Limits of AI today push general-purpose tools to the horizon
The future of AI should be focused on more general-purpose tools, but developers have a long way to go before achieving the kind of AI movies taught us to expect.

When we watched Star Trek and 2001: A Space Odyssey, we developed a very specific idea of artificial intelligence as a humanlike, or even superhuman, entity that can live in starships or computers and answer any question in real time based on humanity's collective knowledge.
Today, AI is the most talked-about topic in enterprise IT, with all major enterprise software vendors aggressively promoting their stories. However, the limits of AI today make the technology very different from what the movies taught us to expect. This does not mean that AI today cannot provide ROI. But we need to continue pushing toward the next frontier of a more general AI approach that develops universal problem-solving capabilities with minimal supervision and significantly reduced training requirements.
What AI should be
If AI and machine learning are everywhere, why do employees still get bogged down with so many tedious, manual tasks? Why can't an application on my laptop look at my calendar invites and book flights, hotels and rental cars based on my schedule? Why can't it remind me of conferences that are relevant to my field? Of course, it should also monitor my credit card bill, Uber account and airline and hotel charges to automatically create my expense report. And when I write a paper or prepare for a presentation, it should automatically surface relevant contextual info based on the audience, my personal preferences and current industry trends and events.
The difference between the AI scenario described above and today's reality is rooted in the fact that neural networks and reinforcement learning models require too much manual architectural training and deployment effort. Neural networks are best at solving problems through reliance on massive number-crunching without much contextual awareness.
AI tools that perform a broad range of tasks, like object and facial recognition, speech-to-text transcription and optimization of logical unit numbers on a storage array, all have one thing in common: They use a large amount of processing power to analyze hundreds of thousands of training data points to identify subtle correlations between many features. However, each one of these AI models needs to be trained, configured and architected to be used for a single task, which is one of the major limits of AI today.
When asked whether a given photo was taken on Mercury or on Earth, for example, a human will most likely know that there is no camera located on Mercury, so he or she can infer that the photo can only have been made on Earth. An untrained neural network will simply find no matches of Earth or Mercury landscapes and not return a result. It cannot generalize common principles and concepts but exclusively relies on the patterns it has identified within each training set. While an untrained human can figure out how to solve many advanced tasks and challenges without any specific training, the limits of AI mean it does not have this ability.
Delayed rewards as the key to unlock a strategic AI
Google's AlphaGo managed to beat the world's best Go players only after the AlphaGo project team created an algorithm that goes beyond simply optimizing its next move. AlphaGo learned to play sophisticated strategies that led to reliable wins over human opponents by gradually identifying human players' weaknesses and by playing thousands of simulated games against itself. The reinforcement algorithm encouraged AlphaGo to make unexplored moves. When these moves led to a loss, AlphaGo would explore different moves, always rewarding game wins and avoiding moves that were similar to the losing ones.
AlphaGo's reward algorithm could be seen as a starting point. But instead of merely rewarding positive behaviors and penalizing negative ones, future, more general AI applications need to explore a much more constructive approach for complex problem-solving. This approach could be called "strategic curiosity," and it is inspired by the concept of the Memory, Attention and Composition (MAC) network -- pioneered by Stanford researchers Christopher Manning and Drew Hudson. The term strategic curiosity refers to the idea of training an AI to make educated guesses based on what it knows about the environmental context that is relevant to its specific task.
The core idea of Manning's MAC network is to provide the learning network with a knowledge base that it can use when working on answering a specific user question, such as: Which planet is second closest to the sun and has a ring around it?
The network trains on a few thousand natural language questions and answers, such as: Which planets are blue? Is Venus further from Earth than Jupiter? What is the third largest planet? Traditional neural networks, by comparison, require hundreds of thousands, or even millions, of examples in training data sets, one of the major limits of AI today.
Based on this training and a knowledge base -- in this case, the planet map below -- the MAC network can respond to our natural language question with a much higher accuracy than traditional neural networks.
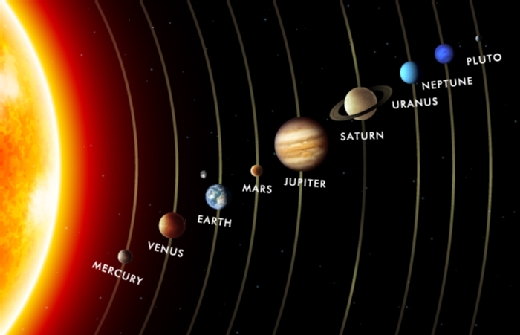
Here are the stages of the model's decision process:
- The model looks at the first part of the question -- second closest to the sun -- and focuses its attention on Venus.
- The model looks at the second part of the question -- planets with rings -- and sees that Uranus comes after Saturn among planets with rings.
Why is this simple example so interesting? Because the MAC network model is able to answer each part of a question by memorizing relevant content knowledge it gained from understanding the individual components of that question. In our example, the MAC network keeps the fact that it knows that we are looking for something that is the second closest to the sun in memory. Then, when the next MAC cell responds to the second part of the question -- "has a ring around it" -- it adjusts its answer based on contextual knowledge it previously learned.
Bringing back the excitement to AI
Manning's MAC network, while still in its adolescence, shows the potential of bringing AI to the next level by modeling the ability of our brain to learn from context. When asked questions, like "Which color are this tree's leaves?" the human brain will instantly make our eyes look up into the tree, instead of scanning our entire field of view. Even more, our brain would already know from context that it is summer and all the trees on our street have green leaves. Of course, the MAC network is still far away from this type of reasoning, but it is significant, as this type of breakthrough keeps the AI excitement going strong.





