IT ops pros predict routes to DevOps efficiency in 2018
Operations admins have a lot on their plates already, and they'll pile on more in 2018. These IT pros and analysts share what's coming and how to handle it.
IT operations is a fast-moving river of change. It might bend or fork as it travels, you might go over a Waterfall, but it never doubles back.
Expert IT professionals and analysts -- many of whom write tips on the tools and technologies you use every day -- lay out their predictions for where IT operations is heading in 2018. Everyone expects a heavier emphasis on DevOps efficiency through smarter adoption and evolved tools and practices. Another broad IT trend to plan for is increased reliance on the cloud for enterprise IT workloads. And IT pros should position themselves to meet the demand for knowledgeable coders.
DevOps: Full speed ahead
DevOps started as a way to organize team structure, with developers and operations admins assembled around the same table to create better applications on better infrastructure with better management processes.
More organizations have adopted DevOps, but often in a poorly implemented, piecemeal manner, said Clive Longbottom, analyst at Quocirca and a TechTarget contributor. Getting DevOps under control is an important step for 2018, but this can be a challenge when the goals constantly fluctuate.
DevOps has begun to shift to an intent-modeled approach, wherein IT operations describes goals rather than the steps to take to reach them, said Tom Nolle, president of CIMI Corporation and a TechTarget contributor. To maximize DevOps efficiency, IT teams should pair the intent-based model with an event handling process so users can make specific requests. This path will grow more important as work that builds business value piles up.
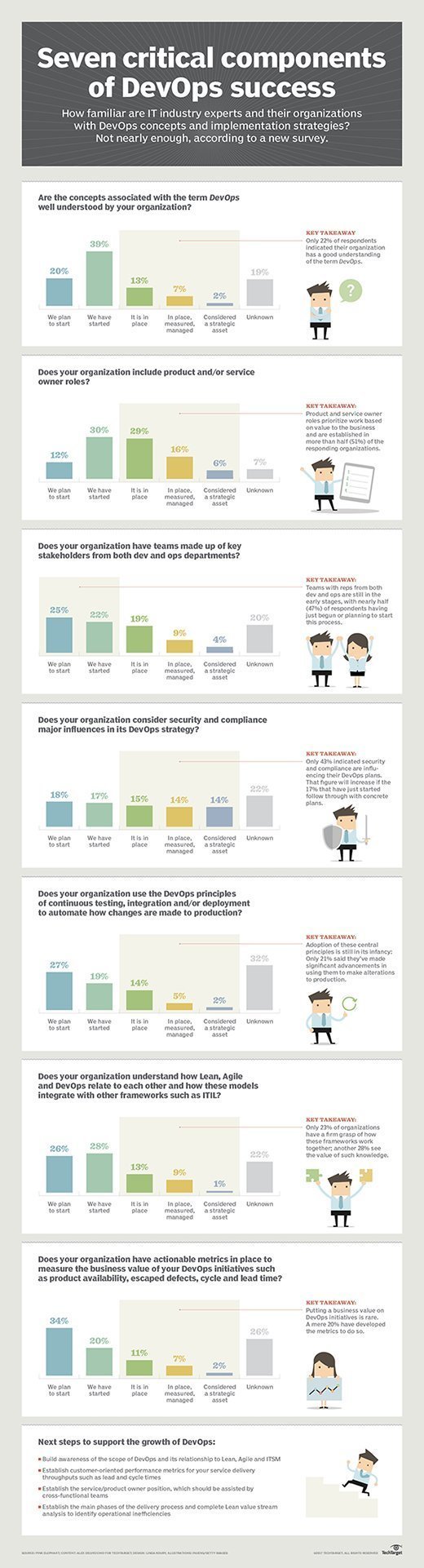
Organizations' responses to a 2017 DevOps survey indicate there's room to improve.
However, in 2018, DevOps efficiency and effectiveness in most organizations will fall short of this self-service goal. IT organizations should embrace a business-focused approach nonetheless. Most user bases aren't technology-focused and must prioritize work that creates income rather than learning skills and systems, said Adam Fowler, an IT operations manager and TechTarget contributor. That's especially true when those skills and systems grow outdated just as fast as they became necessary.
If user self-service is beyond the scope of possibility, start by breaking down the barriers between workgroups. Distributed applications, which are common in modern IT environments, increase dependencies across the IT estate. Organizations with multiple teams working independently on an array of projects need those teams to communicate. API deployments can affect work done outside a given team's project, and a lack of visibility across the department can break dependencies and potentially cause major outages, said Jason Hand, DevOps evangelist at VictorOps Inc., an IT incident management software maker in Boulder, Colo.
Tools should always align DevOps practices with business value, he added. The conversation about how IT contributes to business goals has been taking place for decades, but businesses increasingly rely on fast delivery times on digital products. "A release cycle of weeks or months is not acceptable anymore, and it's a bigger risk to sit on things and try to make them perfect than it is to get it out there," Hand said. Keeping a short feedback loop enables Hand's team to not only fix problems quickly, but make fast changes to items their users hate.
To feed that need for speed, organizations must abandon the mindset of long and repetitive planning cycles before finally working on a project, said Adam Bertram, IT automation consultant and a TechTarget contributor. To get products out to users, IT teams must be willing to go live without every single feature, with the hopes that users will accept this way of working. "Users will begin to appreciate that they can get access to services much faster," he said.
SREs please
By 2018, everything in IT must be about the application. DevOps manages the entire application lifecycle, from component deployments and redeployments to responses to internal or external failures, Nolle said. With focus shifted to the application, the infrastructure on which it lives matters less than user experience (UX). The infrastructure might be traditional, such as bare-metal servers in an in-house data center; a public cloud; a container setup; or some mix of all three. Ultimately, the application must run in a way that satisfies end users.
To support this flexibility, DevOps teams will work across multiple deployment models, possibly all at once, and they must grow accustomed to having less control in some platforms than others.
The widening variety of infrastructure setups and environments calls for site reliability engineers (SREs), who can merge those infrastructure and application management tasks and increase automation to improve DevOps efficiency.
"The SRE role, in general, is far better attuned to handle the myriad types of infrastructure as code [IAC] we now see businesses putting into production," said Chris Gardner, Rob Stroud, Eveline Oehrlich and Charles Betz, analysts at Forrester.
Whether they bear the title of SRE or not, operations personnel can and should begin to leverage code more, Bertram said. Code, in this context, is written for infrastructure, not so much for applications.
Wonky cloud platforms
AI and machine learning are invaluable but won't cover the full breadth of things we need to be aware of; it's not going to be the one thing that's going to save us.
Adam FowlerIT operations manager
As the cloud becomes mainstream for enterprises, the question is which cloud services to use and how best to integrate them with other existing infrastructure setups, said Kurt Marko, IT consultant at MarkoInsights and a TechTarget contributor. In 2018, IT ops pros should focus on how to evaluate and select services for specific applications and workloads, how to control cost and how many providers are necessary for appropriate redundancy.
"[I expect] a lot more companies to become a lot more cloud mobile," said Stuart Burns, a virtualization and Linux expert at a Fortune 500 company and a TechTarget contributor. Avoid vendor lock-in as much as possible, because organizations must maintain cloud agility to play to the strengths and weaknesses associated with specific cloud vendors, Marko explained.
Speaking of cloud agility, hybrid cloud infrastructures will be common in organizations in 2018, especially for applications with components that must stay on premises for security or legacy reasons. Root cause analysis is vital for these setups so that organizations can pinpoint the exact location of any problem. IT's responsibility for application performance doesn't stop at the cloud provider's doorstep, Longbottom warned.
Automated IT monitoring
Hosting applications on multiple infrastructure designs compounds complexity, and ops admins should automate everything they can in 2018, Marko said. IAC systems will become important for these ops teams. IAC necessitates a high-level understanding of at least one scripting language or format, such as YAML, Python or PowerShell.
For many organizations, root cause analysis and asset usage tracking simply aren't enough anymore, suggested Dan Ravenstone, an enterprise monitoring specialist at XE.com, an international currency authority in Newmarket, Ont. Monitoring and incident response practices are instead shifting to resiliency and performance tests. UX is more important than individual component reliability, at least in microservices-based applications. Individual component failures likely will have little to no effect on overall application performance for these applications.
AI and everything after
AI and machine learning will continue to grab the spotlight in 2018. Organizations' ability to use AI to create business intelligence applications will continue to mature and lead to a push for front-end UX automation, as well as for feedback routes and efficient DevOps management, Fowler said. Even so, he's skeptical: "I'm less convinced [AI will] be successful in anywhere but the biggest of companies who can still invest proper resources onto such projects."
At AI's current development stage, it cannot account for unanticipated issues, Ravenstone pointed out. What it can do -- and does well -- is monitor end-to-end software development lifecycles and quickly locate errors and inefficiencies. "AI and machine learning are invaluable but won't cover the full breadth of things we need to be aware of. It's not going to be the one thing that's going to save us," Fowler said.