History of generative AI innovations spans 9 decades
The dominance of Nvidia chips, emerging technologies like agentic and embodied AI, and knockoffs of ChatGPT are among the latest milestones powering GenAI's business future.

The buzz around generative AI has intensified in the wake of ChatGPT, which grew to over 100 million users within two months of its launch. But ChatGPT is just the tip of the GenAI iceberg. Emerging technologies include the development of agentic AI in enterprise systems and embodied AI that will support robots, autonomous cars and logistics use cases.
GenAI's history actually goes back nine decades. Though innovations and developments abound, its progress commercially has been relatively slow -- until recently. The combination of larger labeled data sets, faster computers and new ways of automatically encoding unlabeled data has hastened generative AI's development over the past five years. The last year alone has seen near-sentient chatbots, dozens of new services for generating images from descriptions, and the adaptation of large language models (LLMs) to virtually every aspect of business.
Much of today's developments were built on advancements in computational linguistics and natural language processing. Likewise, early work on procedural content generation has led to content generation in games, and parametric design work has set the stage for industrial design. On the horizon are embodied AI systems that learn from interacting with the world, rather than today's LLMs that learn only from what people have written.
90 years and counting
Many key milestones dot the landscape of generative AI's development and innovation.
1932
Georges Artsrouni invented a machine he reportedly called the mechanical brain to translate between languages on a mechanical computer encoded onto punch cards. He built a second version that won the main prize for mechanography at an exhibition in Paris in 1937.
This article is part of
What is GenAI? Generative AI explained
1957
Linguist Noam Chomsky published Syntactic Structures, which describes grammatical rules for parsing and generating natural language sentences. The book also supports techniques like syntactical parsing and grammar checking.
1963
Computer science professor Ivan Sutherland introduced Sketchpad, an interactive 3D software platform that allowed users to procedurally modify 2D and 3D content. In 1968, Sutherland and fellow professor David Evans started Evans & Sutherland. Some of their students went on to start Pixar, Adobe and Silicon Graphics.
1964
Mathematician and architect Christopher Alexander published Notes on the Synthesis of Form, which spelled out principles for automating design that later influenced the parametric and generative design of products. In 1976, he authored A Pattern Language, which was influential in architecture and inspired new software development approaches.

1966
MIT professor Joseph Weizenbaum created the first chatbot, Eliza, which simulates conversations with a psychotherapist. MIT News reported in 2008 that Weizenbaum "grew skeptical of AI" and "was shocked to discover that many users were taking his program seriously and were opening their hearts to it."
The Automatic Language Processing Advisory Committee (ALPAC) reported that machine translation and computational linguistics were not living up to their promises and led to research funding cuts in both technologies for the next 20 years.
Mathematician Leonard E. Baum introduced probabilistic hidden Markov models, which were later used in speech recognition, analyzing proteins and generating responses.
1968
Computer science professor Terry Winograd created SHRDLU, the first multimodal AI that could manipulate and reason out a world of blocks according to instructions from a user.
1969
William A. Woods introduced the augmented transition network, a type of graph theoretic structure for translating information into a form that computers could process. He built one of the first natural language systems called LUNAR to answer questions about the Apollo 11 moon rocks for the NASA Manned Spacecraft Center.
1970
Yale computer science and psychology professor Roger Schank, co-founder of the Cognitive Sciences Society, developed the conceptual dependency theory to mathematically describe the processes involved in natural language understanding and reasoning.
1978
Don Worth created the rogue-like game Beneath Apple Manor for the Apple II while a programmer at UCLA. The game used procedural content generation to programmatically create a rich game world that could run on the limited computer hardware available at the time.
1980
Michael Toy and Glenn Wichman developed the Unix-based game Rogue, which used procedural content generation to dynamically generate new game levels. Toy co-founded the company A.I. Design to port the game to the PC a few years later. The game inspired subsequent interest in using procedural content generation in the gaming industry to generate levels, characters, textures and other elements.
1985
Computer scientist and philosopher Judea Pearl introduced Bayesian network causal analysis, which provided statistical techniques for representing uncertainty that led to methods for generating content in a specific style, tone or length.
1986
Michael Irwin Jordan laid the foundation for the modern use of recurrent neural networks (RNNs) with the publication of "Serial order: a parallel distributed processing approach." His innovation used backpropagation to reduce error, which opened the door for further research and the widespread adoption of RNNs for processing language a few years later.
1988
Software provider PTC launched Pro/Engineer, the first application that allowed designers to quickly generate new designs by adjusting parameters and constraints in a controlled fashion. The solid modeling software, now called PTC Creo, helps companies like Caterpillar and John Deere develop industrial equipment faster.
1989
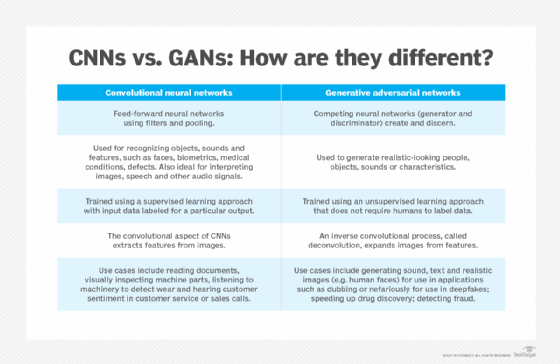
Yann LeCun, Yoshua Bengio and Patrick Haffner demonstrated how convolutional neural networks (CNNs) can be used to recognize images. LeNet-5 was an early implementation of the new techniques for accurately identifying handwritten numbers. Even though it took some time, improvements in computer hardware and labeled data sets made it possible for the new approach to scale up, thanks to the ImageNet database in 2006 and the AlexNet CNN architecture in 2012.
1990
Sepp Hochreiter and Jurgen Schmidhuber introduced the Long Short-Term Memory (LSTM) architecture, which helped overcome some of the problems with RNNs. LSTM gave RNNs support for memory and helped spur research into tools for analyzing longer text sequences.
A team of researchers at Bell Communications Research, the University of Chicago and the University of Western Ontario published the paper "Indexing by Latent Semantic Analysis." The new technique provided a method to identify the semantic relationship between words found in a sample of training text, paving the way for deep learning techniques like word2vec and BERT (Bidirectional Encoder Representations from Transformers).
1991
Lee Alan Westover, in a dissertation at the University of North Carolina at Chapel Hill, laid the foundation for using Gaussian splatting to represent 3D content.
2000
Yoshua Bengio, Rejean Ducharme, Pascal Vincent and Christian Jauvin at the University of Montreal published "A Neural Probabilistic Language Model," which suggested a method to model language using feed-forward neural networks. The paper led to further research into techniques to encode words into vectors representing their meaning and context automatically. It also demonstrated how backpropagation could help train RNNs for modeling languages.
2006
Data scientist Fei-Fei Li set up the ImageNet database, which laid the foundation for visual object recognition. The database planted the seeds for advances in recognizing objects with AlexNet and generating them later.
IBM Watson originated with the initial goal of beating a human on the iconic quiz show Jeopardy!. In 2011, the question-answering computer system defeated the show's all-time (human) champion Ken Jennings.
2011
Apple released Siri, a voice-powered personal assistant that can generate responses and take actions in response to voice requests.
2012
Alex Krizhevsky designed the AlexNet CNN architecture, pioneering a new way of automatically training neural networks that takes advantage of recent GPU advances. In the ImageNet Large Scale Visual Recognition Challenge that year, AlexNet recognized images with an error rate more than 10.8% lower than the runner-up. It inspired research into scaling deep learning algorithms in parallel on GPUs.
2013
Google researcher Tomas Mikolov and colleagues introduced word2vec to identify semantic relationships between words automatically. This technique made it easier to transform raw text into vectors that deep learning algorithms could process.
2014
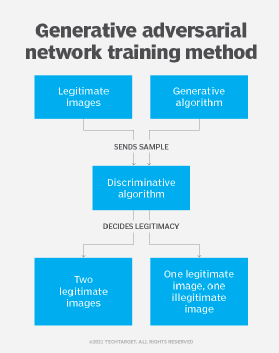
Research scientist Ian Goodfellow developed generative adversarial networks, which pit two neural networks against each other to generate increasingly realistic content. One neural network generates new content while the other discriminates between real and generated data. Improvements in both networks led to better quality content over time.
Diederik Kingma and Max Welling introduced variational autoencoders for generative modeling. VAEs are used to generate images, videos and text. The algorithm found better ways of representing input data and transforming back to the original or into another format.
2015
Autodesk began publishing research on Project Dreamcatcher, a generative design tool that uses algorithms to create new designs. Users can describe intended properties such as materials, size and weight.
Stanford researchers published work on diffusion models in the paper "Deep Unsupervised Learning using Nonequilibrium Thermodynamics." The technique provided a way to reverse engineer the process of adding noise to a final image. It synthesizes pictures and videos, generates text and models languages.
2016
Microsoft released the chatbot TAY (thinking about you), which responded to questions submitted via Twitter. Users soon began tweeting inflammatory concepts to the chatbot, which quickly generated racist and sexually charged messages in response. Microsoft shut it down after 16 hours.
2017
Google announced work on using AI to design the TPU (Tensor Processing Unit) chip for deep learning workloads.
Google researchers developed the concept of transformers in the seminal paper "Attention is all you need." The article inspired subsequent research into tools that could automatically parse unlabeled text into LLMs.
Siemens partnered with Frustum to integrate generative design capabilities into the Siemens NX product design tools. The new capabilities use AI to generate new design variations. PTC, a Siemens competitor, acquired Frustum the following year for its own generative design offering.
Autodesk debuted a commercial implementation of its Project Dreamcatcher research as Autodesk Generative Design.
2018
Google researchers implemented transformers into BERT, which was trained on more than 3.3 billion words, consisted of 110 million parameters and could automatically learn the relationship between words in sentences, paragraphs and even books to predict the meaning of text.
Google DeepMind researchers developed AlphaFold for predicting protein structures. The innovative technology laid the foundation for GenAI applications in medical research, drug development and chemistry. Demis Hassabis, John Jumper and David Baker won the Nobel Prize in Chemistry for their work on AlphaFold six years later.
2019
The Malaria No More charity and soccer star David Beckham used deep fake technology to translate his speech and facial movements into nine languages as part of an urgent appeal to end malaria worldwide.
A U.K.-based energy firm CEO transferred €220,000 ($243,000) to a Hungarian bank after hackers impersonated his parent company boss using an audio deep fake with an urgent request. And the world was alerted to a new era of social engineering cyber attacks.
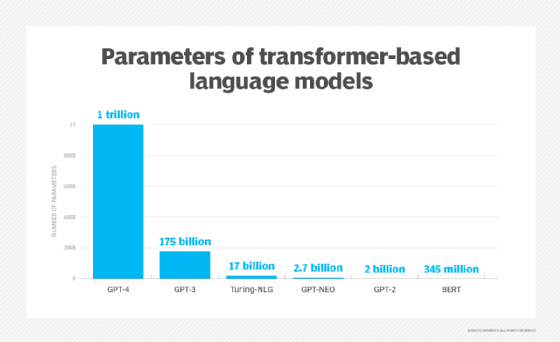
OpenAI released GPT-2 with 1.5 billion parameters. Trained on a data set of eight million webpages, GPT-2's objective was to predict the next word, given all the previous words within some text.
2020
Open AI released GPT-3, the largest ever neural network consisting of 175 billion parameters and requiring 800 gigabytes to store. In the first nine months, OpenAI reported that more than 300 applications were using GPT-3 and thousands of developers were building on the platform.
Researchers at Google, the University of California, Berkeley and UC San Diego published "NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis." The new technique galvanized research and innovation into 3D content generation.
Microsoft researchers developed VIsual VOcabulary (VIVO) pretraining of image captioning algorithms without captioned data. Tests indicated this training can surpass many human captioners.
2021
Cerebras Systems used AI to help generate the design for the WSE-2, a single chip the size of a complete silicon wafer with more than 850,000 cores and 2.6 trillion transistors.
OpenAI introduced Dall-E, which can generate images from text prompts. The name is a combination of WALL-E, the name of a fictional robot, and the artist Salvador Dali. The new tool introduced the concept of contrastive language-image pretraining (CLIP) to rank captions for images found on the internet.
2022
OpenAI released Dall-E 2, a smaller and more efficient image generator that uses a diffusion model to generate images. The AI system can generate images and art from a description in natural language.
Nvidia created NGP Instant NeRF code for quickly transforming pictures into 3D images and content.
Google DeepMind released a paper on Gato, a general-purpose multimodal AI that can perform more than 600 tasks, including captioning text, generating robot instructions, playing video games and navigating environments.
Researchers from Runway Research, Stability AI and CompVis LMU released Stable Diffusion as open source code that can automatically generate image content from a text prompt. This technique is a new method of combining an auto-encoder to transform data into an intermediate format so Diffusion models can process it more efficiently.
OpenAI released ChatGPT in November to provide a chat-based interface to its GPT 3.5 LLM. It attracted more than 100 million users within two months, representing the fastest ever consumer adoption of a service.
2023
Getty Images and a group of artists separately sued several companies that implemented Stable Diffusion for copyright infringement. Their suit claimed Stability AI, Midjourney and DeviantArt, among others, scraped Getty's content without consent.
Microsoft integrated a version of ChatGPT into its Bing search engine. Google quickly followed with plans to release the Bard chat service based on its Lamda engine. And the controversy over detecting AI-generated content heated up.
OpenAI released GPT-4, a multimodal LLM that can receive both text and image prompts. A who's who of technology leaders, including Elon Musk, Steve Wozniak and thousands more signatories, called for a pause on the development of advanced AI systems "more powerful than GPT-4."
A team of French and German researchers built on some of the core innovations in NeRFs but changed how they store data using Gaussian splatting with a new algorithm that is faster to train and render. This galvanized interest in how physical AI and digital twins could use these new techniques to make predictions and generate content.
OpenAI's board of directors fired CEO Sam Altman for failing to be consistently candid in his communications. Employees threatened to quit en masse if he was not restored. Eventually, most of the board resigned and Altman returned. Subsequently, OpenAI downsized, restructured its AI safety team and pivoted from nonprofit to for-profit status.
Google introduced Gemini as consolidated branding for its GenAI efforts in chatbots as well as its many enterprise and consumer AI services to generate text, images and audio.
2024
Agentic AI went mainstream when Salesforce announced a major pivot to Agentforce to implement the technology at scale and with trustworthy guardrails. Other major enterprise vendors, including Microsoft, Workday, Oracle and ServiceNow, followed suit with their own approach to building an agentic AI infrastructure. But there's little integration across these platforms.
Embodied AI gained traction, particularly in robots, autonomous vehicles and more autonomous systems and processes. Traditional LLMs learn from text data, but these new algorithms learn by interacting with the world or simulations of it. Researchers and vendors developed new terminology to describe various components in embodied AI systems, including large action models, large behavior models and world foundation models.
The EU Artificial Intelligence Act was passed, outlining limits on the use of AI models in Europe. Special provisions were called out for open source AI. The U.S. introduced new export controls designed to limit sales of AI chips to foreign adversaries.
Cerebras introduced its WSE-3 wafer-scale AI chip with 4 trillion transistors and 900,000 AI-optimized cores. It claims to run many GenAI training and inferencing processes 10 to 20 times faster than using discrete GPUs.
High-Flyer, a Chinese hedge fund, introduced DeepSeek-V3, which has been reported to achieve results similar to one of the latest flagship models, OpenAI, at a fraction of the cost. V3 is open source, prompting discussions about the merits of adopting proprietary models from vendors like OpenAI and Anthropic vs. open source alternatives that provide greater visibility into the models' underlying mechanics and potential problems.
OpenAI introduced Sora, a text-to-video model that generates short clips based on user prompts. Early teasers show how it could generate highly realistic videos, such as a car driving down a mountain road, short animations and people walking through simulated cities. Sora was later released as an add-on to OpenAI's ChatGPT service and is available for generating short videos, raising concerns about the future of artists, actors and writers in the creative industries.
Elon Musk's xAI venture built a major AI supercomputer in Memphis, Tenn., with 100,000 Nvidia high-end H100 GPUs that were reportedly all connected. Claimed by Musk to be the largest supercomputer ever built, construction was speculated to have taken as little as 19 days and as long as 122 days -- one of the fastest large-scale AI system builds ever reported.
2025 and beyond
Nvidia introduced a new Cosmos platform for building world foundation models using various combinations of LLMs, diffusion and autoregressive models. The software company championed the universal scene description (USD) format as a lingua franca across various digital twin tools and 3D workflows, opening new opportunities for generative physical AI tooling in robotics, autonomous cars, logistics and factory automation.
President Donald Trump, Softbank, OpenAI, Oracle and MGX jointly announced the Stargate Project, an ambitious effort to spend $500 billion on new AI data centers over the next five years. Arm, Microsoft, Nvidia, Oracle and OpenAI are the initial technology partners. The first buildout is underway in Texas, with potential sites in many states from New York to California.
Intel, the leading chipmaker a decade ago and now worth less than Nvidia, announced plans to phase out its new AI chip in favor of a comprehensive data center product for training AI.
Against this backdrop, High-Flyer revealed a new advanced GenAI reasoning model called DeepSeek-R1, allegedly trained at a fraction of the cost of OpenAI's flagship O1 reasoning model. This triggered a $1 trillion drop in the stock price valuations of AI leaders, including Nvidia, Google, Oracle and Apple. Reports from China that the model cost just $6 million to build were dispelled, with the actual cost speculated at about $1.6 billion. OpenAI and Microsoft claimed that DeepSeek training illegally violated terms of use agreements when distilling information from OpenAI during the training process.
The depth and ease of using ChatGPT have shown great promise for the widespread adoption of GenAI. But problems in rolling out the chatbot safely and responsibly have inspired research into better tools for detecting AI-generated text, images and video. Industry and society will also build better tools for tracking the provenance of information used to create more trustworthy AI.
Improvements in AI development platforms will help accelerate research and development of better GenAI capabilities for text, images, video, 3D content, pharmaceuticals, supply chains, logistics and business processes. As good as these new one-off tools are, the most significant impact of GenAI will be realized when these capabilities are embedded directly into better versions of today's tools.
Innovations in embodied AI will begin to shift the focus from what people say about the world to how these systems can interact with the world more efficiently. Early use cases will see value in improving autonomous AI agents that drive processes within various enterprise platforms for CRM, ERP and process automation. Eventually, these innovations will find their way into humanoid robots, self-driving cars and more automated warehouses and self-driving cars.
Grammar checkers will improve. Design tools will seamlessly embed more useful recommendations directly into workflows. And training tools will automatically identify best practices in one area of an organization to help train others more efficiently.
George Lawton is a journalist based in London. Over the last 30 years, he has written more than 3,000 stories about computers, communications, knowledge management, business, health and other areas that interest him.






