
Blue Planet Studio - stock.adobe
How to run LLMs locally: Hardware, tools and best practices
Local deployments of large language models offer advantages, including privacy, speed and customization -- but organizations need the right tools and infrastructure to succeed.

While many organizations rely on public cloud services for large language models, there are compelling reasons to run these models in-house, within an organization's own data center.
Organizations must consider a number of factors when deciding to run LLMs locally. For one, they must evaluate infrastructure requirements, such as the amount of GPUs needed to meet the demands of the intended use case. Additionally, there is a growing ecosystem of tools and models to support self-hosting of LLMs, from enabling users to run models on private devices without using GPUs to assisting with large-scale, multiuser applications.
Benefits to running LLMs locally
There are several reasons why an organization might choose to run an LLM on private infrastructure, rather than using a public cloud -- in particular, security and performance concerns.
Publicly hosted LLMs can expose sensitive data to a heightened risk of security vulnerabilities, including breaches of private information. Cloud-hosted LLMs also require constant internet connectivity, which can result in latency and performance issues. Running an LLM locally gives users greater control, strengthens privacy and can optimize model performance.
Certain sectors -- such as healthcare, military and other highly regulated environments -- might especially benefit from locally hosted LLMs. For example, imagine a healthcare facility running custom-trained LLMs locally to assist with patient diagnoses or handle patient interactions while protecting the privacy of sensitive medical information.
Edge deployments are also good candidates for locally hosted LLMs. In remote or isolated locations, such as oil rigs, manufacturing plants or autonomous vehicles, locally hosted LLMs can offer real-time decision-making support without relying on constant internet connectivity or cloud services.
Infrastructure requirements
When hosting an LLM locally, one of the first requirements to consider is GPU capacity. LLMs are computationally intensive, demanding significant GPU memory to store model parameters and intermediate data for inference.
GPUs are optimized for high performance, and they provide the speed and bandwidth necessary to run LLMs effectively. This hardware can handle the complex computations of LLMs without being hindered by bottlenecks in memory-to-processor data transfers.
A general rule for sizing an LLM deployment is to multiply model size -- in billions of parameters -- by 2, then add 20% as overhead. This calculation provides the amount of GPU memory needed to fully load the model into memory.
As an example, Meta's Llama-3.2-11B, with 11 billion parameters, requires at least 26.4 GB of GPU memory -- 11 x 2 + 20% overhead. Therefore, a GPU card like the Nvidia A100, which has 40 GB of GPU memory, is recommended to ensure sufficient resources for both model storage and inference processing.
For deployments with a large number of users, GPU requirements are even higher. Unfortunately, there isn't an exact formula to calculate GPU requirements for a production workload, as it largely depends on the specific usage patterns of the service. A practical approach is to start with small-scale testing, measure average GPU memory usage, and use that data to project the capacity needed for a full deployment.
In addition, there are other scenarios to consider when defining infrastructure requirements -- for instance, if you plan to train the model using fine-tuning. Fine-tuning requires even more GPU memory and ideally should be done on dedicated hardware so that it does not affect the LLM service for regular users.
Running language models locally on user devices
Organizations can also deploy language models directly on end-user devices using specialized tools and services that support local LLM use. These tools not only let individual users run models, but also provide a set of standardized APIs, which developers can use to build software such as retrieval-augmented generation applications.
Some popular tools for local deployment include the following:
- Ollama.
- GPT4All.
- LM Studio.
For instance, Ollama -- available on macOS, Linux and Windows -- provides a simple command-line interface for downloading and running optimized models from Ollama's repository. With the commands ollama pull llama3.2 and ollama run llama3.2, users can download Meta's Llama 3.2 model, create an API endpoint and initiate an interactive session with the model.

In addition, Ollama's API integrates with other tools, such as AnythingLLM and Continue, a Visual Studio Code extension that can serve as an alternative to GitHub Copilot.
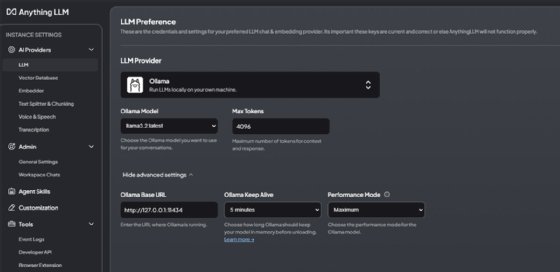
AnythingLLM provides content embedding. This lets users add their own data -- such as PDFs, Microsoft Word files or images -- and then engage in interactive chats with their data on their device.
Tools for multiuser local LLMs
Tools like Ollama work well for single-user sessions, but a different approach is needed to address the scale of centralized models serving multiple users. There are many tools available to handle multiuser LLM deployments, including vLLM and Nvidia Triton Inference Server.
VLLM can run on a single server with or without a GPU. It can also scale up to multinode, multi-GPU configurations using tensor parallelism, a technique that splits a large model across multiple GPUs. For example, a model as large as Llama-3.2-90B would require at least 216 GB of GPU memory -- 90 x 2 + 20% overhead.
Even Nvidia's most powerful GPU card -- the 141 GB H200 -- would not have adequate memory to contain that model, requiring any deployment to use multiple cards and tensor parallelism. Configuring larger deployments across multiple physical nodes also requires a high-speed connectivity back end, preferably InfiniBand.
An expanding GPU marketplace
While this article primarily focuses on Nvidia GPUs, support is growing for other GPU vendors, such as AMD and Intel. As deployment costs can vary by hardware provider, organizations should ensure compatibility with their preferred GPU vendor when choosing a tool to avoid unwanted expenses.
VLLM can also run on top of Kubernetes, enabling users to implement a production-ready inference-serving model that can take advantage of Kubernetes' benefits like scalability and higher availability. Ray, a unified framework for scaling AI and Python applications, can be used to facilitate distributed computation when using vLLM with multinode inferencing.
When hosting vLLM in a Kubernetes environment, API load balancing is critical, as each instance of vLLM runs with its own endpoint. Teams can use Kubernetes' built-in HTTP load-balancing capabilities or an external proxy service, such as LiteLLM. Because vLLM on Kubernetes requires direct access to any GPUs that it does not see natively, Nvidia device plugins must be installed to make the GPUs accessible to containerized vLLM instances.
With vLLM in place, teams can build custom applications and services using integration frameworks like LangChain. The same configuration can also support training tasks such as fine-tuning, as shown below.
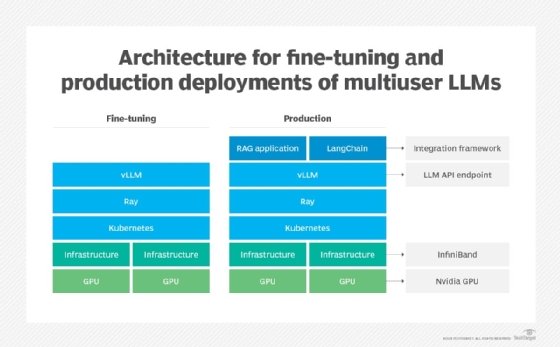
Another option for multiuser LLMs is Nvidia AI Enterprise, which provides a stack similar to vLLM's, including Ray. However, this commercial service comes with a higher price tag.
Marius Sandbu is a cloud evangelist for Sopra Steria in Norway who mainly focuses on end-user computing and cloud-native technology.
Dig Deeper on AI infrastructure
-
![]()
AMD pushes for open ecosystem to challenge Cuda dominance
By: Aaron Tan
-
![]()
CNCF Kubernetes AI program faces scrutiny from IT analysts
By: Beth Pariseau
-
![]()
OpenAI now offers open AI models, but CIOs need to assess the risk
By: Cliff Saran
-
![]()
Storage innovation surges to keep pace with AI shift to inference
By: Simon Robinson



