Generative models: VAEs, GANs, diffusion, transformers, NeRFs
From powering conversational chatbots to realistic image creators, generative models are critical for many AI applications.

Generative models -- a type of machine learning model that can create new content modeled on training data -- are at the center of AI innovation today. They're the technology that makes generative AI and agentic AI possible.
Generative model design and implementation approaches vary. Depending on considerations such as use case or training data availability, one type of generative model could be better suited than another.
There are five main types of generative models in widespread use today: variational autoencoder (VAEs), generative adversarial networks (GANs), diffusion models, transformers and neural radiance fields (NeRFs). To choose between the generative model options, organizations must explore how each works, along with their strengths, limitations and use cases.
5 main types of generative models
Generative models identify patterns within training data and use those patterns to generate new data through a process known as inference. The new data is similar in form and content to the training data, but it isn't identical.
This article is part of
What is GenAI? Generative AI explained
For example, consider a model trained by parsing thousands of cat images to understand the shapes and colors of cats. If a user asks the model to create a new cat image, the model can build an image based on these visual attributes, but the image wouldn't be identical to any specific cat picture from the model's training data.
Although all generative models use patterns they've identified in training data to generate novel content, how they process and use training data varies.
Here's a look at five common types of generative models:
1. Variational autoencoders
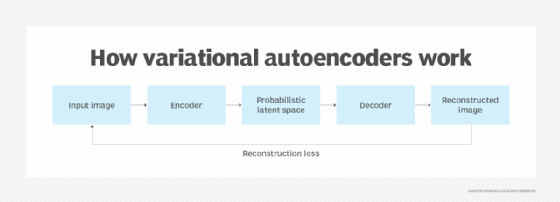
VAEs work using the following process:
- An encoder processes each training data point, then it creates a probability distribution that represents a range of potentially relevant features.
- Data is sampled at random from the probability distribution and compared to the original training data.
- The model assigns a score that reflects how similar the sampled data and the original data are. In cases where the score is high -- meaning the data are similar -- the model flags the sampled data point and the corresponding region of the probability range as relevant data that the model should remember.
- To create new content, the model compares new data input to data that it has stored from sample values. It then creates new content that resembles the accepted sample content it has chosen to remember.
Advantages of VAEs
A key advantage of VAEs is that they use a quantitative approach to managing uncertainty. They use probability distributions and comparison scores to determine the likelihood of relationships existing between two or more data points. This is valuable in situations where training data doesn't fully represent the data that a model is asked to generate or evaluate. VAEs fill in the gaps between training data and inference input by using probability to guess what the values should be.
For this reason, VAEs are especially useful in situations where training data is limited or low quality. VAEs tend to perform better with poor training data than other types of generative models. They're also useful in situations where the attributes of each data sample tend to vary significantly, such as when processing medical images or analyzing the chemical structures of drug molecules.
Disadvantages of VAEs
VAEs' probability-centered strategy means they can overlook fine details. They're less adept than some other types of models, such as GANs, at identifying situations where training data is a perfect match for the new data that a user wants the model to generate.
For instance, when asked to complete the sentence "In 1492, Columbus sailed the ocean [blank]," a VAE might be less likely to answer "blue" because it's more susceptible to considering a range of possible responses, rather than recognizing that "blue" virtually always completes this sentence.
When to use a VAE
VAEs are best in the following scenarios:
- When training data is limited in scope or quantity.
- When output inaccuracies, such as images that appear blurry, can be tolerated.
2. Generative adversarial networks
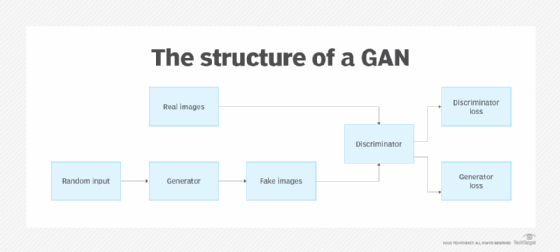
GANs rely on a training process that pits two functions against each other as adversaries. The process works as follows:
- When exposed to training data, a generator creates new data.
- A discriminator compares the data that the generator produced to actual training data.
- The discriminator calculates a score, usually in a 0-to-1 range, that indicates whether the generated data is like the training data.
- The generator receives feedback about how highly its data scored. Using the feedback, it generates a new iteration of the data, which the discriminator again scores.
When training starts, the data the generator creates is essentially random. However, over time, the discriminator recognizes instances where the generator's data resembles the training data. By repeating this process, GAN models gradually learn how to produce new data that closely matches training data.
Like VAEs, GANs also compare generated data to training data. However, whereas a VAE uses probabilistic mapping to predict the similarity between training data and generated data, a GAN iteratively produces generated data that becomes indistinguishable from training data over time. This helps ensure that the new data accurately reflects the training data.
Advantages of GANs
One key advantage of GANs is their accuracy. If the adversarial process continues long enough, GANs learn nuanced details about training data, which they use to create highly realistic content. For example, GAN-produced images tend to be sharper and more detailed than those generated by VAEs.
GANs also can generate new content faster. This is because they don't have to perform a probabilistic assessment when generating new data, so inference requires less computation.
Disadvantages of GANs
GANs typically require more training time because the adversarial process requires additional iterations to produce a reliable and accurate model. It also uses more computational resources during training, which can make GAN training time-consuming and expensive.
GANs also aren't adept at handling training data sets with a large number of outliers. They typically ignore outliers because the generator never produces output that's similar enough to the outlying data points to receive a high score from the discriminator.
When to use a GAN
Consider a GAN model for the following scenarios:
- When highly accurate output is needed.
- When extensive computational power is available for training.
- When comparatively low-cost, fast content generation is required.
3. Diffusion models
Diffusion models work as follows:
- They inject noise into training data, repeating this process until there's no recognizable relationship between the original data and the modified data.
- To create new content, they remove the noise incrementally. However, this denoising process isn't a simple backwards reversal of the process through which noise was originally injected. As a result, the new content ends up being similar to, but not identical to, the original content.
Historically, diffusion models were primarily used for generating images, videos and audio files. Over the past few years, researchers have begun exploring diffusion as an option for text analysis and generation as well.
Advantages of diffusion models
Diffusion models produce highly accurate visual and audio content -- even more accurate than the content generated by GANs in some cases. They're also simpler to train than GANs because they're less prone to risks, such as outlying data points that can contribute to model collapse.
Disadvantages of diffusion models
A drawback of diffusion models is that the noising and denoising processes require significant computing power. As a result, training these models can be costly and time-consuming.
In addition, despite their high level of accuracy, diffusion models are more prone to issues such as overlooking details when generating new content. For example, they might add extra fingers when creating an image of a person. This is mainly because the noising-denoising process is less adept at reliably capturing nuances.
The primary remedy for this is to ensure that training data is sufficiently large and diverse to represent all essential details required for reliable content generation. Diffusion models will typically overlook details that aren't frequently represented in the training data.
When to use diffusion models
Diffusion models work best in the following scenarios:
- When there's a large, diverse set of training data.
- When extensive computing power is available for training.
- When use cases are limited to generating visual or audio content. As noted above, diffusion models also have potential for working with textual content, but this is currently not a mature use case.
4. Transformers
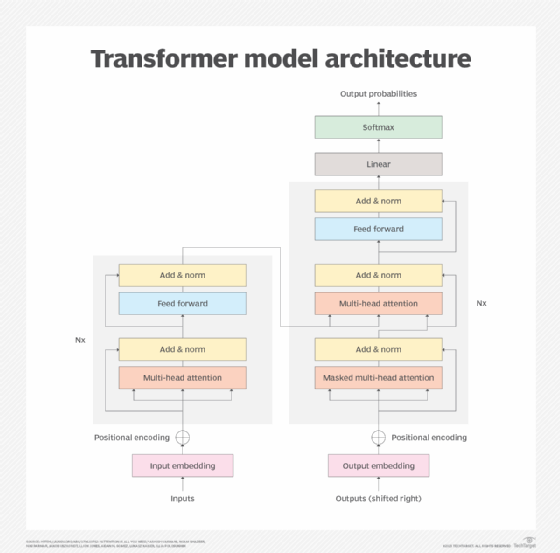
Transformer models are the primary type of generative model behind most of prominent generative AI products, like OpenAI's ChatGPT and Google's Gemini. Transformers use the following attention mechanism process that analyzes training data:
- Input data is broken into tokens that represent parts of the data. For example, if the input data is a sentence, the tokens might be individual words within the sentence.
- The model calculates the importance of relationships between tokens. This is how the model determines which tokens should receive the most attention -- hence the attention mechanism process.
To generate output, transformer models use the results of the attention process to determine which tokens should follow other tokens. This is how they construct novel text.
Advantages of transformer models
The standout advantage of transformers compared to other generative models is that they excel at interpreting context and identifying long-range relationships, making connections between data points that might not be otherwise obvious.
Transformers do this by comparing tokens within different samples from the training data and analyzing how token relationships vary. This is why, for example, a transformer model could understand that the word Washington within a sentence that also includes revolutionary war is likely to have an entirely different meaning from the same word in a sentence that also includes Seattle.
Disadvantages of transformer models
While transformer models are powerful, they require large data sets to train effectively. They also have high computational requirements during both training and content generation. Finally, they have a low degree of model explainability, meaning it can be challenging to determine which training data resulted in which output.
When to use transformer models
Transformer models are ideal in the following cases:
- With a very large set of training data.
- When use cases vary widely, meaning you need to be able to produce a broad set of content.
- When extensive computational resources are available for both model training and inference.
5. Neural radiance fields
NeRFs are primarily designed for generating 3D videos from still images. They work as follows:
- Based on still images, the model generates a series of rays. Each ray is a line that extends from the camera's viewpoint through a specific pixel in the 3D content.
- Using a neural network, the model predicts what the color and density level should be for each point along each ray.
- The model compares the rays it generates to the original images to determine which ones to keep.
By iterating through this process, NeRFs produce 3D content that accurately reflects the content of still images.

Advantages of NeRFs
Although other types of models, like diffusion models, can generate 3D content based on still images, NeRFs are able to do this using comparatively little training data. They also don't require training data that includes 3D content; instead, they're able to construct 3D content by guessing which rays to include based on the content of 2D images.
Disadvantages of NeRFs
NeRFs require substantial computational resources, and the process of generating new content is often slow. This makes NeRFs poorly suited for use cases that require real-time content generation, such as creating dynamic scenery for a 3D game or virtual world. That said, NeRFs work well in situations where 3D content can be produced ahead of time, such as when generating graphics that can be loaded into a video game, rather than being generated dynamically at runtime.
When to use NeRFs
Consider a NeRF for the following scenarios:
- When producing 3D content is the only use case; NeRFs aren't adept at any other type of task.
- When there's limited training data.
- When fast content generation isn't required.
How to choose between generative models
To choose the right generative model for a project, consider the following:
- Intended use. Some models are limited to specific use cases, such as diffusion models, which are typically only suitable for image generation. GANs and transformers are more open-ended and flexible.
- Training data size and quality. If the training data is limited in scope or quality, a model type like VAE might be better at working around these limitations.
- Training time. Some models take less time to train, such as VAEs. Training time depends on how many computational resources the model requires and how much training data it needs to parse.
- Training risks. Some models are less likely to fail during training or require a restart of the training process. For instance, VAEs and diffusion models typically have lower training risks than GANs, which can have high training failure rates.
- Inference time. Inference is faster with some models than others. For instance, GANs are typically faster at generating content than VAEs.
Table 1: Comparison chart of different generative models
Chris Tozzi is a freelance writer, research adviser and professor of IT and society. He has previously worked as a journalist and Linux systems administrator.





