
vchalup - stock.adobe.com
KDD in data mining assists data prep for machine learning
While data scientists are often familiar with data mining, the deeper knowledge discovery in databases (KDD) procedure can help prepare data to train machine learning algorithms.

A machine learning application's value is dependent on the quality of data used to train and deploy it. Organizations are responsible for creating or acquiring enough data, that this data is useful for the specific application and that the analytics team is capable of sorting through and learning useful things from it.
The knowledge discovery in databases (KDD) finds knowledge in data; organizations use data mining methods to draw out its usefulness.
KDD vs. data mining
While most data scientists are familiar with data mining, KDD is a specialized process that applies high-level, sophisticated data mining techniques to find and interpret patterns from data. Though the terms are sometimes used interchangeably, KDD is used especially for machine learning, databases, pattern matching, AI and enterprise use.
"[In comparison], the term data mining is broadly applied to looking through piles of data and trying to find interesting patterns," said Peter Aiken, associate professor at Virginia Commonwealth University.
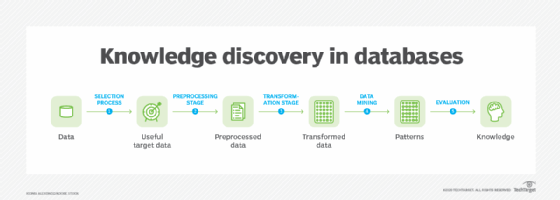
In general, these processes both extract data from large databases, but KDD is more often used to explain the larger picture. There are varying divisions of the steps of KDD but in general they can be broken down into several steps:
Step 1: Selection -- Sort out the data you would like to mine.
Step 2: Preprocessing -- Data cleaning (removing any noise or outliers within the data set) using statistical techniques or data mining algorithms.
Step 3: Transformation -- Data is prepared and developed through dimension reduction and attribute transformation. This step may be quite project-specific but always crucial to the success of the project.
Step 4: Data mining -- Outline what kind of data mining would be most useful by judging which objective you are seeking (prediction or description).
Step 5: Interpretation/Evaluation -- Assess and interpret the mined patterns, rules and reliability in comparison to the original objective.
Association rules
Data mining is the process of identifying patterns and establishing relationships by sorting through data sets. Within this broad definition are association rules that analyze the data set for if/then patterns and use support and confidence criteria to locate the most important relationships. Support is how often items appear in the database and confidence is the amount of if/then statements that are correct.
Among the more common data mining parameters include anything from sequence analysis, classification and clustering, as well as forecasting.
Sequence analysis. Identifies patterns where one event points to another, later event.
Classification. Looks for new patterns and can change the way in which the data is organized.
Clustering. Locate and document groups of facts that had not been known yet. Groups are organized by how similar they are to one another.
Forecasting. These parameters within data mining discover patterns in data that point to reasonable predictions.
This is all a relatively manual process, however. Human intervention and decision-making come to play majorly in the KDD/data mining process. This is one of the largest differentiators from a similar process, machine learning. When it comes to machine learning, the quality of data is crucial and data mining allows for better insight to be drawn out from this data.
"Usually the most critical thing in [removing deficiencies in] performance of your model is also usually the most critical step in getting your model put into production," said Kjell Carlsson, a Forrester Research analyst.
KDD, data mining and machine learning
If an enterprise is working on a machine learning project, then some form of the KDD process is also going on in-house. Both fall under the umbrella of data science and both processes are used for solving complex problems with data.
"The real question is from a user's perspective, what are you trying to do," Aiken said. "And if the data that you're trying to use is more likely to come from a database than a big data pile."
Machine learning and data mining share the same principles but function differently. A data scientist turns to data mining to pull from existing information to find emerging patterns that can help shape decision-making processes. Machine learning is more active and less hands-on. Machine learning takes this process a step further because it can learn from the existing data and teach itself what to look for in the future and predict patterns. Data mining is typically used as an information source from which a machine learning algorithm can learn.
Both are analytics processes that are good with pattern recognition and are therefore often confused. Machine learning may use some data mining techniques to build its models and data mining can use machine learning techniques to produce more accurate analysis.
"The biggest problem with computer science in today's environment is that machine learning algorithms don't have training data," Aiken said.
Without training data, a machine learning model is unable to reach any kind of effective performance. As Aiken sees it, any boasting about a model without data is like saying well you've got this great baseball team you just have to teach them how to play baseball.
Uses of KDD/data mining and machine learning
Data mining and the overall process of KDD have carved out their own specialty. Data mining has been deployed in the retail industry in order to better understand the patterns of customer buying habits. Organizations can mine their customer data for relevant information on the success and failure of items and adjust from there.
It has also been used in finance by organizations looking into potential investments and whether a new organization is going to succeed. Past performance of successful startups, as well as patterns of indicators of business prowess, inform those in the finance industry of where to put their money.
Machine learning's applications vary widely across industries for purposes such as fraud detection, autonomous vehicles and personalized marketing, among others. Organizations turn to machine learning algorithms to analyze vast amounts of data and provide continued growth and value as more data is brought in.
Machine learning algorithms can function better with relevant data sets and these can be brought about through the process of data mining.






