AI model optimization: How to do it and why it matters
Challenges like model drift and operational inefficiency can plague AI models. These model optimization strategies can help engineers improve performance and mitigate issues.

Organizations across industries are building AI models, but the process doesn't end when the model is successfully deployed. Equally important is optimizing the AI model to ensure that it delivers the best results as efficiently as possible.
Optimization is one way for AI and machine learning engineers to improve their AI models. Optimization strategies, such as retraining models with better data or enhancing models' source code, can benefit performance, efficiency and accuracy. By enhancing operational efficiency and model effectiveness, engineers can ensure their AI model overcomes challenges, like model drift, and becomes an asset to the company.
What is AI model optimization?
AI model optimization is the process of improving an AI model. AI and machine learning engineers can use model optimization to pursue two main goals: enhancing the operational efficiency of the model, and enhancing the effectiveness of the model itself.
Model operation enhancements
Operational model optimization means making changes to a model that enable it to operate more efficiently. For example, tweaking the code behind a model might help it consume less memory or CPU time, leading to lower infrastructure overhead (and, potentially, reduced costs) when operating the model. Changes to a model's design could also shorten the time it takes to produce results, leading to faster decision-making.
This article is part of
What is enterprise AI? A complete guide for businesses
Model effectiveness enhancements
Effectiveness optimizations improve the accuracy and reliability of the results a model produces. For instance, by retraining a model on higher-quality or more representative data, engineers could improve a model's decision accuracy rate from 95% to 98%.
The importance of model optimization
Model optimization is important because more efficient, accurate and reliable models create more value. Efficient models cost less to run, and highly accurate models deliver better results.
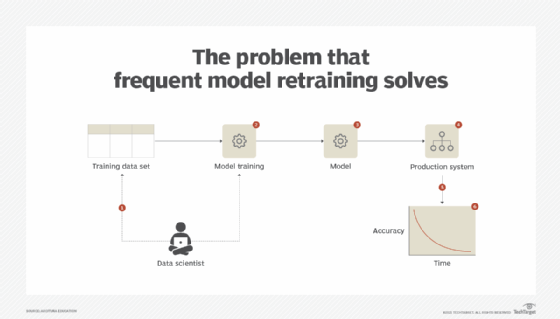
That said, AI model optimization is about more than just trying to improve models over time. It's also often a necessary process for addressing challenges like AI model drift. Model drift can occur when a model becomes less efficient due to changes in the environment that hosts it, such as installing a different version of a software library that a model depends on.
Model drift might also happen if the data that engineers used to train a model no longer accurately represents real-world conditions, causing the model to make suboptimal inferences, a phenomenon also known as data drift. Model optimization lets engineers improve their models in response to challenges like these so that the models remain as efficient and effective as possible.
AI model optimization strategies
A variety of strategies are effective for AI model optimization, but the following are some of the most common approaches.
Retraining on better data
Retraining a model on data that is more accurate or representative of real-world conditions is one of the most straightforward ways to optimize a model.
However, retraining only makes sense if the data that the model initially trained on was not of high quality or if the data no longer represents real-world conditions. If the training data wasn't a problem and current data isn't substantially different, retraining is not likely to help with optimization.
Deployment modification
Changing how models are deployed can optimize outcomes. For instance, a model that struggles to produce results quickly might perform better if it is rehosted on hardware with more resources.
If the model itself is inefficient, redeployment into an environment with more resources is a temporary fix rather than a true optimization technique, because it doesn't address the root cause of inefficiency. Nonetheless, it can lead to short-term enhanced performance.
Source code enhancements
Models that were poorly designed or implemented might benefit from changes to their algorithm's source code. For example, switching to a different library or framework might result in better performance if the new library or framework is more efficient.
Source code modifications require significant effort, and engineers typically need to retrain the updated model afterward. In most cases, making changes to the model's algorithms is an optimization strategy that should be used sparingly and only if engineers believe the rewards outweigh the effort.
Model pruning
Model pruning is the removal of some parameters from a model, leading to a smaller model that runs with fewer resources. If the model contains parameters that aren't necessary for the use cases it needs to support, pruning can lead to better model performance without reducing the effectiveness of the model.
Data set distillation
Data set distillation is the process of consolidating a large data set into a smaller one. This can enhance AI model performance by reducing the amount of data that the model needs to parse.
Distillation won't directly benefit deployed models because those models are already trained. However, it can make it easier to retrain models as part of an AI optimization strategy because there is less data to retrain on. It can also help remove inaccurate or unimportant data from a data set, leading to more effective decision-making once the model is retrained.
Regularization
To work effectively, AI models must achieve the right fit with the data they ingest. If a model is unable to interpret data effectively, it is underfitted. If it interprets data inconsistently -- meaning it doesn't make accurate decisions based on real-world input even though it trained accurately -- it's overfitted.
Regularization can help address both underfitting and overfitting. In essence, regularization modifies the weight that a model assigns to different types of data to improve the model's ability to interpret data accurately.
Chris Tozzi is a freelance writer, research advisor, and professor of IT and society who has previously worked as a journalist and Linux systems administrator.







