
Interpretability vs. explainability in AI and machine learning
Understanding how AI models make decisions is challenging, but two concepts -- interpretability and explainability -- can shed light on model outputs.
Imagine you're a doctor using a new AI tool that suggests an atypical treatment plan for a patient with a complex medical condition. How do you know whether the model's recommendation is trustworthy -- especially if the reasoning behind the decision isn't clear?
Machine learning models are sometimes described as black boxes because their decision-making processes are opaque to observers. But as AI and machine learning become more common, including in potentially risky use cases, model developers are increasingly expected to ensure that models' decisions are justifiable, transparent and trustworthy.
In the above example, you might know that the model has analyzed hundreds or thousands of individual data points -- lab results, medical images, patient demographics -- but as a physician, you would also need to understand why it drew a certain conclusion from that data. Interpretability and explainability are two computer science concepts that aim to address such scenarios by making models and their outputs easier to comprehend.
What is interpretability and how does it work?
Interpretability describes how easily a human can understand why a machine learning model made a decision. In short, the more interpretable a model is, the more straightforward it is to understand.
An interpretable model is designed so that human observers can map model inputs to model outputs. Consequently, interpretable models are usually simpler, such as decision trees and linear regressions. Because their mechanisms are fairly easy to follow, it's possible to directly observe how input influences output.
Interpretability can be either global or local. A globally interpretable model has an overall structure that is generally understandable, whereas a locally interpretable model's individual predictions can be understood and traced. Decision trees, for example, are typically both globally and locally interpretable: They have an overall rule set that applies across the board, and it's also possible to trace the decision process from a specific input to a specific output.
Why interpretability matters
The ability to understand a model in this way matters for a few reasons. For one, a more transparent model is usually more trustworthy because it's easier to verify and evaluate. This is especially important in highly regulated fields like medicine and banking, where AI tools need to comply with relevant laws and ethics standards.
Interpretable models are also usually easier to debug and optimize. If a model produces an unexpected output, developers can figure out why -- and then fix the problem -- much faster if they know how the model arrived at that decision. In contrast, complex deep learning models, such as the large language models powering tools like ChatGPT and Claude, might produce problematic outputs that are impossible for developers to fully understand and fix.
Limitations and tradeoffs
The major downside of interpretable models is that their simplicity can negatively affect performance. A straightforward linear regression can't capture the same complex patterns and interrelationships that a deep neural network can, for example. Likewise, the bigger a decision tree gets, the harder it is to trace how inputs travel through its various decision pathways.
In the real world, especially when building large models for business analytics or consumer applications, AI engineers and data scientists therefore face a tradeoff between interpretability and predictive power. A highly interpretable model might not be the most efficient or accurate choice for identifying complex patterns and relationships in enormous data sets.
What is explainability and how does it work?
Explainability, like interpretability, attempts to show why a machine learning model made a given decision. But unlike interpretability, explainability doesn't require observers to understand the model's inner workings. This makes it an especially useful framework for dealing with complex models, like neural networks.
Explainability methods are applied after a model has already made its decision or prediction. Although the explanation might not clarify exactly how the model works, it offers insight into which features or variables played into the outcome. And because explainability techniques are applied after the fact, they can be used with any model, no matter its architecture.
Compared with interpretability, explainability is more local by nature. That's because it inherently focuses on explanations of individual decisions, not the model as a whole. These local insights can be aggregated to explain the model's behavior across a larger set of inputs, but that process can't provide the same level of transparency as a globally interpretable model.
Why explainability matters
Explainability is important for many of the same reasons as interpretability. Explainable models are more transparent and reliable, which helps ensure accuracy, fairness and user trust. Understanding which features contribute most to a decision can help model developers fix inaccuracies and eliminate unwanted biases.
Explainability is also increasingly desirable as AI systems become more complex and more prevalent in the average person's life. The models that many people interact with on a day-to-day basis -- like LLM-based chatbots, or the complex recommendation algorithms behind TikTok's For You page -- are opaque and hard to interpret. But explainability can still help researchers and developers understand how these models work by showing relationships between inputs and outputs.
Regulations are also starting to require that AI systems be explainable. For example, Europe's GDPR entitles individuals to an explanation of any AI decision that significantly affects them, such as loan approvals. Explainability tools and techniques can help AI developers meet these compliance requirements by providing justifications for automated decisions that laypeople can understand.
Limitations and tradeoffs
Explainability's focus on post hoc explanations makes it easier to apply to a wide range of models, but this has a downside: A post hoc explanation might oversimplify a model's actual decision-making process, leading to potential misunderstandings of feature importance.
In addition, many machine learning models have thousands of features, and explainability tools and techniques aren't always user-friendly. As a result, the explanations themselves can be difficult to convey to nonexperts, such as end users and line-of-business teams. Understanding and describing what a feature importance score means in the real world can be challenging even for a domain expert.
Finally, like interpretability, explainability involves a tradeoff between performance and transparency. Explanations become more expensive and time-consuming to generate as a model becomes larger and more complex; applying such techniques can require large amounts of computational resources.
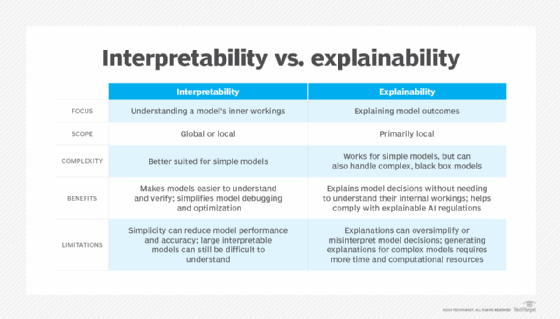
Interpretability vs. explainability: Key differences
While interpretability and explainability have the same end goal -- increasing model transparency by providing insight into how models make decisions -- the way they go about achieving that goal differs.
First, interpretability and explainability have different methodologies and scope. Interpretability focuses on how the inner workings of a model can clarify its decision-making behavior. Interpretable models are transparent in structure and can be examined either globally, to understand the model as a whole, or locally, to trace individual decisions.
In contrast, explainability isn't derived by looking at the inner workings of a model. Instead, it uses observed patterns in model outcomes to draw conclusions about model behavior. This means explainability has a more local scope, because it looks at specific scenarios after the fact rather than the entire model.
Due to these differences, interpretability and explainability are suited to different levels of model complexity. Interpretability requires deep understanding of a model's structure, making it a good fit for simpler models. Because explainability doesn't require as much insight into the model itself, it's more practical for more complex models where internal behaviors are harder to understand.
Interpretability and explainability techniques
In general, interpretability techniques aim to make models inherently understandable from the outset, whereas explainability techniques are more retroactive, focusing on post hoc explanations of model output. Choosing the right technique depends on factors such as time, cost, developer expertise, model complexity, project scope and model use case.
Examples of interpretability techniques
Interpretability techniques include the following:
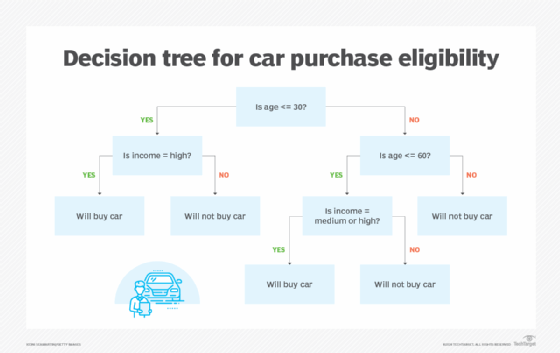
- Decision trees. Decision trees classify data in a manner similar to flow charts, splitting it into branches based on simple decision rules. Each branch represents a decision, making the model's path easy to visualize and follow, and techniques such as pruning can help simplify the tree to further improve clarity.
- Linear regression. Linear regression predicts outcomes by finding linear relationships between inputs and the target variable. This helps developers understand how each input influences the model's predictions, making it easy to understand how the model works.
- Logistic regression. Used mainly for binary classification tasks, logistic regressions are similar to linear regressions, but instead use the logistic function to estimate probabilities. Like linear regressions, logistic regression models are interpretable because developers can easily understand how an input affects the likelihood of an output.
- Generalized linear models. GLMs are an extended, more flexible version of linear regression that can account for a wider variety of response types and error distributions. This makes them useful for working with real-world data sets that are not normally distributed.
- Rule-based AI. Unlike machine learning models, rule-based AI makes decisions using only predefined if-then rule sets that are programmed into the model. Although rule-based AI is less adaptable, it is extremely interpretable; its simple decision-making process is completely transparent.
- Scalable Bayesian rule lists. Using Bayesian statistics, SBRLs generate short, interpretable if-then rule lists based on data. In this way, SBRLs capture important patterns in the data while creating a simple, interpretable model with traceable decision paths.
Examples of explainability techniques
Explainability techniques include the following:
- Local interpretable model-agnostic explanation. LIME is used to explain individual predictions of complex models. It involves creating a simple, interpretable model, called a surrogate model, that approximates the behavior of the more complex black box model around a specific data point. This can help explain the model's local decision-making through observing how changes in input affect the surrogate model's output.
- Shapley additive explanations. SHAP calculates each feature's contribution to a model's output using Shapley values, a method from cooperative game theory used to determine player contributions by considering the game outcome. SHAP uses these values to mathematically determine how much a specific model feature contributed to an outcome, making it both useful and computationally intensive.
- Partial dependence plots. PDPs visualize how changing one feature affects model outcome, while leaving all other variables constant. By plotting how outcomes change as input values change, PDPs help reveal feature importance as well as trends in overall model behavior.
- Morris sensitivity analysis. Similar to PDPs, Morris sensitivity analysis adjusts one feature at a time to observe the effect on model outcome. This helps developers identify which features are most influential on output.
- Contrastive explanation method. CEM explains classification outcomes by contrasting them against other outcomes. It does so by identifying which features are essential for the current prediction as well as which features would change the prediction if they were altered.
- Permuted feature importance. Similar to SHAP, permuted feature importance measures how much a specific feature contributed to a given outcome. It works by shuffling a feature's values and observing how this changes prediction error.
- Individual conditional expectation. Like PDPs, ICE plots visualize how a given feature affects model predictions. However, they show more detail than PDPs, displaying one line per instance instead of a plot of outcome changes. This focus on individual variation can give more nuanced insights into model decisions.
Lev Craig covers AI and machine learning as the site editor for TechTarget Editorial's Enterprise AI site. Craig graduated from Harvard University with a bachelor's degree in English and has previously written about enterprise IT, software development and cybersecurity.
Olivia Wisbey is the associate site editor for TechTarget Enterprise AI. She graduated with bachelor's degrees in English literature and political science from Colgate University, where she served as a peer writing consultant at the university's Writing and Speaking Center.






