5 leading data virtualization tools offer integration strategy
Learn which features and capabilities your organization should consider in order to select the data virtualization platform that will best fits its needs.
With the volume of enterprise data increasing significantly each day, data virtualization gives organizations the ability to quickly collect and integrate multiple sources and formats of data from different locations into a single source of data. Data virtualization also reduces the need for multiple physical copies of data, thereby lowering storage costs. But how can organizations take advantage of data virtualization technology?
Data virtualization tools can simplify the management of an organization's data, while also reducing costs. In an enterprise, there are numerous data silos. These silos often exist in the form of applications tied to large data repositories that are often isolated from other applications that might benefit from being able to access the data. Data virtualization tools commonly enable these data siloes to be virtually consolidated so that all of an organization's data appears to exist in a single location.
Data virtualization also attempts to limit the use of physical data copies. Each physical copy of a database consumes storage space and other hardware resources, thereby increasing costs. Data virtualization enables organizations to create virtual data copies from a centralized data repository. All these virtual copies exist as links to the one physical copy of the data. Virtualizing the data in this way not only reduces storage costs, but also promotes data consistency throughout the organization.
Key features of data virtualization tools
Each data virtualization vendor has its own way of doing things, so features and capabilities inevitably differ from one platform to the next. When shopping for data virtualization tools, there are several features to consider:
Data virtualization tools can simplify the management of an organization's data, while also reducing costs.
Data silo consolidation. Some data virtualization software products can link to multiple, siloed data sources and make it look like all the data resides within a single source.
Data transformation. At its core, vendors design the data virtualization architecture so organizations can create virtual copies of the data as needed. Some products include features to transform data so that it can be more easily modeled.
GUI data modeling. Data transformation can be a complex process and, in many cases, it requires scripting. Some data virtualization tools feature graphical, or codeless, data modeling and design tools that eliminate the need for custom coding.
Advanced transformation of nonrelational data. While many databases are relational, nonrelational databases such as NoSQL are common in the enterprise. Ideally, a data virtualization product should support the transformation of both structured and unstructured data.
Advanced query engine. A data virtualization product should provide users with the means to generate complex queries against data copies.
Secure access control. Data is almost always an organization's most sensitive asset, so it's important for a data virtualization product to include a data firewall and features designed to ensure secure access control.
Before buying a data virtualization tool, examine which features these five vendors offer.
The data virtualization market
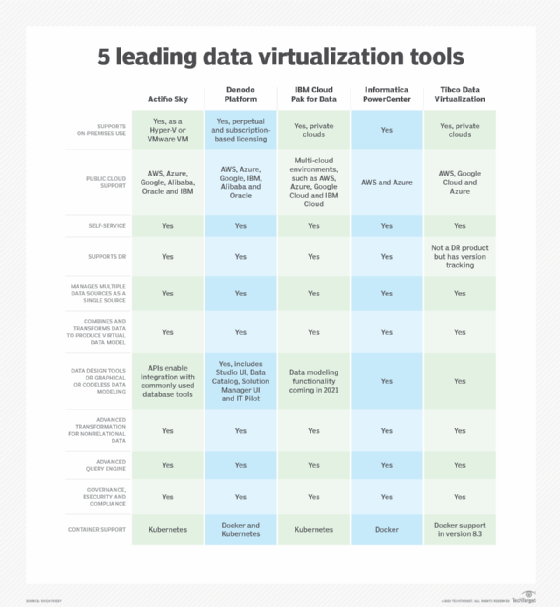
Once organizations consider how these features meet their needs, the next step is to examine these five prominent data virtualization tools -- Actifio Sky, Denodo Platform, IBM Cloud Pak for Data, Informatica PowerCenter and Tibco Data Virtualization. Note that all AWS pricing estimates are based on the eastern U.S.
Actifio Sky
Actifio Sky is a software-based data virtualization tool that organizations can deploy as a VMware or Hyper-V VM. It also supports AWS, Azure, Google, Alibaba, Oracle and IBM clouds.
The tool enables authorized users to self-service provision data copies. A security and compliance ecosystem that's only accessible to those with the proper access to the data helps ensure data is kept safe.
While many data virtualization tools support data models, Actifio's product enables data copies to be rapidly spun up and quickly torn down, thereby making it easy for data scientists and analysts to create and destroy data copies.
One of Actifio Sky's most compelling features is its use as a disaster recovery tool. Actifio Sky can perform point-in-time data recovery as needed because it stores data in immutable storage. The product can perform large-scale recovery operations with recovery time objectives measured in minutes.
Pricing for Actifio Sky depends on how it's deployed, whether it's licensed on an hourly or annual basis, and the cost of the underlying infrastructure when used in the cloud. Amazon estimates the cost as $13.55 per hour when run on an m4.xlarge instance.
Denodo Platform
Denodo Platform helps meet the needs of business and IT stakeholders. It can run on premises or in the Microsoft or Amazon clouds to provide rapid access to data. In-memory parallel processing helps the software run at optimal speeds, while the dynamic query optimizer helps structure data queries for fast execution.
The data virtualization platform features an interface that's designed to give users access to the data they need, while also enabling centralized control and administration.
Denodo Platform supports common industry standards, including OAuth 2.0 Security Assertion Markup Language, OpenAPI and Open Data Protocol, or OData 4. Organizations can also use the software in a Docker container environment.
Denodo's pricing depends on where it's run, how it's licensed and on the underlying infrastructure. Amazon estimates the cost at $22.60 per hour when run on an m4.2xlarge VM instance.
IBM Cloud Pak for Data
IBM Cloud Pak for Data brings together data management, data governance and data analysis into a single platform. This tool works with AWS, Azure, Google Cloud and IBM Cloud, but it also supports private cloud environments and works with Kubernetes.
The IBM data virtualization platform can help simplify the data modeling process. It enables organizations to create machine learning models in both production and development environments, with full support for collaboration.
Cloud Pak for data is fully extensible through various APIs and through an ecosystem of hardware and software products. The most notable of these, IBM Streams, enables real-time application streaming and rapid data analytics when combined with IBM Cloud Pak for Data.
IBM recently released Knowledge Accelerators, which provide comprehensive industry glossaries to IBM Watson Knowledge Catalog on Cloud Pak for Data.
IBM doesn't publicly disclose pricing for Cloud Pak for Data.
Informatica PowerCenter
Informatica PowerCenter focuses on organizations that require advanced data transformation capabilities. The software enables universal connectivity to any type of data and comes preloaded with numerous prebuilt transformations. The platform is also designed to be fully collaborative.
Informatica also enables automated data validation testing. Users can audit and test transformed data without having to write code.
Informatica also supports several add-on packages, including the Data Integration Hub, B2B Data Exchange, PowerExchange for Cloud Applications, Advanced Data Transformation and the PowerCenter Productivity Add-On Package.
Pricing for PowerCenter depends on how it's licensed and the underlying infrastructure costs. As an example, PowerCenter is available within the AWS Marketplace at a starting price of $3.50 per hour. Amazon estimates the hourly cost to be about $7.35 per hour when running on a c5.xlarge instance.
Tibco Data Virtualization
Tibco Data Virtualization supports a variety of data types, including nontraditional sources such as file data. The software, which runs on AWS, Google or Azure clouds, features a studio design tool that can help simplify tasks such as designing data services, modeling data, building transformations or optimizing queries.
The product's most unique feature is probably its business directory, which enables users to search and categorize curated data. This directory makes it easy for users to share and reuse business data. Tibco Data Virtualization's suite of security and governance tools protect all the data.
Pricing for Tibco Data Virtualization depends on where the product is run and how it's licensed. Amazon estimates the cost to be $8.58 per hour when running on an m4.large instance.
How does data virtualization differ from ETL and EAI?
At a fundamental level, data virtualization tools function differently from other data transformation technologies such as extract, transform and load (ETL) or enterprise application integration (EAI). However, many of the higher-end data virtualization products incorporate ETL and EAI capabilities.
ETL systems copy data from one or more sources and then restructure the data prior to placing it on the destination system. This restructuring, or transformation, puts the data into a specific format so it can be more easily used or analyzed. In addition to restructuring the data, modern ETL products also take steps to verify the data's quality and consistency as a part of the transformation process.
EAI technology enables business applications to share data. For example, an organization's CRM application and its supply chain management application typically store data in different formats. EAI software acts as middleware that enables one application to use the data that's associated with another application. When one application needs to access data associated with a different application, the EAI software queries the secondary application on the primary application's behalf. It then restructures the requested data into a format the primary application can use.
Data virtualization tools work differently from ETL and EAI software. The software enables the creation of logical copies of the organization's data on demand, but in a nondisruptive manner that doesn't require the creation of a physical data copy. For example, a developer who needed a copy of a production database to build a new version of the database application could use a data virtualization tool to provide a virtual copy of the data. The virtual copy actually uses production data but redirects write operations associated with the virtual copy so they don't interfere with the production environment. The end result is that the developer is able to work from an exact copy of the production data but without the security risks or storage infrastructure requirements of a physical copy.