What is a transformer model?
A transformer model is a neural network architecture that can automatically transform one type of input into another type of output. The term was coined in the 2017 Google paper titled "Attention Is All You Need." This research paper examined how the eight scientists who wrote it found a way to train a neural network for translating English to French with more accuracy in a quarter of the training time of other neural networks.
Transformer models are particularly adept at determining context and meaning by establishing relationships in sequential data, such as a series of spoken or written words or the relations between chemical structures. The mathematical techniques employed in transformer models are referred to as attention or self-attention and enable the models to determine ways in which data points relate to one another.
The notion of attention has been around since the 1990s as a processing technique. However, in 2017, the team at Google suggested they could use attention to directly encode the meaning of words and the structure of a given language. This was revolutionary because it replaced what previously required an additional encoding step using a dedicated neural network. It also unlocked a way to virtually model any type of information, paving the way for the extraordinary breakthroughs that have emerged.
The technique proved more generalizable than the authors realized, and transformers have found use in generating text, images and robot instructions. They can also model relationships between different modes of data, called multimodal artificial intelligence (AI), for transforming natural language instructions into images or robot instructions. The broad use of transformer models and the trends of generalizing transformers have led to their designation as foundation models, providing general pretrained models that organizations can adapt and tweak for specific purposes much faster and easier than building a model from scratch.
This article is part of
What is GenAI? Generative AI explained
Virtually all applications that use natural language processing (NLP) now use transformers under the hood because they perform better than prior approaches. Researchers have also discovered that transformer models can learn to work with chemical structures, predict protein folding and analyze medical data at scale. Transformers are crucial in all large language model (LLM) applications, including OpenAI's ChatGPT, Google Search, OpenAI's Dall-E and Microsoft Copilot.
What can transformer models do?
Transformers are gradually usurping previously popular types of deep learning neural network architectures in many applications, including recurrent neural networks (RNNs) and convolutional neural networks (CNNs). RNNs were ideal for processing streams of data, such as speech, sentences and code. But they could only process shorter strings at a time. Newer techniques, such as long short-term memory, were RNN approaches that could support longer strings but were still limited and slow. In contrast, transformers can process longer series and each word or token in parallel, helping them scale more efficiently.
CNNs are ideal for processing data, such as analyzing multiple regions of a photo in parallel for similarities in features, such as lines, shapes and textures. These networks are optimized for comparing nearby areas. Transformer models, such as Vision Transformer introduced in 2021, in contrast, seem to do a better job of comparing regions that might be far away from one another and have been proven in computer vision applications. Transformers also do a better job of working with unlabeled data.
Transformers can learn to efficiently represent the meaning of a text by analyzing larger bodies of unlabeled data. This lets researchers scale transformers to support hundreds of billions and even trillions of features. In practice, the pretrained models created with unlabeled data only serve as a starting point for further refinement for a specific task with labeled data. However, this is acceptable because the secondary step requires less expertise and processing power.
Transformer models have found acceptance in a wide range of direct AI use cases, including the following:
- NLP tasks. Transformers can ingest, understand, translate and replicate human languages in near-real time.
- Financial and security tasks. Transformers can process and analyze extensive financial or network traffic data to detect and report anomalies, helping prevent fraud and security violations.
- Idea analysis. Transformer models can ingest and process extensive information and produce suitable summaries or outlines -- think CliffsNotes for books, collections and even entire topics.
- Simulated AI entities. Software programs, such as chatbots, can combine language, analytics and summation features designed to interact with people, answer questions and assist with problem-solving. Google Gemini is one example.
- Pharmaceutical analysis and design. Transformer models can assist researchers with chemical and DNA analysis, accelerating the design and refinement of powerful new drugs.
- Media creation. Transformer models can produce generative images, videos and music based on the user's text prompt. OpenAI's Dall-E is one example.
- Programming tasks. Transformer models can complete code segments, analyze and optimize code, and run extensive testing.
Transformer model architecture
A transformer architecture consists of an encoder and decoder that work together. The attention mechanism lets transformers encode the meaning of words based on the estimated importance of other words or tokens. This enables transformers to process all words or tokens in parallel for faster performance, helping drive the growth of increasingly bigger LLMs.
Using the attention mechanism, the encoder block transforms each word or token into vectors further weighted by other words. For example, in the following two sentences, the meaning of it is weighted differently, owing to the change of the word filled to emptied:
- He poured the pitcher into the cup and filled it.
- He poured the pitcher into the cup and emptied it.
The attention mechanism connects it to the cup being filled in the first sentence and to the pitcher being emptied in the second sentence.
The decoder essentially reverses the process in the target domain. The original use case was translating English to French, but the same mechanism could translate short English questions and instructions into longer answers. Conversely, it could translate a longer article into a more concise summary.
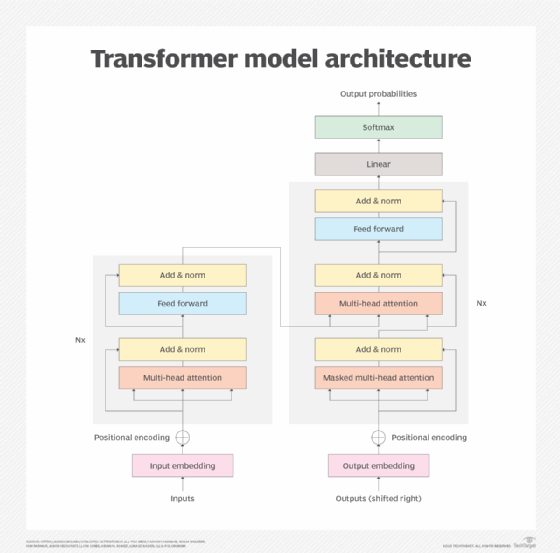
There are six principal elements to a typical transformer model, and a model can include multiple instances of some elements:
- Input. Input embedding converts a raw data stream into a data set the model can process. For example, spoken or written words can be converted into data. The data resulting from this conversion captures features of the input, such as the semantics and syntax from words. The data produced in this conversion is a feature of the model training process. The rest of the model can process the resulting data.
- Positional encoding. Transformer models don't include a native sense of input positioning or order, so positional encoding fills this data gap and derives information about the position of data being input. For example, transformers don't know the order of words in a sentence, so positional encoding tells the model the position of words within the sentence. This brings additional insight, enabling the model to evaluate how words are ordered.
- Attention mechanism. The core of the transformer model is the attention mechanism, which is usually an advanced multihead self-attention mechanism. This mechanism enables the model to process and determine or monitor the importance of each data element. Multihead means several iterations of the mechanism operate in parallel, enabling the model to examine different relationships between the data and determine the most likely or sensible relationship.
- Feed-forward neural networks. A nonlinear neural network then transforms the representations established by the attention mechanism. These neural networks enable the transformer model to learn complex patterns and nuances in the data, which are more detailed and accurate than the attention mechanism alone.
- Normalization techniques. Data normalization enables the model to standardize or place guardrails around the data values it processes. This protects the model from extreme data values or unusual variations that can distort the transformation process and result in poor output. Additional normalization techniques, such as residual connections, are used to handle the problem of vanishing gradients where the model is difficult to train.
- Output. The output mechanism is responsible for generating the final output for the model. This typically includes linear transformation, along with a softmax function that converts vector numbers into a probability distribution. For example, an English-to-French translator selects and orders the words in French. While the output is typically created word by word, advanced transformers can produce entire sentences or paragraphs at the same time. Text can be displayed directly, or speech can be produced through additional text-to-speech conversion.
Transformer model training
There are two key phases involved in training a transformer. In the first phase, a transformer processes a large body of unlabeled data to learn the structure of the language or a phenomenon, such as protein folding, and how nearby elements seem to affect each other. This is a costly and energy-intensive aspect of the process. It can take millions of dollars to train some of the largest models.
Once the model is trained, it's helpful to fine-tune it for a particular task. A technology company might want to tune a chatbot to respond to different customer service and technical support queries with varying levels of detail depending on the user's knowledge. A law firm might adjust a model for analyzing contracts. A development team might tune the model to its extensive library of code and unique coding conventions.
The fine-tuning process requires significantly less expertise and processing power. Proponents of transformers argue that the large expense involved with training larger general-purpose models, or foundation models, can pay off because it saves time and money in customizing the model for so many different use cases.
The number of features in a model is sometimes used as a proxy for its performance instead of more salient metrics. However, the number of features -- or size of the model -- doesn't directly correlate with performance or utility. It's possible to train a model with more parameters yet achieve outputs that are less precise than the same model trained with fewer parameters. In actual practice, models trained with large volumes of data are often helpful for broader capabilities where less precision is acceptable.
Transformer model implementations
Transformer implementations are improving in terms of size and support for new use cases or different domains, such as medicine, science or business apps. The following are some of the most promising transformer implementations:
- Google's Bidirectional Encoder Representations from Transformers (BERT) was one of the first LLMs based on transformers. There are myriad different BERT versions, including BERT base, BERT large, RoBERTa, DistilBERT, TinyBERT, ALBERT, ELECTRA and FinBERT.
- OpenAI's GPT followed suit and underwent several iterations, including GPT-2, GPT-3, GPT-3.5, GPT-4 and GPT-4o. GPT-5 is currently in development.
- Meta's Llama achieves comparable performance with models 10 times its size. Llama 3.3, which was released in December 2024, should dwarf those capabilities.
- Google's Pathways Language Model (PaLM) generalizes and performs tasks across multiple domains, including text, images and robotic controls. PaLM 2 is available, along with the popular Gemini models.
- Dall-E 3 creates images from a short text description.
- The University of Florida and Nvidia's Gatortron analyzes unstructured data from medical records. It uses Nvidia's Megatron transformer-based language modeling framework across a DGX SuperPOD with over 1,000 A100 graphics processing units.
- Google DeepMind's AlphaFold 3 describes how proteins fold and can predict interactions between proteins and other molecules.
- AstraZeneca and Nvidia's MegaMolBART generates new small-molecule drug candidates based on chemical structure data.
AI is being widely used in the medical field to predict the risk of certain diseases. Learn how UCLA researchers developed AI models for three-dimensional imaging analysis.





