
Nabugu - stock.adobe.com
How and why to create synthetic data with generative AI
The data required to train and maintain models is often sparse or inaccessible. Fortunately, generative AI can create synthetic data to supplement real-world data.

Synthetic data -- artificial data created by algorithms -- has become a powerful tool in research and industry, thanks to advances in large language models and other forms of generative AI.
Whether augmenting limited real-world data, protecting sensitive information or enabling model experimentation, synthetic data can help overcome many constraints typical of real-world data sets. But to maximize the potential of synthetic data, data science and AI teams must understand the differences among types of synthetic data, effectively combine structured and unstructured information, and adopt rigorous validation practices.
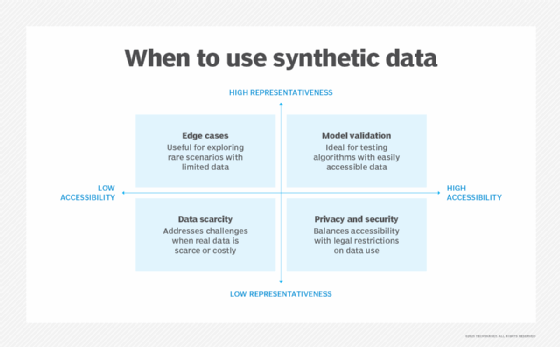
Why use synthetic data?
AI-generated synthetic data can help create large, balanced data sets by emulating patterns found in the real world. Different domains use it for different reasons, such as protecting patient privacy in healthcare, performing stress testing in finance and refining recommendations on streaming platforms.
Common reasons to create synthetic data include addressing data scarcity, preserving privacy and complying with regulations prohibiting the direct use of sensitive data. In scenarios where data accessibility and representativeness are inconsistent, introducing synthetic data can be a game changer.
Benefits of AI-generated synthetic data include the following:
- Improving machine learning (ML) model performance on edge cases by adding supplementary synthetic data for underrepresented scenarios.
- Accelerating development by speeding up experimentation and iteration cycles.
- Enabling model training in a wider variety of scenarios -- for example, when real-world data is limited.
- Strengthening security and preserving privacy by training models without exposing sensitive real-world information.
Types of synthetic data
Synthetic data falls into three categories: structured, unstructured and hybrid. Each entails different techniques and best practices.
Structured
Structured data includes transactional, numeric and categorical information used for statistical modeling, predictions and pattern recognition. It's helpful for handling missing data and for augmenting data to address a lack of variety or volume.
Common techniques for generating synthetic structured data include the following:
- Statistical methods, including both arithmetic operators such as mean, median and mode and ML-based data imputation approaches such as k-nearest neighbors.
- Simulation-based techniques, such as generative adversarial networks and time-series forecasting.
- Data augmentation techniques, which use existing limited data to identify patterns and generate new samples to enrich the baseline data set.
Unstructured
Unstructured data such as text, images and videos support a broader set of use cases, from information extraction tasks like classification and entity detection to generative tasks like question answering and image creation. For example, unstructured data can simulate real-world news articles to test algorithms on their financial analysis capabilities under certain market conditions.
When synthesizing unstructured data, deep learning methods are crucial for handling absent information, diverse formats and large data volumes. LLMs like GPT-4 can supply missing segments for text-based tasks, while techniques such as synonym mapping, sentence variation and grammatical restructuring expand the variety and volume of synthetic text.
In image-related scenarios, convolutional neural networks (CNNs) can fill in missing sections. Standard augmentation strategies like rotation, color scaling and noise addition can also increase the size of data sets and cover more visual variations.
With the emergence of multimodal LLMs capable of working with text and images, prompt engineering and chaining are becoming key strategies for producing high-quality synthetic data. Advanced prompting methods -- such as chain-of-thought reasoning or chained instruction -- can address data gaps and refine outputs. While fine-tuning remains an option for niche domains, many LLMs offer sufficiently accurate outputs for various fields.
Hybrid
Hybrid data blends structured and unstructured elements. For example, a financial model might analyze numerical stock performance metrics (structured) alongside news headlines (unstructured) to assess market sentiment.
To handle hybrid scenarios, extract meaningful features using techniques like named entity recognition, key phrase detection and sentiment analysis. Once significant text features such as entities and sentiments are identified, integrate them with structured data such as numerical market metrics to form a combined synthetic data set.
Prompt engineering, chaining and fine-tuning
Prompt engineering and fine-tuning can improve the overall quality of synthetic data generation. However, prompt engineering, prompt chaining and fine-tuning each have distinct features and trade-offs.
Table 1. Features of prompt engineering, prompt chaining and fine-tuning in the context of synthetic data generation.
| Prompt engineering | Prompt chaining | Domain-specific fine-tuning | |
| Definition | Guiding an AI model's outputs using optimized prompts | Breaking complex tasks down into smaller, sequential prompts, refining results step by step | Adapting a base model's weights using domain-specific data to improve relevance and accuracy |
| Key purpose | Quickly generating relevant synthetic data | Improving control and coherence in multi-step or context-heavy tasks | Embedding domain knowledge to enhance quality, relevance and consistency for specialized fields |
| Advantages | Fast, flexible, minimal setup | Reduced error propagation in complex tasks | Highly customized, reliable results for specific industries or domains |
| Challenges | Output is sensitive to prompt quality, difficult to handle edge cases | Requires careful step design and can be labor-intensive | Requires substantial domain data, time and computational resources |
| Use cases | Quick samples, simple Q&A, single-step tasks | Complex data synthesis tasks | Industry-specific applications (e.g., healthcare, legal, finance) |
Best practices for synthetic data generation
Effectively generating synthetic data requires domain expertise and rigorous validation.
Domain expertise ensures accurate mapping between input and output, which helps simulation methods mirror real-world data sources. Likewise, existing domain data can validate the authenticity of synthetic outputs.
Keep in mind the following best practices for generating synthetic data:
- Compare synthetic data with real-world distributions. Check for consistency in means, variances and correlation structures.
- Use hybrid approaches. Combining rule-based methods with AI-driven generation often yields balanced results.
- Continuously evaluate outputs. Test synthetic data in controlled environments to ensure accuracy and real-world applicability.
Pretrained models tailored to specific fields -- such as FinBERT for finance or BioBERT for medicine -- further refine this approach by incorporating domain-specific vocabulary and structures. However, powerful foundational models capable of few-shot or zero-shot learning might reduce the need for large synthetic data sets altogether.
Priyank Gupta is a polyglot technologist who is well-versed in the craft of building distributed systems that operate at scale. He is an active open source contributor and speaker who loves to solve a difficult business challenge using technology at scale.





