
Develop an interactive DevOps runbook
Runbooks are important for DevOps processes -- simple or complex -- but they can be a beast to write. Use this expansive guide for best practices and arrangement.

You can't improve -- or optimize -- what you can't measure. Translated into software development and DevOps terms: You can't automate what you can't document.
A DevOps practitioner must understand and describe the steps -- and their sequence -- required to complete a task before automating it. Without a comprehensive understanding of each step and its expected result, it's impossible to create a repeatable process. These maxims are solid reasons for DevOps organizations to create a runbook.
What is a runbook?
A runbook is a written set of standardized procedures to automate repetitive IT processes covered under ITIL protocols. Although the terms runbook and playbook seem synonymous, there is a clear distinction in the context of DevOps:
A runbook focuses on the workflow for a single process, whereas a playbook describes the overall responses to a much broader issue. For example, a DevOps organization might have a runbook for deploying an updated version of an application or service container to an AWS Kubernetes pod. In contrast, DevOps teams and site reliability engineers (SREs) use a playbook to recover from an outage at a cloud region -- such as the one that took AWS US-East offline for more than 8 hours in early December 2021, where it runs many production applications.
Runbooks have many uses, for example:
- Document processes for IT incident management and troubleshooting.
- Improve system reliability and security to reduce downtime.
- Optimize IT and DevOps operational tasks.
- Serve as templates for automation routines that eliminate manual process steps.

And, as organizations replace manual processes with executable code, runbooks will evolve into a mix of manual and automated steps.
Elements of a DevOps runbook
DevOps runbooks encapsulate and systematize steps to address frequently encountered issues. They should observe qualities iteratively referred to as the "five A's:"
- Actionable. Address purposeful steps required to resolve a problem, not hypothetical reasons behind it.
- Accurate. Test procedures and validate for accuracy and completeness.
- Authoritative and unambiguous. Each runbook should cover only one process; it should also feature clear instructions for DevOps teams to treat it as a single source of truth.
- Accessible. Communicate in direct language. Practitioners often access runbooks because a problem has arisen. Language must be easy to follow, readily available and easily found by the target audience.
- Adaptable. Runbooks are a single source of truth that define the steps of a process, but they must also exhibit flexibility to improve with instances of contextual experience. They must also be able to address new situations and technologies.
Creating a DevOps runbook that meets these qualities requires a disciplined process of planning, research, writing code -- for automated routines -- testing, feedback, optimization and updates.
Much like a cooking recipe has several elements, such as a list of ingredients and their amounts, a sequence of steps for mixing the ingredients and instructions on cooking the final product, a DevOps runbook has several components. Just as a thorough news article should address the Five W's of Journalism, a runbook should address a similar set of objects:
The five W's -- but for DevOps runbooks
What and when
This section identifies and confirms the problem. It also details timestamps for an action or incident and the subsequent resolution activity. Additionally, it includes the tools and information sources -- such as monitoring sites and dashboards -- and pointers to the location of instructions on their use. Useful information in this section includes:
- incident timestamps;
- hours of use (24/7, 10/5, etc.);
- support team availability (24/7, 12/7, etc.);
- maintenance or downtime windows;
- pointers to tool repositories; and
- recovery time objectives.
Who
This is a list of people responsible to address the problem, those on the escalation path -- second- and third-level support teams -- as well as contact information for key stakeholders affected by the issue, such as line-of-business managers or application developers, for example.
This section collects information such as:
- System, application and business owners or stakeholders
- Escalation contacts, both within the enterprise and for third-party -- i.e., vendor -- support organizations
- Include the preferred contact method for all listed parties, such as voice call, text messages, email lists, ticketing systems or web forms.
- Access authorization information and procedures for the affected system(s)
Where
Within this section, list communication channels and information repositories -- often a ticketing system or collaboration platform -- for each event or incident. Catalog problem information, attempted remediations, the tools used and incident status, as well as a space to post questions. Other valuable data to collect:
- Links to or directory locations for relevant knowledge bases and related process documents, such as incident or change management documentation.
- A detailed description of the system or application architecture, interfaces and dependencies. For example, if describing the steps to debug database connectivity problems, include details like whether the database is replicated. If so, clarify how and where to find it; whether it is front-ended by load-balanced caching nodes; and the network configuration for links between the load balancer, caching nodes and database.
- The location of log records, such as a Splunk or Elastic Stack -- formerly ELK Stack, which stood for Elasticsearch, Logstash and Kibana -- system used to aggregate relevant event logs and metrics. Here, add in a description of the monitoring configuration and a history of -- or links to -- data, metrics and visualizations.
- Software or service licensing information, license keys and authentication information.
Why
Perform post-hoc documentation and forensic analysis of actions taken, in the case of a failure or security incident. Descriptions of those actions must include certain key data. They are as follows:
- results and effectiveness;
- proposed processes, systems, security or application improvements to streamline, such as for routine administrative procedures; and
- how to prevent or mitigate future occurrences.
In sum, describe the consequences -- either desired in the case of an administrative runbook or resulting for support process runbooks.
Some of these sections will be minor or largely missing for runbooks that describe task automation code. For those IT teams or organizations using literate programming, the code is self-documenting and can run through a text processor -- usually Markdown or LaTeX -- to produce readable documentation as an HTML or PDF file.
Types of runbooks and their uses
Back to our recipe analogy: A cookbook has different types of recipes; it follows that there are many different types of DevOps runbooks. Runbooks cover tasks like:
- system management, configuration and deployment processes;
- infrastructure and application monitoring, performance measurement and alerting;
- security processes and authorization and access controls; and
- system, application and infrastructure failure recovery.
The last item illustrates the interface between runbooks and playbooks. For example, recovering from a hardware failure or application crash fits squarely within the scope of a runbook. However, a disaster recovery process that encompasses the mass failure of many systems -- or an entire facility -- is better addressed by a playbook, which could include both DevOps runbooks and other elements, like communication and personnel or HR plans.
Runbooks fall into two broad categories: prescriptive and reactive. While both forms provide processes for a particular situation, the former describes an administrative task to be performed in a defined set of steps in a precise order, making it suitable for programmatic automation. This structure is often represented as a decision tree, with some of the steps constructed as logical decisions -- "if X is true, follow branch A, else, follow branch B" -- which direct the process flow. For example, a runbook for creating an AWS Virtual Private Cloud might be codified into Terraform HCL to standardize and automate the task of AWS network creation.
In contrast, reactive runbooks are commonly used for support processes to guide problem understanding, containment, resolution and post-mortem analysis. Such runbooks are less amenable to automation and resemble instruction handbooks more than procedural code. For example, a runbook for a system administrator's daily tasks resembles a pilot's preflight checklist and might include the following categories:
- Review any critical alerts
- Check for hung processes, automation scripts
- Review log files
- System logs
- Application logs
- Security logs
- Login activity
- Review system metrics and dashboards
- Resource usage and exceptions
- Available disk space
- Hardware alarms or error conditions
- Check status of daily system backups
Prescriptive, procedural runbooks are a prerequisite for programmatic automation and simplify the work of turning manual tasks into automated processes.
From runbook to automation script
Workflow runbooks are most amenable to automation because they run a set of inputs through an explicit process to produce a defined outcome. Thus, such runbooks are described easily by procedural languages and, when the goal is an automated script, might be nothing more than program code. Programmatic runbooks are often strung together via a CI/CD toolchain that enables IT admins to automate an entire workflow, such as compiling, integrating and deploying an application from code repository to cloud environment.
Automated runbooks are so common that they have spawned a class of cloud services like AWS System Manager or Microsoft Endpoint Configuration Manager, along with tools like Document Builder.
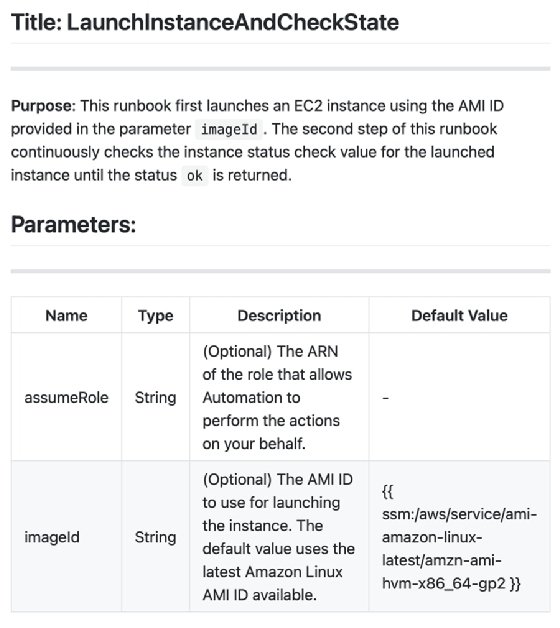
DevOps teams can use Python, JSON or YAML code interspersed with Markdown descriptions to build self-documenting automation scripts in Document Builder. For example, the following Markdown and Python code launches an Amazon EC2 instance and waits for the instance status check to change to "ok."
## Title: LaunchInstanceAndCheckState
**Purpose**: This runbook first launches an EC2 instance using the AMI ID provided in the parameter ```imageId```. The second step of this runbook continuously checks the instance status check value for the launched instance until the status ```ok``` is returned.
## Parameters:
Name | Type | Description | Default Value
------------- | ------------- | ------------- | -------------
assumeRole | String | (Optional) The ARN of the role that allows Automation to perform the actions on your behalf. | -
imageId | String | (Optional) The AMI ID to use for launching the instance. The default value uses the latest Amazon Linux AMI ID available. | {{ ssm:/aws/service/ami-amazon-linux-latest/amzn-ami-hvm-x86_64-gp2 }}
def launch_instance(events, context):
import boto3
ec2 = boto3.client('ec2')
image_id = events['image_id']
tag_value = events['tag_value']
instance_type = events['instance_type']
tag_config = {'ResourceType': 'instance', 'Tags': [{'Key':'Name', 'Value':tag_value}]}
res = ec2.run_instances(ImageId=image_id, InstanceType=instance_type, MaxCount=1, MinCount=1, TagSpecifications=[tag_config])
instance_id = res['Instances'][0]['InstanceId']
print('[INFO] 1 EC2 instance is successfully launched', instance_id)
return { 'InstanceId' : instance_id }
The Markdown description parses to the formatted text as shown in Figure 2.
Editor's note: This article on DevOps runbooks is one of the last pieces longtime TechTarget contributor Kurt Marko wrote for us before he passed away in January 2022. Kurt was an experienced IT analyst and consultant, a role in which he applied his broad and deep knowledge of enterprise IT architectures. You can explore all the articles he authored for TechTarget on his contributor page.





