An application in production has a life all its own.
An entire system of application lifecycle management (ALM) brings new software features and versions into production systematically and safely at the fastest possible pace. Things are not static from release date on, however. An application's operational lifecycle starts with deployment, after which application support and maintenance handles component scaling and replacement demands. Get this second lifecycle right, and it complements the first. Get it wrong, and even the best ALM practices fall short of sustaining business operations.
Monolithic applications demand little in the form of support and maintenance: Once the app deploys, operations teams monitor its health and replace or move the app in the event of a failure. This simple model doesn't justify a whole operational science project to mirror ALM.
Distributed applications make use of multiple components of cloud and virtualization platforms. Application health isn't tied to one deployment, but many. Virtualization and the cloud encourage elastic expansion of component instances and dynamic recovery from faults. If you draw a diagram of the dependencies for a typical core application in the cloud, it is just as complex as a development project, and thus needs equally systematic application support and maintenance.
The state of the union
The big challenge for IT operations accustomed to monolithic application support is drawing a hypothetical distributed application dependencies diagram.
Any event that is possible in a given state has to have a defined handling there, and that handling may then move the application to another operational state.
Approach operational maintenance and support lifecycles with a concept of application states. Every application exists in a specific number of states, each representing a set of components and workflow relationships. One state is usually considered the normal or base state, and all the others are responses to special conditions.
In this multi-state dynamic, application maintenance and support has two goals throughout the application's lifecycle. It must define each possible operating state precisely, in terms of component hosting and workflow connection through the network. It also must manage the application's dynamic movement from one valid operating state to another, exhibiting stable, secure and compliant behavior.
Variations from the base state occur due to workload changes, congestion or failure in hosting or connection resources. Special states refer to application operations under heavy workloads or another deviation from the norm, while failure modes represent operations in the condition where infrastructure resources fail. The production operations team uses state-event handling to dynamically control a complex application during these possible conditions.
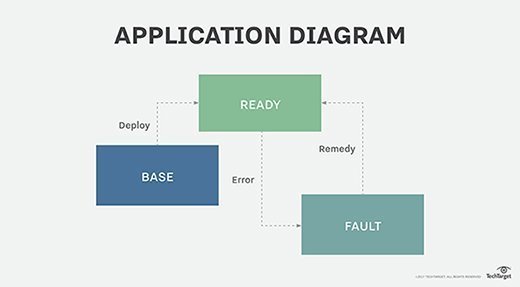
In a typical state-event system diagram, a series of ovals represents states, with arrows linking them and labeled as events that move the application from one state to another (see the figure). For example, the ready state is linked to the base state by a deploy arrow. This kind of diagram is critical to defining a complete operational model, wherein any event that is possible in a given state has to have a defined handling there, and that handling may then move the application to another operational state.
A simplified diagram shows application states and events that change its state.
Dynamic movement between states is core to modern application support and maintenance via state-event processing. Events drive the movement of an application among its described states, and that includes the states that are created by the deployment of the application itself. As in the previous example, Deploy takes the application from Ready to Base state, which might change to Scaled-Up state due to an event such as a resource addition.
The more variety of states an application could exist in, the more difficult it is for the operations professionals to ensure that these states are logical, that the application's movement among states is orderly and compliant, and that any failure-mode states initiate actions to restore normal operation.
App operations integrated into tooling
DevOps tools -- known for laying a pathway to automate deployment -- now support operational lifecycle maintenance tasks through capabilities that recognize events and model discrete operating states.
Events, in most cases, initiate in management systems for the servers, software and network. A DevOps tool handling application operations, such as a configuration management tool, must integrate these external management events, recognizing them and triggering appropriate actions. In some cases, DevOps processes themselves can generate an event, leading to a DevOps command set that essentially says: "Do this job and then generate the restored event."
To achieve true software-enabled automation of application support and maintenance -- the holy grail -- the operations team must implement the complete state-event description of an application's operational lifecycle in DevOps tooling. Continuous delivery and application availability management becomes a reality when development and change management tasks, implemented through ALM practices and tools, are integrated with DevOps-based operational application maintenance and support.
With more cloud and virtualization adoption, the imperative to manage operational lifecycles grows. These same forces demand the use of software automation to improve efficiency and reduce configuration errors. Without an effective way of managing the operational lifecycle of applications, much of the effort put into traditional ALM will go to waste.
Want to fully integrate ALM with distributed deployment management? Visualize the practices like a two-story house.
Out with the old; in with the new -- never true in an IT environment. Here's how to manage legacy app support without detracting from new, high-demand apps.