How to build and organize a machine learning team
Explore the process of building an ML team, including reasons to build one and descriptions of the core roles of project manager, data engineer, data scientist and ML engineer.

Almost every organization in every industry wants to harness the power of machine learning to make its products, processes or services more innovative, competitive, personalized and efficient. AI and ML are built into almost every networked system and application these days. Whatever the strategic business need might be, having a dedicated machine learning team can be a major competitive advantage and provide maximum flexibility and control over the ML development process and the resulting intellectual property.
Reasons to build a machine learning team
Among the compelling reasons to build a machine learning team are the following:
- The need for innovation. Machine learning is nascent and evolving at a pace that is hard to keep up with. Having a dedicated team researching and implementing the latest advancements in the ML field, such as generative AI, lets an organization achieve cutting-edge breakthroughs. These capabilities can also become valuable new intellectual property.
- The need to develop customized solutions. Prebuilt ML models might not always work well with existing systems. In this case, an in-house machine learning team enables development of tailored implementations that can address specific business needs.
- A desire for a competitive advantage in the market. Machine learning teams can evaluate existing products, services and processes and continuously improve them with ML capabilities that can help the organization stay ahead of market dynamics on an ongoing basis.
- The need for automation and efficiency. A dedicated team can develop ML processes that can automate repetitive tasks, leading to increased efficiency and reduced operational costs.
How is a machine learning team formed?
Machine learning teams are often developed in response to a corporate strategic AI initiative and, as such, might initially work for a funding executive sponsor, such as a chief digital officer who has a strategic need, organizational approval and the funding to support the initiative. The executive sponsor might hire an ML team directly or request resources from the leader of a center of excellence (CoE) responsible for ML inside the organization. The CoE might report to roles such as a chief data and analytics officer, chief AI officer, CIO or chief data scientist. Even if the team starts directly for the funding executive sponsor, it might later become integrated into a CoE so that it can be redeployed for other projects inside the organization -- though it might stick with the initiative until it's formally launched and perform governance duties post-launch.
How does a machine learning team operate?
Many ML development teams work in what can be thought of as an AI pod. Envision a circle with a lead data scientist in the middle orchestrating the machine learning team and communicating and setting expectations with the funding executive sponsor and stakeholders who sit outside of the pod. A project manager, who deals with Scrum issues and time management, sits at the top of the circle. Inside the pod, the ML team members work with each other iteratively until a machine learning model is developed, tested, deployed and governed. The data work starts to the right of the project manager with data engineers who oversee data collection and policy; it then moves around the circle to junior data scientists who provide assistance, continues to the experienced data scientists who deal with model creation and finally moves to ML engineers who work iteratively with the data scientists to deploy and govern the final product.
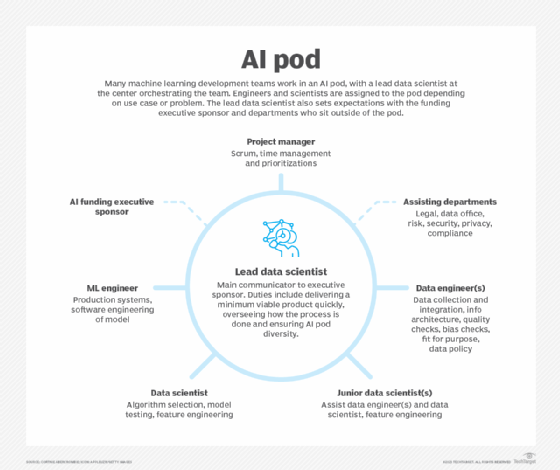
AI pods are empowered to make decisions related to the AI initiative if they meet the executive sponsor's business needs, especially in terms of budget, timing and business outcome. Executive sponsors tend to be treated as stakeholders -- receiving progress updates at key milestones -- rather than true collaborative partners. This is because they generally lack AI literacy. This gap in knowledge is also how some AI pods maintain their sovereignty over their team, product and methods. This sovereignty isn't always a good thing for the executive sponsor or the organization. Some highly ambitious data scientists will exploit this sovereignty and not document their processes, then leave the company for a more interesting or better-paying opportunity. The model and its features could then become more technical debt. It is best for executive sponsors to be trained on basic AI development processes so they can insist on certain best practices -- documentation, for example -- throughout the ML development process.
Core roles on a machine learning team
AI pods have core roles that include project managers, data engineers, data scientists and ML engineers. The following details the duties fulfilled by each role.
Project manager
The main role of a project manager is to help the lead data scientist keep the AI initiative on time, on budget and on goal.
Project manager duties include the following:
- Determining project milestones.
- Work with the ML team and lead data scientist to understand key workstreams.
- Map milestones to deliverable dates and stakeholder meetings.
- Prioritization.
- Hold the ML team to account for completing tasks on time.
- Use agile methodologies to manage tasks.
- Maintaining trustworthiness of the AI project.
- Ensure team does not buy readily available data that could be biased.
- Verify data sets are fit for the purpose of the AI initiative.
- Prevent behaviors that can result in biased or unsafe AI.
Data engineer
One of the most crucial roles on a machine learning team -- and one whose duties can take the longest and be the most tedious -- is that of data engineer. All ML development starts with data. Depending on the project, sourcing where to get data or whether to make synthetic data can cause huge headaches, and that's even before data cleanup and transformation begins. In some cases, the majority of what goes awry with AI is usually related to the data as opposed to the models or production.
Data engineering duties include the following:
- Data collection and integration.
- Gather data from various sources, including databases, APIs, logs and external data sets.
- Ensure data is collected efficiently and is available for analysis in an organized manner.
- Data storage and infrastructure.
- Design, build and maintain data infrastructure, such as data warehouses, data lakes and feature stores.
- Optimize data storage and implement data security measures.
- Data transformation and extract, transform and load processes.
- Transform raw data into a suitable format for analysis, automating data processes.
- Create data pipelines to move and cleanse data.
- Data quality and governance.
- Ensure data quality and validate data integrity.
- Implement data governance policies to maintain data accuracy, reliability and adherence to privacy and security standards.
- Performance optimization.
- Optimize data processing and retrieval to enhance system performance and minimize latency, ensuring efficient data access for data scientists.
- Collaboration with data scientists.
- Work with data scientists to understand their data requirements.
- Develop data models and support the deployment of ML models in production environments.
Data scientist
There are different levels of data scientists. If the AI pod is bigger, there could be junior data scientists who iterate with data engineers regarding data areas related to key features of the model, also known as feature engineering. The more advanced a data scientist is, the more likely they are less involved with data and more involved with optimizing models and understanding the nature of the domain area for which the model will be deployed.
Data science duties include the following:
- Data analysis and modeling.
- Analyze data to identify patterns, trends and insights.
- Create predictive models and develop algorithms to solve complex business problems.
- Machine learning development.
- Design, train and validate ML models using various algorithms and techniques.
- Explore and experiment with different models to find the best fit for the problem.
- Feature engineering.
- Select, transform and create new variables from raw data.
- Model evaluation and optimization.
- Evaluate model performance using defined thresholds or metrics and fine-tune models to achieve better results.
ML engineer
ML engineers focus on the software engineering aspects of developing, deploying and governing ML models within production systems. Their goal is to create scalable, robust ML implementations.
ML engineer duties include the following:
- Model training and validation.
- Train and validate ML models using training data sets and evaluation metrics to ensure models are accurate and generalizable.
- Model deployment.
- Deploy machine learning models into production environments to make them accessible for real-time use. This involves setting up APIs, managing versioning and handling model updates.
- Performance optimization.
- Optimize models for efficiency and scalability, ensuring they can handle large volumes of data and real-time processing demands.
- Software engineering integration.
- Integrate machine learning into existing software systems or build new applications to use the models effectively.
- Testing and debugging.
- Conduct testing and debugging to identify and resolve issues related to model performance or software integration.
- Monitoring and maintenance.
- Monitor the performance of deployed models and maintain them by updating or retraining as necessary.
- Infrastructure and DevOps.
- Work with cloud infrastructure and DevOps teams to set up and manage the necessary resources to run ML applications in a production environment.
Potential challenges in building a machine learning team
The following challenges can pose problems when trying to build an in-house machine learning team.
Retaining talent
One of the first considerations is whether there is enough ongoing work to support a team and keep them engaged. These roles are in high demand, so the lack of an enticing salary or interesting projects might have members leaving for the next big resume-building project.
Cost
Building a team can cost a fortune. Consider augmenting a smaller full-time team with outsourced talent that is employed as needed.
Recruiting ML-skilled people
Machine learning skills are new and hard to find. Even after finding candidates skilled in machine learning, they might not have soft skills such as basic communication. Spend time interviewing in person and having casual conversations to understand how candidates communicate and approach problems.
Diversity
Ensuring a diverse applicant pool can add an extra step to the process, but it's crucial to representing the full breadth of people that can be affected by the product. There are also certain ethnic, cultural, religious and socioeconomic stances that dominate the field depending on what part of the country the organization is in. Opening up the applicant pool by allowing flexible schedules and implementing work-from-home options could garner more diverse applicants. If that's not possible, consider a diverse advisory panel who can weigh in on key decisions.
Finding documenters
All members of the AI pod must be willing to document their processes, from data sources and final features to considerations for model selection to API setup and governance. For ML products to be trusted, development must be fully documented to ensure transparency, explainability, preparations for regulations around bias, data privacy, child protection and more. Some organizations build documentation into their employment contract as a condition of hire; others have implemented workflow systems where next-step approvals aren't given until documentation is uploaded.
Editor's note: This article was updated in June 2024 to improve the reader experience.
Cortnie Abercrombie is a top advisor to Fortune 500 companies on artificial intelligence strategy, development, operating models and building trustworthy AI cultures. She is also the founder and CEO of AI Truth, a nonprofit dedicated to the responsible creation and use of AI.






