
Getty Images/iStockphoto
Explore the role of training data in AI and machine learning
AI and machine learning models use a variety of learning methods to process and analyze data -- but regardless of how a model is trained, data quality and relevance are crucial.

Data is central to machine learning and AI. Tasks like recognition, decision-making and prediction require knowledge, which can only be learned through training.
Just as a parent teaches their child the difference between a cat and a bird, or an executive learns to identify business risks buried within the minutiae of quarterly reports, ML models need deliberate training on high-quality and relevant data. As AI continues to transform the modern business landscape, the importance of training data is growing.
What is training data?
ML and AI have two principal strengths: spotting patterns in data and making decisions based on data. To perform these tasks, models need a frame of reference. Training data provides models with that frame of reference by establishing a baseline against which models can compare new data.
Consider the cat versus bird image recognition example. ML models can't automatically differentiate among objects; they must be taught. In this case, training data would consist of thousands of images of cats and birds. Each image must be carefully labeled to highlight relevant features -- for example, a cat's fur, pointed ears and four legs in contrast to a bird's feathers, lack of ears and two feet.
Training data is typically extensive and diverse. For this image recognition use case, the data set might include many examples of various cats and birds in differing poses, lightings and configurations. The data should be consistent enough to capture common features yet varied enough to account for natural differences, such as cats with a range of fur colors in crouching, sitting, standing and jumping postures.
Similarly, in business analytics, an ML model must first learn how a business operates by analyzing historical financial and operational data before it can spot problems or recognize opportunities. Once trained, the model can detect abnormal patterns, such as unusually low sales for a certain item, or suggest new opportunities, such as a lower-cost shipping alternative.
Once ML models are trained, tested and validated, they can be applied to real-world data. For the cat versus bird example, the trained model could be deployed to an AI platform that uses real-time camera feeds to recognize animals as they appear.
How is training data chosen?
The old IT axiom "garbage in, garbage out" is particularly relevant to ML training data; ML model outcomes are only as good as their training data. This makes data sources, relevance, diversity and quality vitally important to ML and AI developers.
Data sources
Training data is rarely available off the shelf, although this is changing. Sourcing raw data can be challenging -- imagine locating and obtaining thousands of images of cats and birds for the relatively simple model described above.
Moreover, raw data alone isn't nearly enough for supervised learning. It must be carefully labeled to highlight the key features that the ML model should focus on. Proper labeling is an art form; messy or poorly labeled data can have little to no training value.
In-house teams can collect and annotate data, but this is often expensive and time consuming. Alternatively, businesses can source data from government databases, open data sets or crowdsourced efforts, although these sources all require close attention to other data quality criteria. In short, training data must provide a complete, diverse and accurate representation for the intended use case.
Data relevance
Training data must be timely, meaningful and relevant to the subject at hand. For instance, a data set with thousands of animal images but no cat pictures would be useless for teaching an ML model to recognize cats.
Similarly, training data must relate directly to the model's intended purpose. As an example, business financial and operational data might be historically accurate and complete, but if it reflects outdated workflows and policies, any ML decisions rendered today would be irrelevant.
Data diversity and bias
A sufficiently diverse training data set is crucial for building an effective ML model. If a model's aim is to identify cats in different postures, its training data should include pictures of cats in a variety of poses.
Similarly, if the data set only represents black cats, the model's ability to identify white, calico or gray cats might be limited. This phenomenon, known as bias, can lead to incomplete or inaccurate predictions and hinder model performance.
Data quality
Training data must be high quality. Issues such as inaccuracies, missing data or poor resolution can significantly affect a model's effectiveness.
For instance, a business's training data might include customer names, addresses and other details. But if any of those details are missing or wrong, the ML model will likely fail to deliver expected results. Likewise, poor-quality images of cats and birds that are far away, blurry or dimly lit, undermines their usefulness as training data.
How is training data used in AI and machine learning?
Training data is fed into an ML model, where algorithms analyze it to identify patterns. This enables the ML model to make more accurate predictions or classifications on future, similar data.
There are three main types of training techniques:
- Supervised learning uses annotated data to illustrate relevant features, with humans responsible for choosing, labeling and otherwise refining the data. Human feedback plays a direct role before, during and after model training.
- Unsupervised learning lets ML models find patterns in unlabeled raw data using techniques such as clustering. This largely removes humans from the training process, although feedback might be used to evaluate the model's output.
- Semi-supervised learning is a hybrid of supervised and unsupervised techniques. Advanced approaches, such as many-shot, few-shot and one-shot learning, often fall under this general category.
Where does reinforcement learning fit in?
Instead of relying on predefined training data sets, reinforcement learning takes a trial-and-error approach, in which an agent interacts with its environment. Feedback in the form of rewards or penalties helps the agent improve its strategy over time.
Whereas supervised learning relies on labeled data and unsupervised learning finds patterns in raw data, reinforcement learning focuses on dynamic decision-making. It prioritizes ongoing experience over static training data, making it a useful approach for robotics, gaming and other real-time applications.
Consider the role of humans in a simple supervised training process:
- Raw data. Most supervised training starts with raw data, as substantial and appropriate prelabeled data sets are rare. This data can be collected from different sources or even generated in-house.
- Annotated data. Raw data is curated and labeled to ensure relevance and highlight salient elements for the ML model to learn. Annotation is almost always performed by humans, such as data scientists.
- Model ingestion. The model ingests the annotated data, isolating and processing the desired elements. This is where the learning takes place. Although the process is largely automated, it is often resource intensive and time consuming.
- Model output. Once trained, the model makes predictions on test data, which are checked for accuracy to validate its performance. If the model's output is correct, it is ready for deployment. Otherwise, human operators provide feedback to the model to inform its decision-making, investigate and correct training data issues, and further optimize and refine the model through additional training.
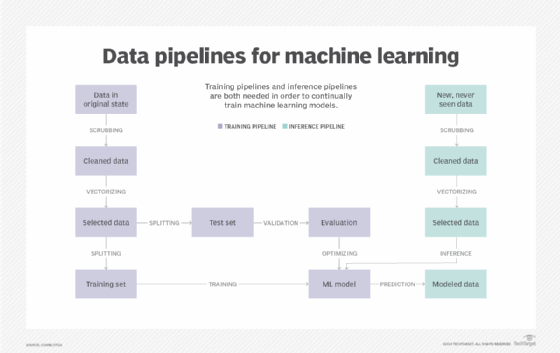
Training data vs. testing data
After training, ML models must be validated through testing, much like how teachers quiz students after lessons. Test data ensures that the model has been trained properly and can deliver results within a desirable range of accuracy and performance.
For supervised learning, training data is labeled to help the ML model identify and learn relevant patterns, while testing data is not labeled and is provided in a raw form similar to real-world data. In unsupervised learning, both training and testing data are typically unlabeled; the test data serves to evaluate whether the patterns the model discovered are generalizable beyond the specific examples seen during training.
The process of dividing data into training and testing sets is called data splitting. Testing data should be different from training data, although the two sets will share certain similar characteristics. The goal of training is to identify patterns in the data, so reusing training data for testing wouldn't accurately gauge the model's predictive abilities. Using a separate data set makes it possible to gauge a model's accuracy with far greater confidence.
Testing data can also be reused to periodically reevaluate a model's performance over time, especially after additional training or feedback. Static models with no subsequent retraining should maintain the same output accuracy, but updated models can be retested to see how performance changes over time.
Stephen J. Bigelow, senior technology editor at TechTarget, has more than 20 years of technical writing experience in the PC and technology industry.






