Data preparation for machine learning still requires humans
Looking to AI to automate more of your processes? Don't overlook the labor that's still needed to prepare data for training machine learning and AI algorithms.

Data is at the core of AI and machine learning projects. Even more so than application code, data is crucial in training, testing, validating and supporting the machine learning algorithms at the heart of AI systems. Part of the reason why AI has surged again in popularity is due to the combination of almost limitless cloud computing, the availability of big data to train machine learning models, and the evolution of deep learning algorithms. The last two of those three reasons are data dependent. In fact, the more data you can feed AI algorithms, the better they perform and the more significant the machine learning results.
However, it's not enough to have a lot of data. Without good quality data, AI systems fail. The root of many machine learning project failures has little to do with the machine learning algorithms or code, or even any particular technology vendor choice. Problems almost always come back to the quality of data. In order for machine learning models to be properly trained and provide the expected accurate results, the data used needs to be clean, accurate, complete and well-labeled. Data preparation for machine learning is a crucial step in both supervised and unsupervised learning applications.
Because of this, the majority of time that companies spend on AI projects goes toward data collection, cleaning, preparation and labeling. Enterprises are finding that they need to invest more in these data prep steps than on the data science, model training and operationalization parts. This has led to a substantial growth in demand for tools and services to assist with data preparation and labeling.
The many steps of data preparation for AI
A recent report from AI research and advisory firm Cognilytica finds that over 80% of the time enterprises spend on AI projects goes toward preparing, cleaning and labeling data. Specifically, the report finds that the many steps involved in collecting, aggregating, filtering, cleaning, deduping, enhancing, selecting and labeling data far outnumber the steps on the data science, model building and deployment sides.
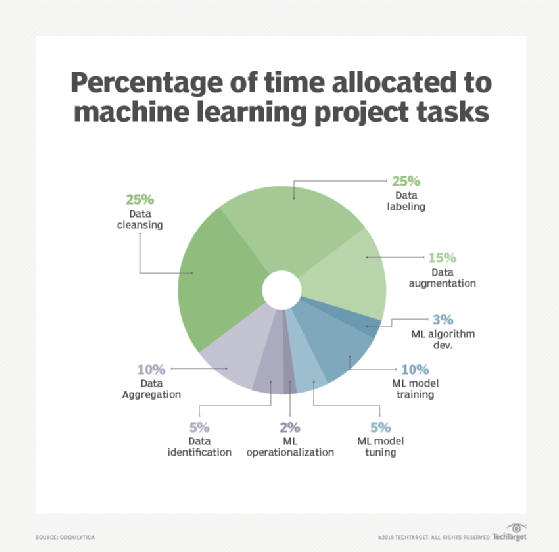
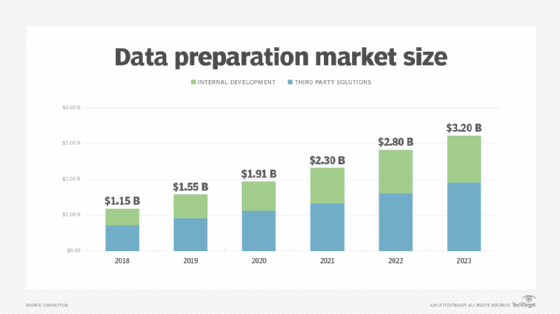
A new class of data preparation tools has emerged into the market, built to manage big data sets and optimized to address the problems of machine learning projects. According to the report, the market for AI-focused data preparation tools is currently valued at over $500 million and expected to more than double to $1.2 billion by the end of 2023.
Most enterprise data is not ready to be used by machine learning applications and requires significant effort in preparation. Tools offering data preparation for machine learning need to be able to perform a long list of tasks, including standardize formats across different data sources, remove or replace invalid and duplicate data, confirm data is accurate and up to date, help enhance and augment data as needed, reduce data noise, anonymize data, normalize data, allow for proper data sampling especially when working with large volumes of data, and allow for feature engineering and extraction.
Cognilytica's report finds that the AI-relevant data preparation tools provide iterative and interactive ways to allow people to quickly view the impact of data prep activities on big data. Some of the key features of these tools allow you to quickly spot anomalies in the data, identify and remove duplicates, resolve data conflicts, normalize data formats, establish pipelines for extracting and collating data from multiple sources, enhance data with additional features required for models, and anonymize data as might be necessary for certain applications.
In the past, enterprises relied on a category of tools known as extract, transform and load (ETL) to move data into and out of big data warehouses to facilitate reporting, analytics, business intelligence and other operations. However, in the new cloud-based, big data-oriented environment, moving data into and out of warehouses with ETL is falling out of favor. In its place, companies are looking to work with data in whatever location it currently sits. Some refer to this as "sipping from the data lake." Instead of ETL, companies are looking at tools that can draw information on demand from the data source and transform them once extracted and loaded. This is more like ELT than ETL, and many of the data preparation tools on the market, including offerings from Melissa Data, Trifacta, and Paxata, work from the perspective of assuming data is located in different formats throughout the organization.
Data labeling and AI's secret
For supervised machine learning to work, the algorithms need to be trained on data that has been labeled with whatever information the model needs. For example, image recognition models need to be trained on accurate, well-labeled data that represents what the system will recognize. If you're trying to identify cats then you need many images of cats for a cat-recognition model.
It might come as a surprise, especially to those who don't deal with machine learning models on a daily basis, just how human-intensive much of this data labeling work is. Supervised machine learning projects form the bulk of AI projects. AI projects relating to object and image recognition, autonomous vehicles, audio analysis and text and image annotation are the most common workloads for data labeling efforts. Indeed, human-powered data labeling is a necessary component for any machine learning model that needs to be trained on data that hasn't already been labeled. One of AI's little secrets is that humans are still needed for manually labeling data and performing AI quality control.
Many companies resort to using internal labor or contracting general labor pools for this labeling work. According to Cognilytica's report, companies spent over $750 million in 2018 on internal labeling efforts and this number is projected to grow to over $2 billion by the end of 2023.
In the past few years, a new class of vendor has emerged to provide third-party labeling. Vendors such as Figure Eight, iMerit, and CloudFactory provide dedicated data labeling labor pools that are able to offload much of this work to remote workers who operate at better scales and cost of operation. The report cites that the market for third-party data labeling services was $150 million in 2018, growing to over $1 billion by 2023.
Yet, despite the use of third-party data labeling services, companies using those third-party offerings must still spend twice as much supporting those efforts than the cost of the actual data labor work. Part of the reason why it's so expensive to handle this portion of the machine learning project is there is just no way to entirely take the human out of the loop. This is where AI is running into the chicken and egg problem. In order to train machine learning algorithms you need lots of clean, accurate, well-labeled data, but to get that data you need humans to do the hard work to clean and manually label that data. Obviously if machines could do it, you wouldn't need the humans. But to get machines to be able to do it, you need the humans.
How AI can play a bigger role in data prep
Fortunately, as AI models become more intelligent and better trained, they can actually help in some of these activities related to data preparation for machine learning. In fact, the report highlights the fact that most of the tools on the market are adding AI to their systems to assist with data preparation activities, handle repetitive tasks autonomously and provide assistance to guide humans on prep activities. Increasingly, data prep and data labeling providers are applying machine learning to their own labeling efforts to provide some autonomous quality control and, to some extent, autonomous labeling.
Some of these companies use AI to help detect anomalies, patterns, matches and other aspects of data cleansing. Other companies use inferencing to identify data types and things that don't match the structure of a data column. This helps spot potential data quality or formatting issues and provides recommendations on how to clean the data. The report claims that all the leading data prep tools on the market will have AI at their core by 2021.
Similarly, Cognilytica's report sees data labeling efforts as increasingly being augmented by AI and machine learning capabilities. The use of pre-trained models, transfer learning and AI-enhanced labeling tools will reduce the amount of human labor needed to build new models. That in turn will accelerate AI efforts and further increase efficiency on the more human-intensive side of AI.
Since data is at the heart of AI and machine learning, the need for companies to have good, clean, well-labeled data will only increase. At some point in the near future, there will be pre-trained neural networks available for organizations to use. Until then, companies need to invest in software that performs data preparation for machine learning.





