Observability vs. monitoring: What's the difference?
Although observability and monitoring are different concepts, they aren't mutually exclusive; both provide IT administrators with valuable insights on their systems.

Observability and monitoring might sound like the same thing, but the two terms are actually quite different from one another. Observability and monitoring are both frequently used in IT, but they serve different purposes.
What is monitoring?
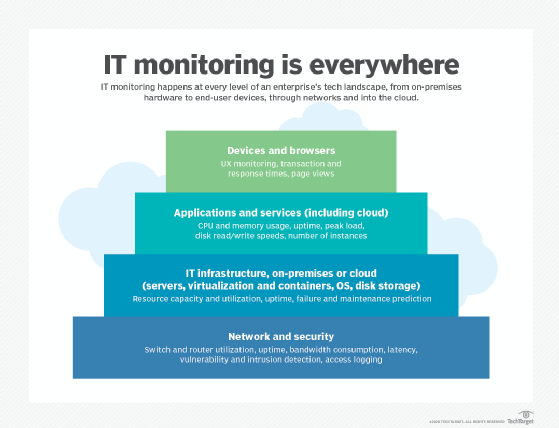
Monitoring essentially refers to tracking the state of an application or a system. There are two main reasons why organizations use monitoring.
The first reason is trend analysis. Trend analysis uses monitoring data to spot long-term trends. In the case of an application, this might mean keeping track of how the application's performance changes over time.
Trend analysis is also useful for infrastructure capacity planning. For example, organizations typically track storage consumption as a way of estimating when they must add supplementary storage resources to avoid running out of storage space.
Monitoring is also used for event detection. Monitoring systems are often paired with alerting mechanisms that can draw an administrator's attention to errors, security incidents or other conditions that might need to be dealt with. It's unrealistic to expect an administrator to be able to spot every potentially problematic condition in real time, so automated monitoring and alerting is an important part of keeping applications and infrastructure healthy.
This article is part of
What is observability? A beginner's guide
What is observability?
Observability is a technique often used to assess the health and performance of IT workloads. It works by aggregating data from a variety of available sources -- such as logs, metrics and traces -- and then using that data to derive information about the system's overall health and performance with the goal of providing a better overall user experience.
Observability tools are rooted in control theory, which loosely states that it's possible to understand a system by examining its inputs and outputs. As such, the key to making observability work is to figure out which conditions to observe to derive a meaningful assessment.
Although the resulting assessments can be high-level, they usually tend to be more granular, focusing on the individual building blocks that make up a distributed system or application. In fact, observability techniques are often used by root cause analysis tools.
Observability is often described as consisting of three pillars: metrics, logs and traces.
Metrics. Essentially, metrics are just measurements of a particular resource, such as those metrics gained through performance monitoring. For example, database metrics might be based on the number of transactions occurring each second. Similarly, OS metrics might examine the percentage of CPU resources in use or the amount of memory that is currently being used. Metrics give IT pros a way of knowing what values are normal for a particular system so abnormal conditions can be more easily recognized.
Logs. Simply put, logs are automatically generated records of various types of events. Log contents vary by system and by log type. Some logs are general in scope, while others focus on something specific, such as security or a particular service or application. Logs generally contain errors, warnings and relevant events. These events might include things such as user logons, a service starting up or a particular resource being accessed.
Traces. Sometimes referred to as distributed traces, traces are designed to track the way application or infrastructure components work together. An application trace, for example, might track the way various application components are used when performing a particular task. Similarly, a network trace tracks packets as they flow across a network.
How are monitoring and observability related?
There are similarities between monitoring and observability. For instance, both monitoring and observability seek to give IT professionals better insight into the health of the systems they oversee. Monitoring and observability are also sometimes based on the same sources of information. This can be especially true for logs and metrics.
Monitoring vs. observability
In some ways, observability could be thought of as an extension of monitoring. After all, both monitoring and observability use available information as a way of helping admins better understand what's going on with their systems. However, monitoring tends to be a bit broader in scope, whereas observability is more focused on a system's current state of health and functionality. In doing so, observability solves a key problem.
Monitoring is great for detecting problematic conditions or for spotting long-term trends, but it isn't the best tool for troubleshooting problems with complex systems. Although the root cause of the problem might be revealed within the logs that are being monitored, sifting through those logs can be tedious and time-consuming, and the people reviewing the data must have some idea of what it is that they're looking for. When observability is used, it becomes far easier to pinpoint the individual component that is causing the problem.
Choosing between the two
Although it's only natural to wonder which is best, remember that monitoring and observability serve two different purposes. Monitoring tends to be best suited for long-term trend analysis and alerting to potentially problematic conditions. Conversely, observability might provide greater insight into system health and can help an organization be more proactive in dealing with issues before they become a problem.
The key takeaway is that monitoring and observability aren't mutually exclusive. There is no rule saying that an organization must use one or the other. In fact, an organization that wants to achieve the optimal insight into its IT systems might use both. Likewise, an organization might find that monitoring is a better option for some workloads, while observability is the better choice for others.







