
Getty Images
Decide when and how to adopt an MLOps framework
Unsure where to start when it comes to standardizing your organization's machine learning processes? Explore key considerations and practical tips for adopting an MLOps framework.

Companies across every economic sector are capitalizing on the accessibility of AI, automation and data analysis to expand business potential, gain new revenue streams and increase profit margins. Creating effective, repeatable machine learning processes is a fundamental component of achieving these goals.
As an organizing approach and an extension of DevOps, machine learning operations (MLOps) encompasses the people, processes and practices used to rigorously track model versions, analyze data transformations and retrain models over time. Companies can rely on the expertise of various IT teams working collaboratively to deploy ML models and monitor their effectiveness over time.
Organizations should consider several factors when evaluating the potential benefits and viability of MLOps for model creation, production and scalability. These include the challenges involved in adopting an MLOps framework, key aspects of cross-team collaboration and the tooling available for various stages of the MLOps pipeline.
Fundamental aspects of MLOps: Deployment, monitoring, lifecycle and governance
For effective AI implementation, it's essential for teams to know how to treat and prepare data, establish well-functioning ML pipelines, and construct and deploy ML software that follows DevOps best practices. With an MLOps framework in place, businesses can deploy models faster, enhance security and accuracy, and respond quickly when models degrade or configurations drift.
Continuous monitoring and maintenance of data and ML processes are a cornerstone of the MLOps framework, playing a crucial role in driving successful business outcomes. MLOps also relies on continuous testing, a unique approach to ML that prioritizes automatically retraining and serving models.
As data ingested by ML models in production changes over time, models must be monitored, fine tuned and recalibrated. Monitoring and maintenance include regularly adding new, customized data to ensure that models remain current and continue to benefit the business. Consistent monitoring also ensures that MLOps teams can uncover issues and repair them in time to prevent negative effects on business processes that rely on AI.
Lifecycle management ensures teams know what actions to take when issues are discovered. Should the need for troubleshooting arise, access and event logs can provide failover and fallback options. Centralized experiment tracking includes well-defined metrics that enable MLOps teams to compare alternative models and, if necessary, roll back to an earlier version.
Adherence to regulatory standards requires operational best practices and comprehensive data knowledge. MLOps frameworks can help companies ensure compliance with rules governing data storage, access and longevity.
Experienced MLOps teams also know whether a model was trained on sensitive data and how that affects use and deployment. Including sensitive, private information in training data influences how organizations can employ the resulting model for certain business initiatives.
Understanding the key components of ML pipelines
Data engineering for MLOps involves building pipelines that perform a series of extract, transform and load (ETL) processes. Through a process of refinement and testing, MLOps frameworks can create reproducible ETL pipelines for data ingestion and training.
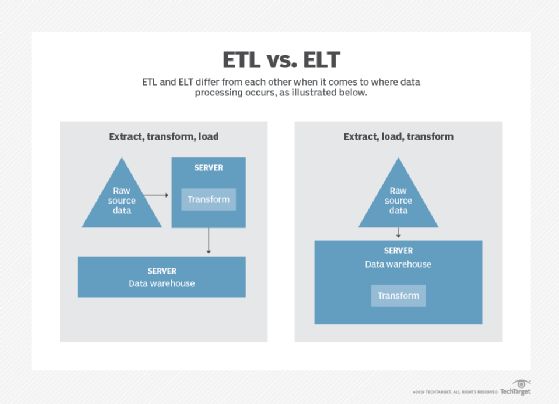
Moreover, MLOps teams can use automated multistep pipelines to retrain and deploy models, implement tracking with well-defined metrics, and gauge pipeline performance. MLOps teams can then compare model effectiveness and choose options for model rollbacks when necessary.
One option for testing is to use independent data, employ challenger models that measure predictions based on variations of the same decision logic and perform frequent recalibration. MLOps also makes it possible to deploy data pipelines and models together, automating the manual processes that data scientists originally used to create a pipeline.
Importance of cross-team collaboration
Seamless collaboration is an essential ingredient for successful MLOps. Although software developers and ML engineers are two of the primary stakeholders in MLOps initiatives, IT operations teams, data scientists and data engineers play significant roles as well.
It's critical to acknowledge that a single data scientist working in isolation cannot achieve the same goals as a diverse, experienced and cohesive MLOps team. Once cross-team operations are in place, IT leaders can ensure that communications and practices conform to a high level of interdependency and cooperation.
For example, model monitoring and testing require a clear understanding of data biases. Data scientists can conduct highly focused research on events, observe model changes and detect drift. At the same time, operations team members can employ standard and custom KPIs to monitor model performance over time, including setting up automated alerts for model degradation.
Assessing ML tools and frameworks
Organizations employ AI and MLOps tools and software to optimize data for use with the products and services they provide to customers.
Along with prioritizing model reliability at the design stage, it's critical for organizations to automate periodic model retraining. Certain ML tools can help maximize automation, streamline pipeline design, improve communication and collaboration, and ensure more reliable results.
MLOps tools are typically designed for specific stages of the ML lifecycle, such as data ingestion and preparation, model training and deployment, and verification and retraining. A variety of toolsets exist to meet these demands, each of which provides distinct features and capabilities.
Popular MLOps tools include the following:
- MLflow. An open source platform for the full ML lifecycle.
- Pachyderm. A container-native tool for automating and managing complex data processes.
- AWS SageMaker. A cloud platform for building, training and deploying ML models.
- H2O MLOps. A collaboration tool for data science and ML workflows.
- Neptune.ai. An ML experiment tracking and model registry tool.
The right toolset makes it easier for ML teams to understand model performance, identify errors and repair them in production. For example, MLflow provides a flexible, Python-compatible ML platform that can track experiments, and Pachyderm combines data lineage with end-to-end pipeline capabilities.
For companies that want to move their AI and ML processes to the cloud, options include Microsoft Azure ML, Google Cloud AI, AWS AI Services and Oracle AI. Companies that embrace a multi-cloud approach can also choose cloud-agnostic alternatives, such as MLflow on Databricks; Polyaxon, an open source platform for automating and reproducing deep learning and ML applications; and Kubeflow, a tool for running ML workloads on Kubernetes.






