What is distributed computing?
Distributed computing is a model in which components of a software system are shared among multiple computers or nodes. Even though the software components are spread out across multiple computers in multiple locations, they're run as one system to improve efficiency and performance. The systems on different networked computers communicate and coordinate by sending messages back and forth to achieve a defined task.
Due to its ability to provide parallel processing between multiple systems, distributed computing can increase performance, resilience and scalability, making it a common computing model in database systems and application design.
Distributed computing is sometimes also known as distributed systems, distributed programming or distributed algorithms.
How distributed computing works
Distributed computing networks can be connected as local networks or through a wide area network if the machines are in different geographic locations. Processors in distributed computing systems typically run in parallel.
Common functions involved in distributed computing include the following:
- Task distribution. A central algorithm distributes a large task into smaller subtasks. These sub-tasks are then assigned to different nodes within the system to distribute the workload.
- Parallel execution. Once the nodes are assigned, they independently execute their assigned subtask concurrently with other nodes. This parallel processing enables faster computation of complex tasks compared to sequential processing.
- Communication. Nodes in a distributed system communicate with one another to share resources, coordinate tasks and maintain synchronization. This communication can take place through a variety of network protocols.
- Aggregation of results. After completing their respective sub-tasks, nodes often send their results back to a central node or aggregator. The aggregator combines these results to produce the final output or result of the overall computation.
- Fault tolerance. Distributed systems are designed to handle failures gracefully. They often incorporate redundancy, replication of data and mechanisms for detecting and recovering from failures of individual nodes or communication channels.
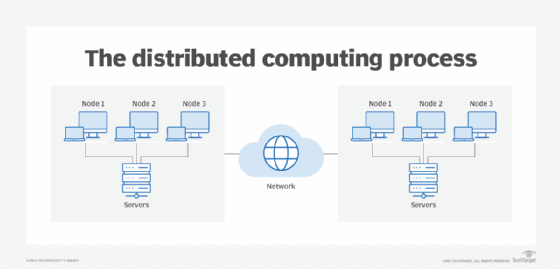
Types of distributed computing architecture
In enterprise settings, distributed computing generally puts various steps in business processes at the most efficient places in a computer network. For example, a typical distribution has a three-tier model that organizes applications into the presentation tier -- or user interface -- the application tier and the data tier. These tiers function as follows:
- User interface processing occurs on the PC at the user's location.
- Application processing takes place on a remote computer.
- Database access and algorithm processing occur on another computer that provides centralized access for many business processes.
In addition to the three-tier model, other types of distributed computing architectures include the following:
- Client-server architectures. The client-server architectures use smart clients that contact a server for data, then format and display that data to the user.
- N-tier system architectures. Typically used in application servers, these architectures use web applications to forward requests to other enterprise services.
- Peer-to-peer architectures. These divide all responsibilities among all peer computers, which can serve as clients or servers. This model is popular in several use cases, including blockchain networks, content exchange and media streaming.
- Scale-out architectures. The scale-out architecture is typically used by distributed computing clusters, making it easier to add new hardware as the load on the network increases.
- Distributed shared memory architecture. This type of memory architecture is applied to loosely coupled distributed memory systems. It enables end-user processes to access shared data without the need for inter-process communication.
Advantages of distributed computing
Distributed computing offers the following benefits:
- Enhanced performance. Distributed computing can help improve performance by having each computer in a cluster handle different parts of a task simultaneously.
- Scalability. Distributed computing clusters are scalable by adding new hardware when needed. Additionally, they can keep running even if one or more of the systems malfunctions, thus offering scalability and fault tolerance.
- Resilience and redundancy. Multiple computers can provide the same services. This way, if one machine isn't available, others can fill in for the service. Likewise, if two machines that perform the same service are in different data centers and one data center goes down, an organization can still operate.
- Cost-effectiveness. Distributed computing can use low-cost, off-the-shelf hardware. These systems aim to achieve high performance by reducing latency, improving response time and maximizing throughput to meet shared objectives.
- Efficiency. Complex requests can be broken down into smaller pieces and distributed among different systems. This way, the request is simplified and worked on as a form of parallel computing, reducing the time needed to compute requests.
- Flexibility. Unlike traditional applications that run on a single system, distributed applications run on multiple systems simultaneously.
- Transparency. Distributed systems can present resources such as files, databases and services as if they exist at a single computer or location, even though they could be spread across multiple nodes. This transparency enables users or applications to access resources without needing to know where they're physically located.
Disadvantages of distributed computing
Along with its various advantages, distributed computing also presents certain limitations, including the following:
- Configuration issues. For a distributed system to work properly, all nodes in the network should have the same configuration and be able to interact with one another. This can bring challenges for organizations that have complicated IT infrastructure or have IT staff that lacks the necessary skills.
- Communication overhead. Coordinating and communicating between multiple nodes in a distributed system can create additional communication overhead, potentially reducing overall system performance.
- Security management. Managing security in distributed systems can be complex, as users should control replicated data across various locations and ensure network security. Additionally, ensuring consistent performance and uptime across distributed resources can be challenging.
- Cost. While distributed systems can be cost-effective in the long run, they often incur high deployment costs initially. This can be an issue for some organizations, especially when compared to the relatively lower upfront costs of centralized systems.
- Complexity. Distributed systems can be more complex to design, execute and maintain compared to centralized systems. This can lead to challenges in debugging, monitoring and ensuring the overall system's reliability.
Use cases for distributed computing
Distributed computing has use cases and applications across several industries, including the following:
- Healthcare and life sciences. Distributed computing is used to model and simulate complex life science data. This enables the efficient processing, storage and analysis of large volumes of medical data along with the exchange of electronic health records and other information among healthcare providers, hospitals, clinics and laboratories.
- Telecommunication networks. Telephone and cellular networks are examples of distributed networks. Telephone networks were initially operated as early peer-to-peer networks. Cellular networks, on the other hand, consist of distributed base stations across designated cells. As telephone networks transitioned to voice over Internet Protocol, they've evolved into more complex distributed networks.
- Aerospace and aviation. The aerospace industry uses distributed computing, including the distributed diagnostic system for airplane engines. DAME handles extensive in-flight data from operating aircraft using grid computing. This enables the development of decision support systems for aircraft diagnosis and maintenance.
- Manufacturing and logistics. Distributed computing is used in industries such as manufacturing and logistics to provide real-time tracking, automation control and dispatching systems. These industries typically use apps that monitor and check equipment, as well as provide real-time tracking of logistics and e-commerce activities.
- Cloud computing and IT services. The IT industry takes advantage of distributed computing to ensure fault tolerance, facilitate resource management and accessibility and maximize performance. It's also integral to cloud computing platforms, as it offers dynamic, flexible infrastructures and quality of service guarantees.
- Financial services. Financial services organizations use distributed systems for various use cases, such as rapid economic simulations, portfolio risk assessment, market prediction and financial decision-making. They also deploy web applications powered by distributed systems to offer personalized premiums, handle large-scale financial transactions securely via distributed databases and bolster user authentication to prevent fraud.
- Entertainment and gaming. Distributed computing is essential in the online gaming and entertainment sectors because it provides the necessary resources for efficient operation, supporting multiplayer online games, high-quality video animation and various entertainment applications.
- Distributed artificial intelligence. Distributed AI uses complex algorithms and large-scale systems for learning and decision-making, relying on computational data points distributed across multiple locations.
Grid computing, distributed computing and cloud computing
Grid computing and cloud computing are variants of distributed computing. The following are key characteristics, differences and applications of the grid, distributed and cloud computing models:
Grid computing
Grid computing involves a distributed architecture of multiple computers connected to solve a complex problem. Servers or PCs run independent tasks and are linked loosely by the internet or low-speed networks. In the grid computing model, individual participants can enable some of their computer's processing time to solve complex problems.
SETI@home is one example of a grid computing project. Although the project's first phase wrapped up in March 2020, for more than 20 years, individual computer owners volunteered some of their multitasking processing cycles -- while concurrently still using their computers -- to the Search for Extraterrestrial Intelligence (SETI) project. This computer-intensive problem used thousands of PCs to download and search radio telescope data.
Distributed computing
Grid computing and distributed computing are similar concepts that can be hard to tell apart. Generally, distributed computing has a broader definition than grid computing. Grid computing is typically a large group of dispersed computers working together to accomplish a defined task.
Conversely, distributed computing can work on numerous tasks simultaneously. Grid computing can also be defined as just one type of distributed computing. In addition, while grid computing typically has well-defined architectural components, distributed computing can have various architectures, such as grid, cluster and cloud computing.
Cloud computing
Cloud computing is also similar in concept to distributed computing. Cloud computing is a general term for anything that involves delivering hosted services and computing power over the internet. These services, however, are divided into three main types: infrastructure as a service, platform as a service and software as a service. Cloud computing is also divided into private and public clouds. A public cloud sells services to another party, while a private cloud is a proprietary network that supplies a hosted service to a limited number of people, with specific access and permissions settings. Cloud computing aims to provide easy, scalable access to computing resources and IT services.
Cloud and distributed computing both focus on spreading a service or services to several different machines; however, cloud computing typically offers a service such as specific software or storage for organizations to use on their own tasks. Distributed computing involves distributing services to different computers to aid in or around the same task.
Using distributed file systems, users can access file data stored across multiple servers seamlessly. Learn the key features of a distributed file system.