
Getty Images/iStockphoto
How machine learning strengthens incident management
As systems failures pile up, machine learning stands as an alternative to improve response quality and save money. Learn the benefits and drawbacks to the approach.

Digitization, AI and machine learning lead to complex autonomous and adaptive systems that operate with little-to-no human intervention. While such systems are potent drivers of business growth, they are incredibly challenging for IT and DevOps teams to debug and diagnose in the event of infrastructure or application failures.
And the financial ramifications of any system failures have multiplied, as these "smart," data-driven applications are now central to business operations. Thus, it is understandable, yet paradoxical, that to manage and debug modern IT infrastructure increasingly requires machine learning (ML) to identify, diagnose, fix and prevent problems.
Automated incident management and AIOps
Machine learning for incident management is a subset of AIOps, a process in which AI is applied to a wide array of IT operations tasks.
Many of those tasks fall under event correlation, analysis and incident management, where data analytics and ML modeling can reduce significantly the time required to diagnose and fix problems when applied to an aggregated repository of system, security and application data. Furthermore, by encapsulating subject matter expertise and with powerful mathematical techniques, machine learning-augmented IT support software improves the quality of incident response output in systems usable by less experienced IT support professionals.

Problems with modeling data
The wide variety of causes for a service or application outage require distinct approaches. Causes include configuration changes, software updates or patches, equipment failures, external network congestion -- for applications that rely on cloud services -- or malicious attacks, such as distributed denials of service, data corruption or system compromises.
Various approaches to these scenarios typically fall into a few categories:
- Data clustering and correlation. To associate similar events and link cause to effect. For example, a configuration change to a network outage due to improper routing information.
- Anomaly detection. Detecting any unexpected divergences from the continuity of data streams or normal patterns.
- Data fitting and prediction. Using both traditional and more advanced statistical methods.
- Deep learning. Consisting of training neural networks on known, categorized data and using trained models to analyze new incoming data.
Incident management software uses various types of machine learning models, including:
- standard statistical methods like z-score or t-score;
- linear and logistic regression;
- generalized linear models, an extension of traditional regression techniques for data with non-normal distributions and includes techniques like ANOVA (analysis of variance);
- ARIMA, or Auto-Regressive Integrated Moving Average, for time-series predictions;
- support vector machine, for classification and pattern recognition;
- local outlier factor, for anomaly detection;
- elliptic envelope, for anomaly detection;
- gradient boosting machines, which are powerful predictive models, but computationally intensive;
- isolation and random forest, anomaly detection via clustering;
- K-NN and K-means, for nearest neighbor clustering and anomaly detection;
- auto-encoders;
- deep learning; and
- transfer learning, which applies existing trained models to new types of data.
Example of supervised learning for problem identification
Many machine learning-enhanced incident management systems start with problem identification and classification techniques similar to the rules-based AI popular in the 1980s.
Those a priori approaches -- or those based on facts irrespective of experience -- have evolved to a posteriori data-based systems -- based on experience -- using ML modeling and the vast troves of system, event and performance data generated in today's data centers. For example, a machine learning-powered incident management system might use a classification model trained on a historical incidents database to predict if a new configuration change triggered a particular incident.
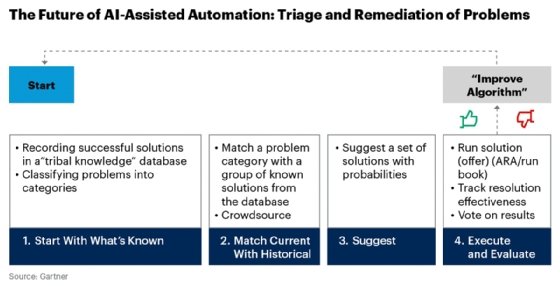
Machine learning-enhanced incident management software supports several levels of automation that are similar to the categories defined for autonomous vehicles, namely:
0. No automation. All processes are conducted manually by IT staff.
1. Admin assistance. The system filters data, such as critical events and alerts and identifies probable causes and suggests fixes.
2. Partial automation. Systems correct some common problems unattended, such as a system reboot or a failed system power-cycle -- or executing a script that completes a previously manual workflow.
3. Conditional automation. Systems perform unattended applications of hotfixes and corrections of more complicated issues via workflow automation.
4. Full automation. A closed-loop process predicts problems, such as resource constraints, component failure or security issues, and proactively addresses them through configuration changes, software updates and adding new resources. While fully automated systems are the dream of every AIOps vendor, the technology is far from perfected, and such systems are many years away.
Benefits and risks for IT administrators
Machine learning-enhanced incident management software increases the proficiency of less experienced admin staff, reduces the time to resolve incidents, assists in post-incident review and root-cause analysis and reduces the overall stress on operations center teams tasked with monitoring hundreds of systems, each streaming gigabytes of data every minute.
The risk of any such automated system is in the software itself -- namely, that the machine learning models are developed improperly, tuned inadequately and applied indiscriminately. In the worst-case scenario, AI automation run amok could deluge operations staff with alerts -- called noise at such volume -- misidentify root causes and apply inadequate or inaccurate patches or configuration changes.
Thus, for the same reason that airline autopilot systems must undergo rigorous and lengthy testing, AIOps and machine learning-imbued incident management systems should be tested in low-risk environments before deploying them gradually to critical production systems.







