can do our redistribution of our IGP there. No problem.

1:03:09 JB: On the XR side IPv4 and IPv6 routing is enabled by default, so there's nothing special that you have to do in the global configuration. You just add the address family support underneath the BGP process, you do your network commands, your redistribution there underneath the address family. Now, we do our neighbor statement. Now it's subtle, but the indent here, and I put in the X there just to make sure that we understand, this is not done underneath the address family. This is done underneath the process. So, okay, this is at the same level of configuration as the address family. And then we identify what the remote AS command is, we identify the address family we want to support. If we want to summarize within BGP, then we do the aggregate address command. And so, the aggregate basically allows us to be able to summarize something to be less specific than what we had before the subnets, but more specific than just the classful boundary. Okay? So, in this case, I've just got the one space in here, and I don't want to advertise that as a /8, I want to advertise that as a /16.
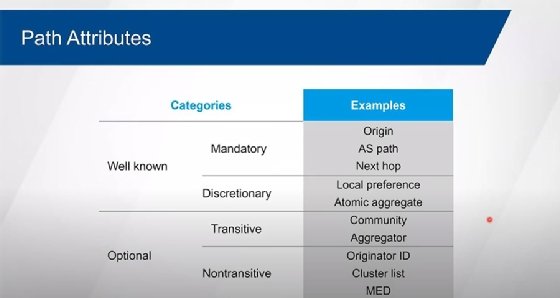
1:04:19 JB: And so, with IOS/IOS XE we do it in dotted decimal -- with XR it's just a length -- and then we have additional things that we can set as options. So additional attributes that we set along with this thing, or we can identify that we're only wanting to advertise the summary. If we don't put in the summary only here, then it'll advertise this aggregate, the summary, but it will also advertise the more specific routes as well. And so, if we wanted to suppress the more specific routes and only advertise the aggregate then that's what the summary only does for us. Other attributes that we can basically set in combination with that. Speaking of attributes, we have groupings of attributes that BGP uses for loop prevention and also for selecting best path. The attributes are in two main categories, either well-known or optional. The well-known attributes are either mandatory, which means that they have to be there and you have to understand them, or they're discretionary, so they don't have to be there, but if they are there I have to know what they mean.

1:05:31 JB: Optional attributes, I don't have to necessarily understand what they mean. Okay? And some optional attributes are transitive so they can be sent from one autonomous system to the next, to the next, to the next. Others are non-transitive type of attributes. So, we need to know where this route originated, we need to know what AS path it went through, who to go through to get to that particular destination network. Again, other attributes are intended to be used within a given autonomous system. And there's more than what's shown in this particular list because of the additional functionality that's been added throughout the years, giving us more and more capability within BGP. Now, the AS path attribute is used for loop prevention mechanism. And it's a mandatory well-known attribute so it always has to be there, even if it's blank. Okay? And so, the only time that the AS path is going to be blank is when we received a route from another BGP speaker that's in the same autonomous system as me. So, the AS path hasn't been added to yet because the route hasn't been advertised to an external peer yet. And so, a route that's advertised within a given autonomous system still has an AS path that's blank. The attribute is there, it just doesn't have anything in it.
1:06:53 JB: But I look at the AS path when I receive the route to see if my AS number's in the path. Great. I need to know how to get to the devices advertising the route. Now, the originator ID, the route source is different than the next hop address. And so, the route source is the . . . The update source is the IP address that is the source address of the packet that is sending this BGP update. The next hop attribute is who do I have to go through to get to that particular destination. And those values can be different, okay? So, they could be me, as a router, and so I'm using my loopback interface as the update source, but my next hop address might be my physical interface instead, and so something that's directly connected. But it could also be another router. And so if we're all on the same multi-access network, we're all in the same land segment, and we're all part of the same subnet, and you and I have a relationship, and then I learned a route from another router that's on the same subnet as you and I, then when I advertise a route to you, it's coming from me and it has my update source, but it may still have the next hop of the other router.
1:08:13 JB: Because why do I need to change the next hop attribute? I don't need you to go directly to me to get to the other router. You can go direct to the router, you're on the same subnet. Now, if policy, like security policy says that, "No, we don't want that to happen. We need you to go to me before you go to the other router that's on the same subnet," then we can change the next hop attribute if we need to. So again, all this stuff is things that we can manipulate. We can change all these different attributes. So the AS path we use for our loop prevention mechanism, and if there's no AS loop, so the route is considered to be okay, then we put it into our BGP table, and then the next thing that we look at is the next hop attribute. Do I know how to get there? So, do I have a route to get me to the next hop for that route? If I can resolve the next hop attribute than that route is considered to be a good route, and it could be considered then for best. The best route is the one that I'm going to potentially use for myself, for forwarding traffic, it's the one I'm on to advertise to my neighbor through BGP.
1:09:31 JB: And so, each route needs to have at least . . . Well, each route has to have one best path selected. Okay? And so, we had to make sure that we can actually resolve that next hop attribute. Now, if I only have one way to get to a given destination, so I've heard from one neighbor to get to one destination network, and there's no AS loop and the next hop is reachable, I'm done. That route gets selected as being best, I'm good to go. Now, if I have more than one way of getting there, then we use the attributes as a tiebreaker to determine the best path. So, I've got two or more routers, two or more BGP speakers, that are advertising the same network to me. So, then I have what I like to refer to as my 12-step program to be able to determine the best path to get to that destination. So again, to even go into the BGP table to begin with, there can't be any AS loop. So, I've checked that, there's no AS loop, I'm good to go there. The next hop attribute is something that I can resolve against my routing table. So, I know how to be able to get to the next hop attribute. Synchronization is an IBGP feature. I use feature as kind of . . . Yeah. In my mind, it's more of an issue. And for most people, it's considered to be an issue. And then synchronization is disabled by default. What synchronization says is do not accept an IBGP learned route unless it's already in your routing table. Okay? So, let me restate that.
1:11:06 JB: So, what synchronization does is it basically, if I receive an IBGP learned route, then I have to go look up this route within my routing table to see if I already have any information in there. So, do I know this thing through OSPF, or IS-IS, or EIGRP, or RIP or static? If I see it already in the routing table, then I can go ahead and consider this for best. If I don't see it in the routing table, then I can't consider it to be best. And the reason for that is if I come back over here to there, what if I've got multiple routers in between these two IBGP speakers and they're not running BGP? And so, the idea behind synchronization is don't just blindly accept routes coming in through an IBGP relationship. We need to know that the underlying routers can forward this traffic that's related to their routes, so they have an entry in their routing table relative to that. Which basically means then if their route came in over here from some external peer then we would have to redistribute that into the IGP to make sure that all the routers in between know about it, and then this box over here would also be running, let's say OSPF.
1:12:23 JB: And so, it would learn through OSPF. So now when I see there's an IBGP learned route, I can synchronize that against my IGP table and see that, "Oh, okay, I have an OSPF version of that route," so I can advertise that route then to others. Because when we get traffic then, I know that there's a natural path for that traffic to flow. The problem is nobody in their right mind is going to redistribute BGP, especially for internet, into your IGP. None of the IGP is going to be able to scale those kinds of numbers, so we just don't do that. So, we typically, if we're doing something like this, the most common implementation today is that we're running MPLS in between these boxes over here. And MPLS is essentially an encapsulation or tunneling protocol, and one of its functions is to hide the payload from the intermediate routers. And so, they just see the labels to be able to get us from router edge to router edge, and that's it. They don't see what the actual payload is, and so synchronization has no place any longer, because the intermediate devices don't really need to have the explicit route, because MPLS hides that stuff from those intermediate routers. And so, synchronization is not something that we worry about any longer, and synchronization is disabled by default.
1:13:43 JB: So, assuming that there's no AS loop, assuming that the next hop is reachable, assuming that either synchronization is disabled or it's an EBGP relationships that we're dealing with here, then synchronization has no meaning. And again, if I only have one possible path, I'm done. I'm going to pick that as being best, and I'm good to go. But if I have more than one possible path to get there, then we go through these steps until I find a tiebreaker.
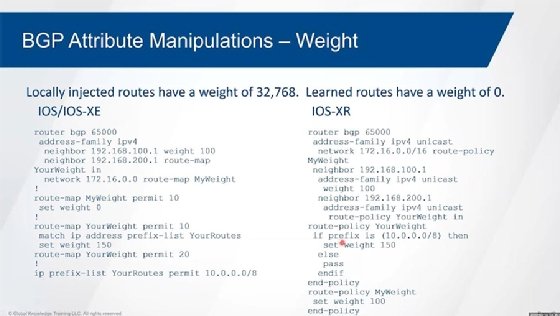
1:14:11 JB: And the first tiebreaker I find, I'm done. Okay? So, weight is a local attribute. Okay? What I mean by that is it's not something that's actually advertised between routers, it's just something that I apply when I receive a route coming in. And the highest weight is best. Okay? And so, by default, if I'm injecting a route into BGP, either through redistribution or through a network command, then the default weight is going to be 32-768. If I learn the route from some other BGP speaker within the same autonomous system, from external, doesn't really matter, the weight's going to be zero. So, the highest weight's going to be best. Okay? If the weights are the same, so I'm learning it from two different peers, then they're going to be zero. And then I look at local pref. Okay, local pref . . . Highest local pref is going to be preferred. Now, local pref is an attribute that's only used within an autonomous system.

1:15:12 JB: So, when I learn an external route from an external peer, then there's no local pref tied to it. I'm the one that's going to apply the local pref to it because I'm going to advertise that then within my autonomous system. If I'm hearing the route from an internal peer, then the local pref has already been applied. The default local pref is a 100. Higher numbers are better. If local pref is the same, then I look at locally originated routes. Okay, so if I'm injecting the route and I'm learning about the route from another peer, then I'm going to prefer my own over the other neighbor. Well, but I thought I said that weight is automatically going to be 32-768 if I inject the route. Well, again, weight is not something that's advertised, and technically weight is not an official attribute at all. It's not part of any RFC, it's something that Cisco introduced.
1:16:04 JB: And I speak of Cisco like a person, but somebody at Cisco is the one that introduced the idea of weight into the process because of this issue right here. Because without weight there, then it's possible that another router within my autonomous system is advertising my route back to me, and they've raised the local pref. So, I will prefer them over me, even though I'm the one that's injecting the route. So, they add a weight there as a way to be able to kind of get around that particular problem. But what if we're both advertising the route and the other route is the primary? Well, again, just about everything can be manipulated within BGP, including the weight, and so we could change the weight back down to zero for a route that we originate, and then we can use the local pref to steer us towards the primary device's version of the route.
1:16:56 JB: Now, if that device goes down or whatever, then our version of the route can kick in. If that doesn't apply, then we look at the AS path again, but now we're looking at the AS numbers as hop counts, and the shortest path is going to win. If the AS path is the same exact number of AS hops, then we go to, "Okay, how did the route get into the process to begin with?" A network command is more preferred over redistribution. And so, the origin code tells me whether or not it was done through a network command, or it was done from redistribution. The origin code for a network command is I, which stands for "IGP." Redistribution is a question mark, which is known as "incomplete." There's nothing wrong with redistribution, it's just less preferred than the network command, that's all. And you might find in some documentation where they talk about E as an origin code, and that was actually in between. So, it was I over E over question mark. E was when you redistributed EGP into BGP, but EGP is not supported any longer.
1:18:05 JB: Cisco hasn't supported it for years, you don't see that origin code any longer, so we just talk about I versus question mark. If the origin code is the same, then we look at Multi-Exit Discriminator. The MED is, how do we influence others to return to us? So, it's considered to be a fairly weak attribute. Cisco actually refers to this in the BGP table as the metric, so you'll see a column there that says metric, and that's MED. And it's only looked at between directly attached autonomous systems, so we would have to have multiple points of contact between the same autonomous systems for MED to be meaningful. And we're trying to influence on the return path.
1:18:51 JB: MED is typically not used. It's typically ignored. AS path is the one that we typically manipulate for the return path. So we do something called AS pre-pending and we make the less preferred path look longer than the more preferred path, and so that's how we typically influence others to return to us, we don't use MED. We have what's referred to as the "Hot Potato" rule, and so we prefer external peers over our internal peers. And the idea behind this is that we want to use somebody else's bandwidth over our own so we go to . . . So if I'm here about the same route from EBGP versus IBGP, I'm going to go to the EBGP peer over the IBGP peer. If they're both the same type, they're both EBGP peers, they're both IBGP peers, and I'm having to route myself to the neighbor, whichever one's cheaper to talk to is the one that I'm going to use. It's the lowest metric.
1:19:47 JB: Now, if it turns out that I know to get to one peer through OSPF and another peer through EIGRP, then I can't compare the metrics, they use the administrative distance as a tiebreaker. Okay? If everything is the same through step eight, then I can consider multi-path forwarding in the routing table. So what am I going to inject into the RIP for forwarding traffic for myself? But I still have to select one best path. And so, the BGP table is, "What am I injecting into BGP, what am I learning?" And then the best is, "What am I going to advertise to others?" Now I can only select one best path per destination. That doesn't mean that I can't use more than one for myself. And by the way, the maximum path on Cisco boxes, all of them is set to one for BGP. So, it will only select one route to go into the routing table, and that's going to be the best path that's going to advertise to others. If you change the maximum paths to be something greater than one, I can put more than one entry in the routing table if everything's equal through step number eight over here, but I'm still going to pick one best path. That's the one I'm going to advertise to others. You're not going to find in the BGP table more than one entry marked as being best for the same destination.
1:21:10 JB: I look at age. Now because I pick up on things based off the scan interval, the assumption then is that the routes need to be at least a minute older than each other for age to be applicable. If I learn about the route from two different peers, from two different sources within the same scan interval, they're considered to be the same age. So, they need to be at least a minute apart for age to matter. If that's the same, then the lowest router ID wins, or originator ID if it's being reflected. If it is being reflected and we're going through multiple route reflectors, every time we go through a route reflector it adds to the cluster list. So, the shortest cluster list is going to win. If everything's equal through step number 11, this basically means that we're directly attached to this other router twice or more.
1:22:05 JB: And so then we look at the next hop addressing, and the lowest next hop address or neighbor address is going to be the tiebreaker. So, we will find a tiebreaker. Take a look at a few of these real quick here, how we manipulate these attributes. So, some of the more common ones. We can manipulate weight to influence us on how we're going to get to a given destination. Again, the default is 32-768 for things that I inject myself, zero for everything that's learned. And so we use . . . Well, we can either use the route map, or we can apply weight directly. And so here we're applying weight directly to a neighbor. Here I'm showing a route map that I'm applying inbound that's then looking at this route map that is . . . So your weight, and so it's actually setting a weight based off of a prefix-list.
1:23:00 JB: So, I match on whatever the routes are within the prefix list, and I set the weight to be 150. Now the second statement here that doesn't have anything in it means match everything, but then since there's no set command, don't manipulate anything. The default weight will get applied to everything, this one's the only one that's going to get a weight of 150. Now this one over here is applied against the network command, and this is how we change the weight then from 32-768 down to zero. On the XR platforms we do it through route policy language. So, we have the equivalent over here, we don't do a prefix list, we do a value set, or in this case, we're matching on a specific prefix so we can do that within the route policy language itself. We're setting the weight. And it uses if-then statements, if-else statements. So if this, then that. Else, let everything else pass.
1:23:55 JB: And then we have a route policy for my weight to just change the weight to be 100 in this case over here. And then when we take a look at the BGP process over here, we have the network command that has a route policy applied to change that from 32-768 to, in this case, to 100. We have the neighbor statement over here. That one's got the weight set to 100, for everything that we learned from that neighbor is going to be set to 100. This guy over here, we have our route policy applied to it. So, if it's the 10 address base then change that to be 150, everything else then it will be a default of zero. To be able to manipulate how we leave the autonomous system, we would use local pref for this. This is the most common on how we leave the autonomous system. So again, we use by default 100, we can either set the default local pref, so we can prefer one exit point over the other.
1:24:54 JB: So, we want this one over here to be the primary, this one to be the secondary. We can just say, "Okay, set all things to be 150 instead of 100." 150 is higher than 100 so that's going to be more preferred. Or I can manipulate it through a route map. And so in this case, again, I can match on a prefix list, I can then set the local pref to be something greater than 100. This allows for everything else to go through. Route policy language, doing the same thing over here, matching on the prefix, setting the local pref. If it's not that, then pass everything else without any manipulation. Or we can just set what the default's going to over here, change what the default is from 100 to 150.
1:25:36 JB: Using MED... Actually, sorry, this is AS path pre-pending. So again, this is more common to be able to influence. So, we want the return path to come this way, not this way over here. Then what we can do is we can do AS pre-pending to be able to make that happen. And for the path that is going to be the less preferred we're going to add AS hops. We do this through route map, or we do it through route policy language. Again, slightly different syntax over here. Within the route map we're going to match on this AS path so we're using a regular expression. In this case, we're matching on everything that's locally originated.
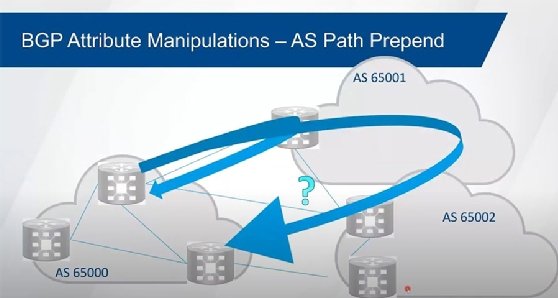
1:26:14 JB: So, the caret means beginning of line, dollar sign means end of line, so everything that's local AS stuff. There's no AS number yet on the path, then what I'm going to do is I'm going to add three AS hops to it. Now when we advertise the route, we always add our AS number to the path. The receiving router will actually see four AS hops, not three; the three, plus the normal one that we add to it. And then we're adding this then as a route map outbound towards this neighbor, and this would be the less preferred path then. So, we want to go through the other neighbor, through the other path, we want the return path. On the XR platform, route policy language basically doing the same thing. Again, now we don't have to do this regular expression thing, we just say okay it is local. So that's our local stuff. And we're adding then 65,000 three times. So, this is a multiplier times whatever this AS number is.
1:27:11 JB: And then, for everything else we're just going to allow it to go through. MED, which again is not very common, is between multiple attachments between a pair of ASes. So, again, route map, we're going to manipulate the metric. Now, we can change the default metric, and the default metric is going to be either... If I'm redistributing stuff in there it's going to be whatever the IGP's metric is, if we do a network command it's going to be zero. But MED is a non-transitive attribute, even though it is advertised between different autonomous systems. What this means is that this receiving AS is not allowed to advertise my MED to the next AS. So yeah, we're going between these two different autonomous systems and AS 65,000 is trying to influence 65,002 for return.

1:28:02 JB: So, we can either change the default metric, or the more common way of doing this is we use a route map or route policy language to set the metric based off of specific routes. And so again, we're matching on our internal routes, all of them, and we're setting the metric to be some value. And then anything that's not ours we're not setting what the value's going to be, we're just passing through with no MED. Again, the lower number is going to be preferred. The thing about it though is again we don't tend to use this very much. We tend to use AS pre-pending as our method to be able to manipulate the return path. Because this one only influences directly attached autonomous systems, it's not really . . . It's not something that really influences the internet. We use AS pre-pending instead because this can be passed then through the internet and we can influence the entire return path from the internet back to you.
1:29:00 JB: How do we know that BGP is working okay? There's a handful of commands to look at. I tend to jump on to the summary commands first, just to see that the neighbor relationships are up and running. You can get a lot more detail by taking a look at the neighbors, but again, if I'm just looking for a quick and dirty that my neighbors were configured, that they're up and running, then the show IP BGP summary, show BGP IPv4 unicast summary shows me that information. If I want to take a look at the BGP table, what's in there, show IP BGP, show BGP IPv4 unicast . . . They're going to show me the entries of the BGP table, I can see what's best, what am I receiving, what am I injecting, what am I advertising to others. Again, on an address family basis, so there's more to that if you're running different address families.
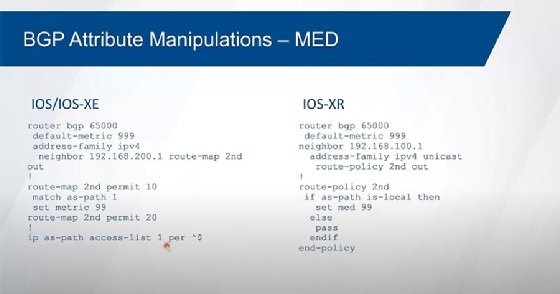
1:29:55 JB: So, a couple just examples here. I know the slides are kind of busy, but IOS/IOS XE over here, when you do the show IPBGP summary you get some basic information about BGP, how many routes within the table, how much resource is BGP consuming. The thing I focus in on is this stuff down over here at the bottom, because this tells me that I've got this neighbor configured, so if the neighbor's not there it's not configured. Period. Okay? If it is configured and it's not operational, then it'll still be here, it'll just tell me that it's not operational. It'll show me that the thing's not up and running. And I just realized that there's a piece of this that got cut off from my slide. So, this should say "state/prefix received" over here. So, a prefix count. That last column over here actually has two meanings, depending on the state.
1:30:52 JB: What I look for here is I look for the neighbor, what version it's running, what its autonomous system number is, and then I jump over here at the end and I look at this last column. And this last column, again, it should have two titles over the top of it, and the next version of the thing shows it. But this one should have state and prefix received, and the prefix count. If you see a word out here, words are bad. Numbers are good. Very black and white. Because if you see a word out here then the neighbor's not up. And you'll see "idle," you'll see "active," you might see "connect," you might see "open sent," but you won't see the keyword "established." Established is good, okay, that's when the neighbors are up. And when you do a show IP BGP neighbor or a show BGP IPv4 unicast neighbor, you'll see that the neighbor state is established when they're up and operational. So that's good. Active means that it's . . . Basically, it's tried the three-way handshake for TCP, but we're not getting the open message successfully handled.

1:32:01 JB: And so, there's something that's misconfigured relative to BGP between the two peers. Or the neighbor is not really configured to talk BGP to me. So, there's some misconfiguration that's done there. If you see "idle" there then you're either between attempts to form the relationship, or there's no route to get me to this neighbor, not enough TTL to get me there, something along those lines. The interface might be shut down that I need to use to be able to get to that neighbor, then I'll see an idle state over here. So, if you see a number over here, even if it's zero, that's better than a word. Because that tells me at least the neighbor relationship is up, I just haven't gotten any routes from that neighbor yet. But then, yep, you'll see how many routes I'm actually getting from that neighbor.
1:32:46 JB: "Show IP BGP" shows me what the BGP table is, and it will show me all the entries. The asterisk means that the route's valid. Technically, that really means . . . So that's what it says here, but what it really means is that there's no AS loop. Because I've seen routes that will go into a BGP table that has no AS loop, but that's never selected as being best because we can't resolve the next hop address. How is a route that has an invalid next hop address a valid route? But okay, it'll be marked with the asterisk but you won't see the greater than symbol. The greater than symbol over here is the best route. And so, the one that doesn't have a route or a next hop that's reachable then will never be selected being best. And then the route next hop. Now, if you see all zeros, I'm the originator of the route and things aren't quite lining up here. The zeros should be underneath the metric field, it's not in the right spot over there. Sorry about that. It's not lined up properly.
1:33:52 JB: So, if I just do that, then okay. Then it lines up a little bit better over here. So, I have my metric that's zero, no local pref because I'm injecting it and I'm going to assign the route. If I'm the one putting the route into the autonomous system, I'm going to use my default local pref. And so, it'll assign a local pref of 100. You won't see it when you do the show IP BGP. If you do a show IP BGP on a specific route then it'll show you that you're assigning the local pref of 100, or whatever the default happens to be.
1:34:29 JB: Then the weight, I'm injecting it, 32-768. This one is being learned. Over here, there's no AS path. Now, that I is not in the wrong spot, that's actually correct. There's no column for this, but if you see an I at the end over here that means that this is the origin code. Okay. And so that just basically indicates that somebody did a network command to get the route into the BGP process. So, that's the IGP origin code that's over here. Now, if you see an I right over here that means that it's learned through IBGP. So, you can see I's in two different spots. So, there's the origin code. And it still talks about E over here, but in the newer code you won't see this any longer. But yeah, you shouldn't see an E. So, either an I or a question mark.
1:35:16 JB: On the XR platforms, again, you can do a show BGP. Now, again, over here I said that the command was show BGP IPv4-unicast summary, which is actually the correct command, but this actually works. And so if you do this, then it actually gives you the same exact output. And again, I've . . . Just to save a little bit of real estate I cut off the top part that showed how many routes, how much resource are being consumed, stuff like that. I'm just looking at here's the neighbors, their autonomous system number over here. You can see that one of them is up and operational here, and I've got a couple of routes. This one over here is in idle state. And then the up-down time is just how long has the neighbor been up or down. And so this one over here with all zeros basically indicates to me that it's never been up. Because it's down right now and it's never been up. If it was up and then went down, then it'll tell me how long has it been since the last time it was up. So, it's counting the last state change. Over here, we should see that same type of behavior. Again, this one, I only have the one neighbor, it's been up now for an hour and 33 minutes. Sorry, one minute 33 seconds. This will change by the way -- hours, minutes, and seconds to days, and weeks, and months and years -- if you start getting into those kind of numbers.
1:36:38 JB: And then show BGP or show BGP IPv4 unicast will show the exact same output. Again, we have some routes over here. All these are actually learned routes. And you can see the lower case I over here. And over here we got question marks for the origin code. Again, you interpret the output the exact same way as what I described earlier.
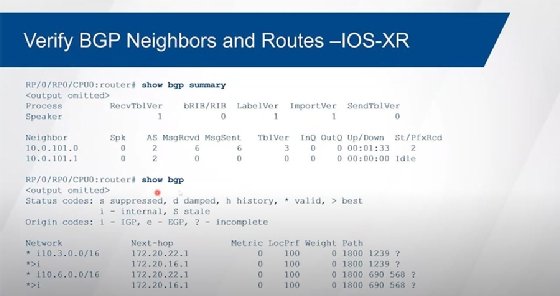
1:36:58 JB: Alrighty. So, that's basically BGP in a nutshell. And BGP is a pretty important little protocol. Border Gateway Protocol makes the internet work, so for most, that's kind of important to us. It also helps us with large enterprise as a core protocol in the provider space and things like that. There's a lot of flexibility to it. We're kind of scratching the surface of this, I can go on for days, and days, and days on BGP. Thank you for attending. I appreciate you listening in. There's my contact information. If you have questions for afterwards, you can feel free to email me. You can find me on LinkedIn. You can follow me on Twitter.






