Blueprint for hybrid observability: AI and its 4 key enablers
There are four elements that create a foundation for AI-driven observability. The ability to automatically detect new or updated components is just one of them.
Intelligence and advice powered by decades of global expertise and comprehensive coverage of the tech markets.
Published: 23 Oct 2024
AI's effectiveness in IT operations hinges on the quality, completeness and timeliness of the data it processes.
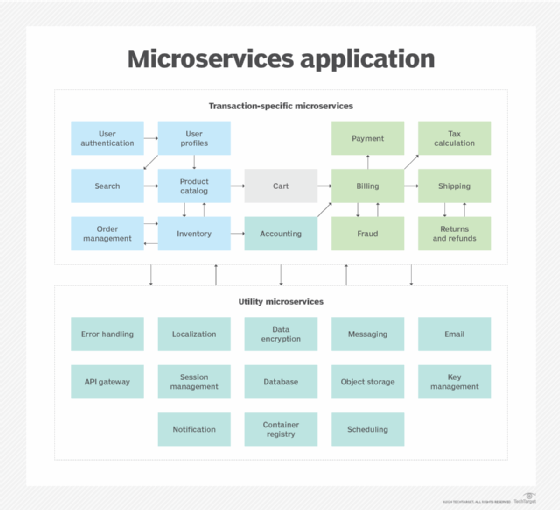
Modern applications are typically constructed from numerous loosely coupled microservices that rely on functional capabilities and data outputs from all kinds of traditional enterprise apps. Ideally, each of these microservices is responsible for one specific task, such as authenticating end users, providing search capabilities, calculating tax or shipping cost, processing payments or tracking product inventory.
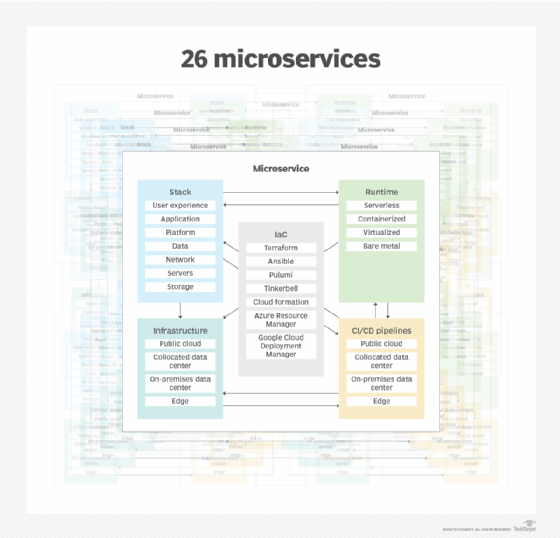
Assuming the example application in Figure 1 consists of 26 different microservices, many of them developed by different teams, we could end up with as many different application stacks, runtimes, infrastructure types, DevOps pipelines and sets of monitoring tools. Each of those might be tailored to the specific preferences of the corresponding product team. This heterogeneity increases the operational complexity of the overall application environment. Considering that microservices are often shared between multiple applications or sourced from outside providers, the challenges of ensuring consistency, security and performance across the ecosystem are further amplified.
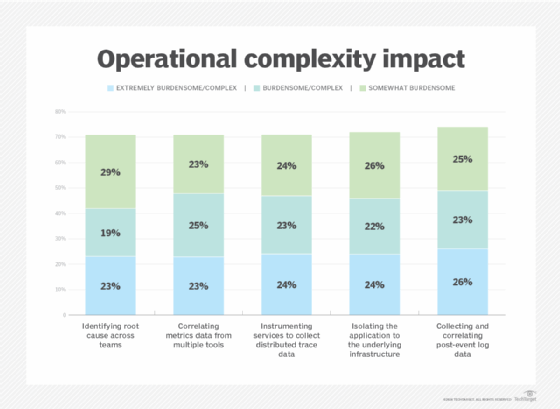
A resulting high toll is placed on corporate IT by core observability-related tasks, according to the September 2024 report "Generative AI in IT Operations: Fueling the Next Wave of Modernization," by TechTarget's Enterprise Strategy Group. In fact, a majority of organizations -- more than 70% -- felt that this complexity creates noticeable burdens on operations teams to execute many types of typical operations tasks.
Figure 1. High-level example of the topology of a microservices application.
Figure 2 highlights the resource burden and complexity associated with core observability-related tasks, as reported by IT operations teams. The majority of respondents found many of these tasks either "extremely burdensome/complex" or "burdensome/complex," underscoring the operational challenges created by distributed applications running in hybrid and multi-cloud environments.
Figure 2. The five most burdensome IT operations tasks.
These findings emphasize that while observability tools and methods are essential for managing the complexity of modern microservices applications, they also introduce substantial operational overhead. Clearly, teams are grappling with the growing complexity of ensuring comprehensive visibility across disparate services and infrastructures.
The 4 key ingredients for optimal observability
The exercise of defining optimal observability for complex and dynamic enterprise application portfolios must center around several items. First, it means determining how organizations can use their existing operations data to automatically predict, prevent, detect and resolve incidents. At the same time, organizations must continuously optimize performance and resource efficiency.
1. Hybrid observability centered on the application
Observability must cover all major technology domains -- application, container, server, storage and network -- but not only as bottoms-up, tied to the type of infrastructure on which applications are running. Rather, the observability approach must focus directly on the application itself.
Business leaders are primarily concerned with the health, performance and business impact of the application, not whether it's running on a mainframe, Kubernetes or any other platform. Their goal is to understand the business risks if an application underperforms or fails. Based on this insight, they can make informed decisions about improving the application's service-level agreement or enhancing the user experience, potentially by moving to more reliable, scalable or high-performing infrastructure. Or they might decide that the current cost-to-risk ratio is acceptable.
2. Intelligent data collection with built-in best practices
The observability platform must include built-in best practices for collecting telemetry data across the individual technologies, platforms and infrastructure components comprising each application stack. This requires detailed knowledge of the role of the individual components within the overall application environment and a deep understanding of how each component works, including what to watch out for when monitoring its health and performance.
In the optimal case, the collector should also be able to optimize the configuration of individual technology layers, based on their overall effect on health, performance and cost -- either directly or as a proxy from a centralized automation engine. For example, if the IT operations team inherits servers running the Oracle Solaris operating system, the collector should automatically discover, monitor and -- ideally -- optimize the operating system's storage and memory footprint and performance. It is important that the approach taken also enables IT operations to stay on top of legacy applications that work well and might not be a high priority to modernize but need to be observed and managed nonetheless.
3. Real-time discovery of new infrastructure and application components
In today's world of GitOps and infrastructure as code, DevOps teams can spin up, scale and terminate complex application environments as a part of the CI/CD pipeline within a fraction of a second. Catching these environments in near real time is critical for the observability platform to "understand" the effect of these dynamically generated environments on the health and performance of the rest of the application portfolio. For example, the presence of a new environment on a specific host might not affect the performance of the overall application ecosystem, but the provisioning process for this environment might lead to latency spikes and performance degradations in seemingly unrelated applications.
4. Connecting the dots between infrastructure, application stack, runtime and CI/CD
Each component of each microservice continuously outputs massive amounts of telemetry data. For example, a microservice running on a Kubernetes cluster on AWS generates logs, traces, metrics, events, heartbeat data and configuration data at many different levels: application, Kubernetes, AWS platform services, database, network, host servers and storage volumes. Searching through all these telemetry data streams to figure out the importance and the root cause of any specific incident can be like searching for multiple needles across multiple haystacks that keep appearing and disappearing. Success depends on the operations team's knowledge of the overall system and requires significant amounts of time from experienced operations engineers.
Figure 3. Each of the 26 microservices from Figure 1 comes with its own application stack, runtime, infrastructure and CI/CD pipelines.
Addressing this challenge requires the observability platform to keep track of the relationships between all the different entities that are part of the application stack. For example, consider an issue where the inventory microservice experiences latency spikes. The application logs show delayed database queries, but it's unclear whether the problem stems from the microservice itself, the Kubernetes orchestration layer or the underlying infrastructure.
Without a platform that tracks these cross-layer dependencies, operations engineers might spend hours sifting through logs and metrics in isolation, unable to pinpoint the true cause.
By correlating telemetry data across the stack, the observability platform might identify the root cause as a temporary IOPS bottleneck on an Elastic Block Store volume in AWS, which caused the database to respond slowly. This bottleneck, in turn, could have been triggered by an automated scaling event in the Kubernetes cluster that temporarily increased load on the underlying storage, or a cloud firewall rule change that created a connection barrier. Without a platform that tracks these cross-layer dependencies, operations engineers might spend hours sifting through logs and metrics in isolation, unable to pinpoint the true cause.
The optimal foundation for AI-driven observability
It is critical to understand that AI -- generative AI, anomaly detection, predictive analytics and reinforcement learning -- cannot replace the requirements for observability platforms discussed here. Hybrid observability, intelligent data collection, autodiscovery and dependency mapping are all required. They provide the AI with the data needed to generate actionable insights and alerts, automated root cause analysis, accurate predictions and contextualized responses to questions from IT users, developers, security engineers or the line of business.
In broad strokes, here is how this works:
Hybrid observability. By normalizing and unifying telemetry data across all infrastructure layers, AI gains a complete view of the system in its elimination of data silos and blind spots.
Intelligent data collection. Deep and consistent telemetry collection ensures that AI has high-quality, detailed, rich data to work with.
Autodiscovery. Automatically detecting and monitoring new or changed components ensures that AI is always analyzing the most up-to-date environment.
Dependency mapping. By continuously mapping relationships and dependencies across components, AI can better "understand" the blast radius and cascading effects of incidents, including user experience and service quality impacts.
If these needs are met, the use of AI becomes a powerful means of acceleration to accurately correlate data and events. This improves root cause analysis convergence, reduces time to restoration and presents realistic paths to proactively protect application performance and user experience.
Alignment of commercial observability tools
Enterprise Strategy Group recommends evaluating commercial observability platforms by their ability to provide the above defined foundation for AI-driven operations management. There are many cross-domain observability platforms available in the market, including offerings from BMC, Datadog, Dynatrace, LogicMonitor, Site24x7, Splunk and Zabbix. Most vendors have started with depth in one IT domain and expanded into others, often by acquisitions, and across the board offer varying degrees of completeness and depth.
Splunk, for instance, started with a core log analytics platform aimed mostly at sys admins and DevOps, but it broadened to cover cloud and networking. It has a heavy emphasis on security, from acquisitions of companies such as Cloudmeter, SignalSense, KryptonCloud and SignalFX. The result is a broadly capable tool that addresses all four pillars of observability to some extent and upon which AI is being applied.
As another example, Zabbix is an open source platform that covers all the primary IT domains and includes a long list of available integrations built by the community. It lacks some of the more advanced capabilities, such as triggered autodiscovery and continuous dependency mapping, however.
LogicMonitor's hybrid observability platform is an example of a unified tool that checks many of the boxes. The platform can automatically monitor diverse environments that can include virtual machines to containers to cloud services, as well as legacy technologies such as mainframes, AS/400 machines and dated Unix OSes. The platform includes more than 3,000 integrations, which enable it to optimize specific parts of the application stack to improve reliability and performance. Monitored assets can live on premises, in private or public clouds, or at edge locations.
LogicMonitor automatically detects the appearance of new infrastructure or application components or entire environments and can dynamically map dependencies of all corporate technology and application assets. That provides the foundation for LogicMonitor's AI assistant, Edwin AI, to offer business-driven insights and automation. Those capabilities can help teams reduce operational complexity and operator workload, while at the same time optimizing cost and performance.
Key learnings on hybrid observability
AI by itself is not sufficient for organizations to optimally align their technology investments with business priorities by utilizing an observability tool. Effective anomaly detection requires a robust baseline of normal system behavior and the ability to recognize subtle deviations across complex, interdependent systems. Without accurate and continuous data collection, dependency mapping and real-time visibility into hybrid environments, AI models can miss crucial context. That can result in false positives or inaccurate diagnoses. Furthermore, autodiscovery ensures that even rapidly changing infrastructure components are incorporated into the monitoring process, keeping AI models relevant and precise.
To unlock the full potential of AI-driven observability, organizations must invest in hybrid observability platforms, intelligent data collection practices, automated discovery and comprehensive dependency mapping. Only by ensuring that these foundational elements are in place can AI provide the actionable insights, automated root cause analysis and proactive issue prevention needed to optimize modern IT environments.
Jim Frey covers networking as principal analyst at TechTarget's Enterprise Strategy Group.
Torsten Volk is principal analyst at TechTarget's Enterprise Strategy Group covering application modernization, cloud-native applications, DevOps, hybrid cloud and observability.
Enterprise Strategy Group is a division of TechTarget. Its analysts have business relationships with technology vendors.