
Getty Images
Best practices for real-world ML deployment
Deploying machine learning models to production is complex, with many potential pitfalls. Use this technical roadmap as a guide to navigate the process effectively.

Machine learning has become a core part of modern business operations, offering powerful insights and automation capabilities. However, transitioning ML models from development to production environments remains a challenge for many organizations.
This practical guide is designed to assist technical teams in successfully deploying ML models to production. First, learn how to address common obstacles, such as model versioning, mismatched environments, scalability and hosting concerns. Next, establish a set of tools and best practices for each stage of the deployment process.
ML deployment challenges
Transitioning machine learning models from development to production involves complex challenges, each of which can significantly affect deployment success and long-term system performance.
First, managing model versions is critical for reproducibility, debugging and rollback scenarios. In a development environment, it is common to experiment with different model architectures, hyperparameters and preprocessing methods. Without proper version control, it can become nearly impossible to track which version of the model performed best or which is currently deployed.
Second, mismatched environments between development and production frequently cause issues. A model trained on a local machine with certain Python libraries or hardware configurations might behave differently when deployed on production servers or cloud platforms.
Lastly, scaling ML models is both critical and challenging, especially when user demand grows or inference latency becomes an issue. When a model is deployed in production, it must handle varying levels of traffic, from sporadic use to heavy workloads. For instance, an e-commerce recommendation system must process real-time data and serve predictions to millions of users on typical days as well as during the surge of holiday shopping.
Scaling models also requires optimizing resources. Running multiple instances of a model can be costly in terms of computational and storage demands.
Best practices for successful machine learning deployment
To combat challenges and deploy and maintain models in production successfully, follow these strategies for model versioning, environment consistency, scaling and cloud vs. on-premises hosting.
Model versioning
For model versioning, adopt tools like MLflow, DVC or Weights & Biases, which are purpose-built for managing ML model lifecycles. They let users log and track artifacts such as data sets, models and hyperparameters alongside the source code.
Use these tools in combination with GitHub or other source code repository services, such as Azure DevOps, which can track models' code and configurations. Then use CI/CD pipelines such as GitHub Actions to automate testing, validating and deploying new model versions.
Environment consistency
Another critical step is maintaining consistency between development, staging and production environments. A consistent setup ensures that models perform as expected, regardless of where they are deployed. Tools like the following can help achieve environment consistency:
- Docker containers. Docker enables developers to package models, their dependencies and their runtime environments into a single container. Many models are combinations of multiple Python packages and R code, with different dependencies on specific versions of Python. Packaging them into a Docker container ensures that the same environment is replicated across development, staging and production.
- Environment management. Use tools like Conda to manage dependencies and lock versions. This helps prevent issues caused by mismatched library versions across environments.
- Infrastructure as code. Combine Docker with IaC to ensure that infrastructure and application dependencies are both version controlled and reproducible, reducing the risk of discrepancies across development, testing and production setups. IaC tools like Terraform and Pulumi enable consistent provisioning across environments.
Scaling models in production
Scaling models often involves managing and running Docker containers in a production environment. One of the most common approaches is using Kubernetes.
Kubernetes can scale containers based on specific metrics such as CPU, memory or GPU utilization. This is crucial for ML workloads, which often involve compute-intensive tasks like model inference or batch data processing.
Kubernetes also enables precise allocation of resources. For example, an inference service might require only a fraction of a GPU, while a training job could consume multiple GPUs across nodes.
On-premises vs. public cloud hosting
Another aspect of scaling is determining when to choose on-premises vs. public cloud to host ML models. Although running models on Kubernetes is one option, many cloud providers also have PaaS services that can host the different models, abstract away much of the complexity and handle scaling automatically. Services like Azure Machine Learning or AWS SageMaker provide a way to host ML models as a service.
Both the PaaS services and MLflow provide real-time monitoring of model training, inference and the underlying compute resources. They also provide a way to update or change the underlying models automatically for limited to zero downtime on the services that rely on the ML models.
Scalability is one of the main advantages of using a public cloud. These services provide elastic scaling -- automatically adjusting resources based on demand -- which is ideal for workloads with variable traffic. In contrast, on-premises infrastructure requires manual scaling, such as adding hardware or setting up Kubernetes clusters. On-premises options can handle predictable workloads well, but they are less flexible and might struggle with scaling as demand fluctuates.
However, make sure to evaluate the limitations of cloud services compared with running models on private infrastructure. Also, many PaaS services can be quite expensive compared with running models directly on Kubernetes or in a standalone container.
Steps to deploying an ML model locally
The diagram below demonstrates an example environment, where a data scientist or analyst is training a model using data accessed via a data platform like Microsoft Fabric, Databricks or Snowflake.
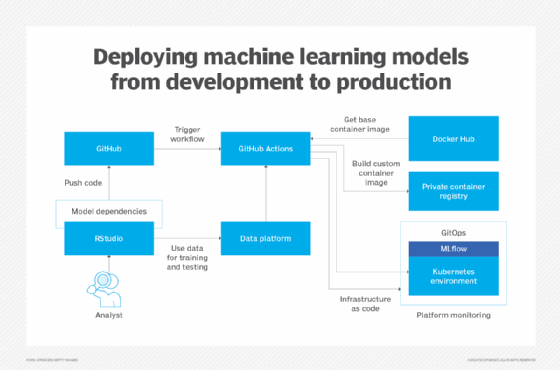
When training locally, developers might test using Python modules or R packages running in Docker images on their machines. Once the model is complete, the developer pushes the Docker configuration and application code to GitHub.
This triggers a GitHub Action workflow, which uses the configuration and base container images from Docker Hub. For example, a base Python image from Docker could be combined with the model specification to create a new set of Docker images that contain the complete model with dependencies.
The resulting Docker image is stored in a private container registry, which acts as a repository for Docker images. Developers can then update the MLflow environment on Kubernetes to start using the new model.
To update models from one version to another, teams can adopt a GitOps approach, where the code stored in GitHub acts as the source of truth. In this scenario, the Kubernetes configuration is a manifest that specifies how the environment should look.
GitOps ensures that any changes made to the configuration are committed to the repository, creating a single source of truth for deployment. This method enables version control, auditing and rollbacks, making it an effective choice for managing MLflow environments.
Deploying new models can also be integrated into a GitHub workflow as a staged process. For example, models can first be deployed to a preproduction environment to validate their functionality on Kubernetes before pushing them to production.
Editor's note: This article was originally published in January 2025. Informa TechTarget Editorial updated it in May 2025 to improve readability.
Marius Sandbu is a cloud evangelist for Sopra Steria in Norway who mainly focuses on end-user computing and cloud-native technology.
Dig Deeper on AI technologies
-
![]()
Jozu drives open source ModelPack & KitOps Modelkit
By: Adrian Bridgwater
-
![]()
KCNA Exam Dumps and Kubernetes Cloud Native Associate Braindumps
By: Cameron McKenzie
-
![]()
Struts 2 development with the Eclipse IDE tutorial
By: Cameron McKenzie
-
![]()
Docker run vs docker-compose: What's the difference?
By: Cameron McKenzie



