3 virtualization infrastructure design rules to shape your deployment
Admins can improve virtual infrastructure design by focusing their deployments on transparency and flexibility and critically evaluating emerging technologies.
Administrators prepared with best practices that emphasize planning, transparency and flexibility can navigate the immense complexity of virtualization infrastructure design with ease.
Admins don't always get the chance to design virtualization infrastructure from the ground up. Rather than maintain good enough policies, admins should take a step back and return to virtualization infrastructure design principles that can frame design decisions big and small.
An IT infrastructure plan should form the basis of all management and maintenance decisions. Admins should regularly review and renew this plan to evaluate the practicality of integrating new technologies. Products and paradigms that initially lacked support, integrations or cost-effective price points might be more practical now.
No plan can completely account for failure, but virtualization infrastructure design is incomplete without policies and practices for recovery. Admins often design their infrastructures for the highest amount of availability, but failure eventually happens to everyone. Admins must integrate failure preparation and disaster recovery as core virtualization infrastructure design principles.
Even if admins create the ideal virtualization infrastructure for their present deployments, it will eventually prove lacking if they don't embed flexibility into its design. The cloud is a moving target, and many IT deployments are already hybrid to some degree. That proportion will continue to shift, so IT must build and maintain infrastructures that can keep up.
Build virtualization infrastructure design principles into a plan
Virtualization infrastructure design principles require a foundational IT infrastructure plan, and admins should approach this with a fresh perspective. If admins inherit an infrastructure, it's especially easy to extend bad strategies under the assumption that what worked before will continue to work.
Traditionally, organizations assemble a virtual infrastructure with separate compute, networking and storage silos; but with a fresh perspective, admins might find that a converged or hyper-converged infrastructure (HCI) product fits their current and future needs better.
The primary advantage of HCI is that it offers these separate functions in a streamlined package. However, the resulting density imposes significant power demands, so data centers with older server racks might struggle. Even if a full HCI redesign isn't doable, admins can incorporate products that enable shared storage pools across numerous virtualization hosts, such as VMware vSAN.
Figure A. Examine the IT infrastructure stack to evaluate where new technologies can offer consolidation and improvement.
By embracing virtualization infrastructure design rather than preservation, admins can better evaluate and integrate emerging technologies. Even if HCI isn't practical yet, admins can take steps toward practicality with a distributed approach. Any reduction in large infrastructure costs is beneficial.
Beyond larger infrastructure overhauls, admins should also regularly evaluate cost-cutting measures that can lower IT infrastructure costs. For instance, admins should consider replacing older servers with modernized ones that can support higher levels of workload consolidation, renegotiating telecom carrier contracts to get better terms and implementing self-service resources to replace routine tasks normally performed by the IT staff.
Failure is inevitable and transparency is necessary
Careful virtualization infrastructure design must account for the inevitability of failure.
Admins often design their infrastructures for availability and rely on a variety of products to prevent outages. The power of virtualization and migration technologies, such as vMotion, fault tolerance and high availability, can make it easy to ignore the possibility of hardware failure.
Rather than attempting to prevent the inevitable, admins should incorporate failure preparation as a virtualization infrastructure design principle. If admins design for the likelihood of failure, they can enable swift recovery by preparing extra hardware, isolating essentials in a dedicated management cluster and using documentation to track changes.
Simple mistakes can have large consequences, but simple tactics can facilitate recovery.
Human error is as likely a cause of failure as technology is, and it's often less predictable. For example, if a rushed or inexperienced admin disables the distributed resource scheduler instead of putting it in maintenance mode before an update, that action could accidentally remove affinity rules and resource pools. Simple mistakes can have large consequences, but simple tactics can facilitate recovery. In this example, and many similar ones, thorough documentation enables admins to recover lost information.
Documentation is useful for transparency among IT staff and between IT and management. Even in the worst circumstances, such as a host crash, admins should use a shared IT outage communication plan to keep all the stakeholders up to date on the recovery process.
Design for flexibility
Virtualization infrastructure design principles must account for the present, as well as the future, so admins must build cloud and hybrid possibilities into their deployments.
Many organizations currently have a chaotic cloud presence due to a lack of planning, and they rely on a variety of services that different stakeholders have requisitioned but that no one has coordinated. IT admins often find themselves pulled in different directions by operations staff seeking stability in the hybrid cloud and developers seeking agility in the public cloud.
To accomplish hybrid IT design, admins must face political and technological challenges. Hybrid infrastructures often falter because business and IT needs aren't in alignment. Common issues include a failure to properly measure the costs, benefits and timelines of new investments.
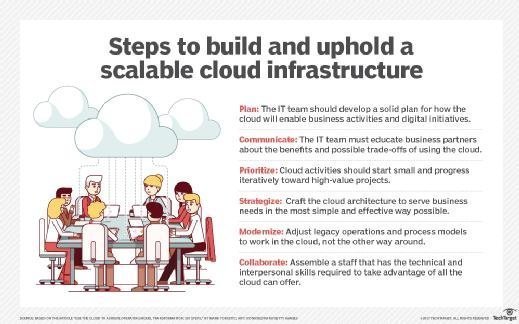
Figure B. Establish a flexible cloud infrastructure that can scale.
Effective virtualization infrastructure design includes being ready for hybrid models that include cloud to various degrees, whether it's hybrid cloud, private cloud or cloud extensions for disaster recovery, such as VMware Cloud on AWS.
A cloud-ready infrastructure should be able to scale up and down as necessary, reduce administrative costs, and eliminate vendor lock-in. As more companies release cloud versions of line-of-business applications, admins will have more opportunities to reduce infrastructure costs. A flexible infrastructure should also minimize downtime and enable rapid, efficient changes as vendors add features and updates.