
Getty Images/
How to choose the right LLM for your needs
Selecting the best large language model for your use case requires balancing performance, cost and infrastructure considerations. Learn what to keep in mind when comparing LLMs.

When OpenAI released ChatGPT in November 2022, it demonstrated the potential of generative AI for businesses. By 2024, the large language model space has rapidly expanded, with numerous models available for different use cases.
With so many LLMs, selecting the right one can be challenging. Organizations must compare factors such as model size, accuracy, agent functionality, language support and benchmark performance, and consider practical components such as cost, scalability, inference speed and compatibility with existing infrastructure.
Factors to consider when choosing an LLM
When choosing an LLM, it's essential to assess both the various model aspects and the use cases it is intended to address.
Evaluating models holistically creates a clearer picture of their overall effectiveness. For example, some models offer advanced capabilities, such as multimodal inputs, function calling or fine-tuning, but those features might come with trade-offs in terms of availability or infrastructure demands.
Key aspects to consider when deciding on an LLM include model performance across various benchmarks, context window size, unique features and infrastructure requirements.
Performance benchmarks
When GPT-4 was released in March 2023, OpenAI boasted of the model's strong performance on benchmarks such as MMLU, TruthfulQA and HellaSwag. Other LLM vendors similarly reference benchmark performance when rolling out new models or updates. But what do these benchmarks really mean?
- MMLU. Short for Massive Multitask Language Understanding, MMLU evaluates an LLM across 57 different subjects, including math, history and law. It tests not only recall but also the application of knowledge, often requiring a college-level understanding to answer questions correctly.
- HellaSwag. An acronym for "Harder Endings, Longer contexts, and Low-shot Activities for Situations With Adversarial Generations," HellaSwag tests an LLM's ability to apply common-sense reasoning when responding to a prompt.
- TruthfulQA. This benchmark measures an LLM's ability to avoid producing false or misleading information, known as hallucination.
- NIHS. Short for "needle in a haystack," this metric assesses how well models handle long-context retrieval tasks. It scores an LLM's ability to extract specific information (the "needle") from a lengthy passage of text (the "haystack").
Among these benchmarks and others like them, MMLU is the most widely used to measure an LLM's overall performance. Although MMLU offers a good indicator of a model's quality, it doesn't cover every aspect of reasoning and knowledge. To get a well-rounded view of an LLM's performance, it's important to evaluate models on multiple benchmarks to see how they perform across different tasks and domains.
Context window size
Another factor to consider when evaluating an LLM is its context window: the amount of input it can process at one time. Different LLMs have different context windows -- measured in tokens, which represent small chunks of text -- and vendors are constantly upgrading context window size to stay competitive.
For example, Anthropic's Claude 2.1 was released in November 2023 with a context window of 200,000 tokens, or roughly 150,000 words. Despite this increase in capacity over previous versions, however, users noted that Claude's performance tended to decline when handling large amounts of information. This suggests that a larger context window doesn't necessarily translate to better processing quality.
Unique model features
While performance benchmarks and context window size cover some LLM capabilities, organizations also must evaluate other model features, such as language capabilities, multimodality, fine-tuning, availability and other specific characteristics that align with their needs.
Take Google's Gemini 1.5 as an example. The table below breaks down some of its main features.
| Factor | Gemini 1.5 Pro |
| Multilingual | Yes |
| Multimodal | Yes |
| Fine-tuning support | Yes |
| Context window | Up to 2 million tokens (roughly 1.5 million words) |
| Function calling | Yes |
| JSON mode | Yes |
| Availability | Cloud service only |
| MMLU score | 81.9 |
While Gemini 1.5 has some impressive properties -- including being the only model capable of handling up to 2 million tokens as of publication time -- it's only available as a cloud service through Google. This could be a drawback for organizations that use another cloud provider, want to host LLMs on their infrastructure or need to run LLMs on a small device.
Fortunately, a wide range of LLMs supports on-premises deployment. For example, Meta's Llama 3 series of models offers a variety of model sizes and functionalities, providing more flexibility for organizations with specific infrastructure requirements.
GPU requirements
Another essential component to evaluate when choosing an LLM is its infrastructure requirements.
Larger models with more parameters need more GPU VRAM to run effectively on an organization's infrastructure. A general rule of thumb is to double the number of parameters (in billions) to estimate the amount of GPU VRAM a model requires. For example, a model with 1 billion parameters would require approximately 2 GB of GPU VRAM to function effectively.
As an example, the table below shows the features, capabilities and GPU requirements of several Llama models.
| Model | Context window | Features | GPU VRAM requirements | Use cases | MMLU score |
| Llama 3.2 1B |
128K tokens |
Multilingual text-only |
Low (2 GB) |
Edge computing, mobile devices |
49 |
| Llama 3.2 3B |
128K tokens |
Multilingual text-only |
Low (4 GB) |
Edge computing, mobile devices |
63 |
| Llama 3.2 11B |
128K tokens |
Multimodal (text + image) |
Medium (22 GB) |
Image recognition, document analysis |
73 |
| Llama 3.2 90B |
128K tokens |
Multimodal (text + image) |
High (180 GB) |
Advanced image reasoning, complex tasks |
86 |
| Llama 3.1 405B |
128K tokens |
Multilingual, state-of-the-art capabilities |
Very high (810 GB) |
General knowledge, math, tool use, translation |
87 |
When considering GPU requirements, an organization's choice of LLM will depend heavily on its intended use case. For instance, if the goal is to run an LLM application with vision features on a standard end-user device, Llama 3.2 11B could be a good fit, as it supports vision tasks while requiring only moderate memory. However, if the application is intended for mobile devices, Llama 3.2 1B might be more suitable thanks to its lower memory needs, which enable it to run on smaller devices.
LLM comparison tools
Many online resources are available to help users understand and compare the capabilities, benchmark scores and costs associated with various LLMs.
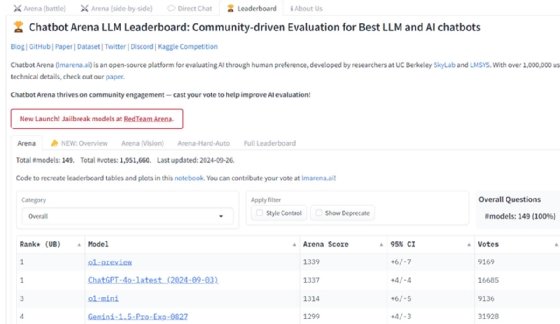
For instance, the Chatbot Arena LLM Leaderboard gives an overall benchmark score for different models, with GPT-4o as the current leading model. But keep in mind that Chatbot Arena's crowdsourcing approach has drawn criticism from some corners of the AI community.
Artificial Analysis is another resource that summarizes different metrics for various LLMs. It shows models' capabilities and context windows as well as their cost and latency. This lets users assess both performance and operational efficiency.

By using Artificial Analysis' comparison feature, users can evaluate not only the specific metrics for a given LLM but also see how it measures up against the array of other LLMs available.
Marius Sandbu is a cloud evangelist for Sopra Steria in Norway who mainly focuses on end-user computing and cloud-native technology.






