Google Cloud Dataproc is the first major cloud provider to integrate Apache Spark with Kubernetes as a managed service, but work remains to better link the two projects upstream.
An early version of a Google Cloud service that runs Apache Spark on Kubernetes is now available, but more work will be required to flesh out the container orchestration platform's integrations with data analytics tools.
Kubernetes and containers haven't been renowned for their use in data-intensive, stateful applications, including data analytics. But there are benefits to using Kubernetes as a resource orchestration layer under applications such as Apache Spark rather than the Hadoop YARN resource manager and job scheduling tool with which it's typically associated. Developers and IT ops stand to gain advantages that containers bring to any application, such as portability across systems and consistency in configuration, along with automated provisioning and scaling for workloads that's handled in the Kubernetes layer or by Helm charts, as well as container resource efficiency compared with virtual or bare metal machines.
"Analytical workloads, in particular, benefit from the ability to add rapidly scalable cloud capacity for spiky peak workloads, whereas companies might want to run routine, predictable workloads in a virtual private cloud," said Doug Henschen, an analyst at Constellation Research in Cupertino, Calif.
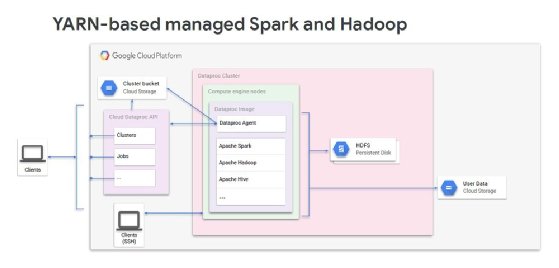
Google, which offers managed versions of Apache Spark and Apache Hadoop that run on YARN through its Cloud Dataproc service, would prefer to use its own Kubernetes platform to orchestrate resources -- and to that end, released an alpha preview integration for Spark on Kubernetes within Cloud Dataproc this week. Other companies, such as Databricks (run by the creators of Apache Spark) and D2iQ (formerly Mesosphere), support Spark on Kubernetes, but Google Cloud Dataproc stands to become the first of the major cloud providers to include it in a managed service.
Customers don't care about managing Hive or Pig, and want to use Kubernetes in hybrid clouds.
James MaloneProduct manager, Google Cloud Dataproc
Apache Spark has had a native Kubernetes scheduler since version 2.3, and Hadoop added native container support in Hadoop 3.0.3, both released in May 2018. However, Hadoop's container support is still tied to HDFS and is too complex, in Google's view.
"People have gotten Docker containers running on Hadoop clusters using YARN, but Hadoop 3's container support is probably about four years too late," said James Malone, product manager for Cloud Dataproc at Google. "It also doesn't really solve the problems customers are trying to solve, from our perspective -- customers don't care about managing [Apache data warehouse and analytics apps] Hive or Pig, and want to use Kubernetes in hybrid clouds."
Apache Spark on YARN, which Google seeks to simplify with Kubernetes in Cloud Dataproc.
Spark on Kubernetes only scratches the surface of big data integration
Cloud Dataproc's Spark on Kubernetes implementation remains in a very early stage, and will require updates upstream to Spark as well as Kubernetes before it's production-ready. Google also has its sights set on support for more Apache data analytics apps, including the Flink data stream processing framework, Druid low-latency data query system and Presto distributed SQL query engine.
"It's still in alpha, and that's by virtue of the fact that the work that we've done here has been split into multiple streams," Malone said. One of those workstreams is to update Cloud Dataproc to run Kubernetes clusters. Another is to contribute to the upstream Spark Kubernetes operator, which remains in the experimental stage within Spark Core. Finally, Cloud Dataproc must brush up performance enhancement add-ons such as external shuffle service support, which aids in the dynamic allocation of resources.
For now, IT pros who want to run Spark on Kubernetes must assemble their own integrations among the upstream Spark Kubernetes scheduler, supported Spark from Databricks, and Kubernetes cloud services. Customers that seek hybrid cloud portability for Spark workloads must also implement a distributed storage system from vendors such as Robin Systems or Portworx. All of it can work, but without many of the niceties about fully integrated cloud platform services that would make life easier.
For example, the Spark Kubernetes executor uses Python, rather than the Scala programming language, which is a bit trickier to use.
"The Python experience of Spark in Kubernetes has always lagged the Scala experience, mostly because deploying a compiled artifact in Scala is just easier logistically than pulling in dependencies for Python jobs," said Michael Bishop, co-founder and board member at Alpha Vertex, a New York-based fintech startup that uses machine learning deployed in a multi-cloud Kubernetes infrastructure to track market trends for financial services customers. "This is getting better and better, though."
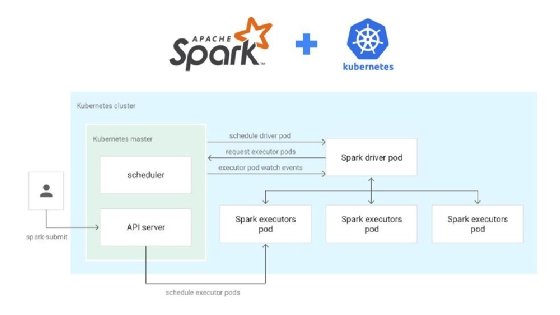
Apache Spark on Kubernetes, now in alpha preview in Cloud Dataproc.
There also remain fundamental differences between Spark's job scheduler and Kubernetes that must be smoothed out, Bishop said.
"There is definitely an impedance [between the two schedulers," he said. "Spark is intimately aware of 'where' is for [nodes], while Kubernetes doesn't really care beyond knowing a pod needs a particular volume mounted."
Google will work on sanding down these rough edges, Malone pledged.
"For example, we have an external shuffle service, and we're working hard to make it work with both YARN and Kubernetes Spark," he said.