How to ensure interpretability in machine learning models
When building ML models, developers can use several techniques to make models easier for humans to interpret, leading to improved transparency, troubleshooting and user acceptance.

Creating machine learning models that generate accurate results is one thing. But ensuring model interpretability -- meaning the ability to understand why the model generates certain results -- is quite another. Without interpretability, models are unsuitable for use cases where understanding and explaining model behavior is important.
Interpretability in machine learning sheds light on why ML models make certain decisions, leading to more understandable results and increased transparency. To enhance interpretability in both new and existing models, model developers can use several techniques, including linear regression, generalized linear modeling, decision trees and local interpretable model-agnostic explanations (LIME).
What is interpretability in machine learning?
In ML, interpretability is the ability to understand why a model makes a given decision. For example, consider a simple model that sorts images of cats from images of dogs. If the model is highly interpretable, users can understand the categorization process that takes place within the model when it assesses each image.
In other words, users can discern which parameters the model considers and how it processes them to arrive at a conclusion. Does it emphasize overall colors within each image, for example? Or does it look for certain concentrations of color, like black dots that could indicate the presence of a dog's snout? With interpretability, users can answer questions like these -- to an extent.
Importantly, interpretability exists on a spectrum; some models are more interpretable than others. Even with highly interpretable models, it's often impossible to know with total certainty why a model makes each decision it does, but it is possible to gain a fairly thorough understanding.
Why does interpretability matter?
Model interpretability is important for several reasons, including compliance and transparency, customizing model behavior, and model troubleshooting.
Compliance and transparency
Some compliance regulations require that businesses explain to users why an automated service makes certain decisions about them. For instance, the EU's GDPR mandates transparency in algorithmic decision-making.
More generally, users might demand transparency, even if no compliance rule explicitly requires it. For example, a consumer whose loan application is denied by an AI service might want to understand the reasons behind the decision so that they can rectify the issue and reapply.
In cases like these, model interpretability is critical. Without it, models remain black boxes whose decisions are opaque even to the companies that deploy them. Moreover, ML bias -- where models make decisions based on learned biases and stereotypes -- has a higher chance of going undetected and harming users when a model lacks interpretability.
Customizing model behavior
The more interpretable a model is, the easier it is for developers to customize how it behaves. If users have more information about the parameters a model evaluates and how it assesses them, they are better positioned to modify those parameters, thereby influencing model operations.
Model troubleshooting
In a similar vein, interpretability can help when troubleshooting model problems such as inaccurate predictions. For instance, if a model designed to distinguish between cats and dogs misidentifies certain cats as dogs, knowing which parameters the model focuses on could help developers identify the problem.
Developers might discover that the model heavily emphasizes colors, causing it to mislabel cats with yellow coats as dogs because their fur color resembles that of golden retrievers. With this information, developers could adjust the model to improve its behavior. Or, if changes to the model are not feasible, users would at least be able to anticipate inaccurate decisions and avoid inputs that could lead to misidentifications.
Interpretability vs. explainability
While ML interpretability and explainability are related, it's important not to conflate the two concepts.
Explainability refers to the ability to predict which types of decisions a model will make based on specific types of input. For instance, if users know that a model mislabels yellow-coated cats as dogs -- even if they don't know why it mislabels them -- the model is explainable because users can anticipate that certain inputs will yield certain outputs.
Unlike interpretability, explainability doesn't require insight into a model's internal workings. It merely involves predicting how a model is likely to respond to given types of input based on observed patterns. Users can establish explainability by looking at examples of past predictions and comparing input to output.
Explainability is useful for anticipating problematic model behavior and can help users control model output by tweaking the input data. However, it does not aid in customizing or troubleshooting the model itself, as it provides no insight into a model's inner workings.
Strategies for ensuring interpretability in ML models
Best practices for creating interpretable models vary depending on whether the model is new or already in place.
Interpretability for new models
When designing a new model from scratch, the easiest way to ensure interpretability is to use an algorithm that operates in straightforward, predictable ways.
Common examples of such algorithms include the following:
- Linear regression, a type of algorithm that makes decisions by comparing unknown data to known data.
- Generalized linear modeling, a method that focuses on probability distributions across non-normal distributions of data.
- Decision trees, which work through a series of questions to arrive at a conclusion.
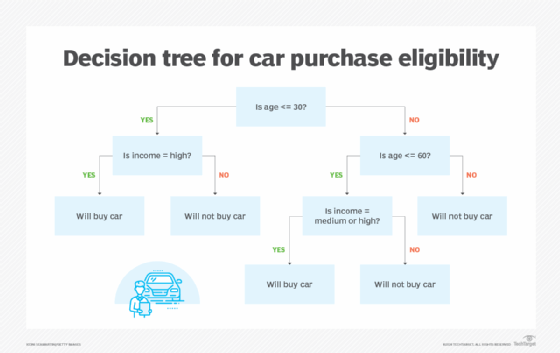
Models based on these algorithms offer an inherent degree of interpretability because the algorithms themselves behave in understandable ways. This contrasts with methods like deep learning, which involves multiple layers of processing. Predicting how a deep learning model will process a given layer -- let alone how it will behave across multiple layers -- is very challenging, leading to low interpretability within deep learning models.
Interpretability for existing models
For existing models, methods like LIME can enhance interpretability. LIME creates new models, called local surrogates, based on interpretable algorithms such as linear regression. These local models interpret the results of the noninterpretable model, providing some ability to predict that model's behavior.
Arguably, this approach generates something closer to explainability than real interpretability because it doesn't provide true insight into a model's internal workings. But it does let developers and users anticipate the model's behavior and influence it by selecting certain types of input. This method is typically the most practical solution when working with black box models that lack inherent interpretability.
Chris Tozzi is a freelance writer, research adviser, and professor of IT and society who has previously worked as a journalist and Linux systems administrator.





