What is semantic search?
Semantic search is a data searching technique that uses natural language processing (NLP) and machine learning algorithms to improve the accuracy of search results by considering the searcher's intent and the contextual meaning of the terms used in their query. Semantic search is widely used in web search engines, such as Google, but it also has applications in areas such as content management systems, internal corporate chatbots and e-commerce platforms.
Traditional keyword-based search methodologies, known as lexical search, focus only on finding exact matches for terms used in the searcher's query. While this technique is useful for surfacing direct matches, it can't account for linguistic nuances such as homonyms, synonyms and context-dependent meanings.
Semantic search, in contrast, aims to identify the searcher's underlying objective and find contextually relevant results, even if they don't contain the exact words used in the original query. In other words, semantic search algorithms try to understand what users actually mean, not just what they say.
To produce these results, semantic search algorithms draw on external sources such as knowledge graph databases, specialized lists of terms called ontologies and subject-specific text collections. Sometimes, they also incorporate contextual information about the user, such as their location and search history.
This article is part of
What is GenAI? Generative AI explained
How does semantic search work?
Semantic search algorithms have complex architectures that integrate several branches of machine learning, including NLP, question-answering and knowledge graphs. Although the process of returning search results only takes a fraction of a second, it still involves multiple steps behind the scenes.
When a semantic search system receives a search query from a user, it starts by breaking down the query and identifying relationships between words. NLP is used to tokenize and break down the query, and a process called part-of-speech tagging is used to mark each token as a part of speech. Dependency parsing is also used here to analyze grammatical relationships. The algorithm might also transform the tokens into word embeddings, where words with similar meanings are mapped close together as a vector representation.
As an example, if a user googles "tallest mountain in the United States," the phrase is broken down into tokens and tagged as certain parts of speech; for example, the adjective tallest is recognized as a modifier to the noun mountain. The algorithm then categorizes known entities, like names, locations and quantities. In this case, the algorithm would categorize United States as a geographical entity.
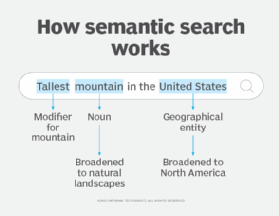
Next, the algorithm begins the semantic analysis stage, where words with multiple meanings, ideas and themes are identified, and the search is broadened to include synonyms and related terms. In the above example, the search algorithm might recognize the term mountain as a concept associated with natural landscapes and broaden the search to include North America as a related term to United States.
The system then uses semantic indexing to access presorted data on these terms. Web search engines like Google rely on indexed documents and data entries, ranking content based on relevance and authority. These engines prioritize content that isn't only semantically relevant, such as a list of the heights of various mountains, but also the most authoritative. For example, this could include websites associated with government agencies, reputable universities and established news outlets.
Additional steps in the process might also include adapting to new user data and the use of knowledge graphs as noted below:
- Semantic search algorithms might also be trained on examples of user queries to adapt based on new user data. An algorithm, for example, might use data on what links a user clicked and how much time they spent on the results page.
- Knowledge graphs can also be used to ensure an algorithm can quickly return relevant information for search queries. For example, Google's proprietary Knowledge Graph contains billions of data records about people, locations and other known entities.
So, to arrive at its answer, the search algorithm parses the user's query, understanding mountain as a type of geographical feature and tallest as a request to compare heights within the region of the United States. The algorithm then consults the Knowledge Graph and identifies Denali as the relevant entity, subsequently telling the user that Denali is the tallest mountain in the U.S. The results might also include additional information the algorithm identifies as relevant, such as Denali's former name, Mount McKinley, and the fact that it's also the highest peak in North America, not just the U.S.
Pros and cons of semantic search
As noted above, a semantic search approach offers several benefits over its simpler keyword-based predecessors, but it also comes with several limitations and challenges. The advantages of semantic search include the following:
- Better relevance and accuracy. The most important benefit of semantic search algorithms is their ability to improve the quality of search results. The ability to infer a searcher's intended meaning and context is especially useful for queries containing ambiguous language or that have different implications based on location or time. For example, with a semantic search algorithm, the query local restaurants would yield results in the user's current town.
- Flexibility and adaptability. Semantic search algorithms are dynamic, adjusting in response to new data and user interactions over time. This flexibility enables the algorithm to better reflect emerging trends and changes in language usage, as well as users' preferences. For example, a semantic search algorithm can learn to recognize a new slang term and associate it with older synonyms.
- Improved user experience. Because semantic search algorithms can understand the underlying meaning of a user's question, rather than relying only on the exact words typed, they facilitate simpler, more natural interactions with search engines. For example, if a user types in the natural language query "what time is the NFL game tonight," the search algorithm could provide an answer that considers the current date, the football season schedule and the user's time zone.
- Efficient information retrieval. Using semantic analysis with databases such as knowledge graphs is significantly faster than traditional keyword search methods, particularly when combined with predictive analytics and pattern-matching machine learning algorithms. This benefit is important for search engines like Google, which need to sort through an unimaginably vast amount of internet content to provide results.
Disadvantages of semantic search include the following:
- Complexity. While semantic search algorithms' complex architectures give them an advantage over lexical search algorithms, these architectures are also more difficult to plan, build and maintain. They require ongoing updates and algorithm tuning to remain effective, which demands machine learning skills and tooling that might be beyond the reach of smaller organizations and individual researchers.
- Computational load. Semantic search algorithms' size and complexity also mean they require a great deal of computational resources to function, including processing power and extensive memory. Moreover, these compute and memory requirements scale with the amount of data being analyzed. Acquiring, operating and monitoring this compute infrastructure can be highly costly -- not to mention energy-intensive, which raises environmental sustainability concerns.
- Data privacy. Part of what makes semantic search algorithms useful is their ability to understand the specific context in which a user is making their search. But this involves tracking and analyzing user data, such as location, internet browsing behavior and search history. In addition to raising obvious individual information privacy concerns, these practices could lead to regulatory compliance issues in regions with strong data protection laws, such as the European Union's General Data Protection Regulation.
- Algorithmic bias. Like any machine learning model, semantic search algorithms reflect the biases found in their training data. For example, if a semantic search algorithm's training data mainly reflects the experiences of a majority group, it might not accurately represent the diverse realities of minority populations. This can lead to misunderstandings of cultural context and skewed outcomes. Strategies to mitigate algorithmic bias include regular algorithmic audits and constructing diverse training data sets.
Semantic search vs. keyword search
Keyword search is a data searching technique that focuses on matching user queries with exact words or phrases. Although it doesn't work in the same way, a keyword search is like putting quotation marks around a word or phrase in a modern Google search -- as the quotation marks tell Google to match the exact term or phrase written, as opposed to adding meaning or intent.
While keyword searches focus on finding exact words and phrases to match queries, semantic searches focus on improving search accuracy by understanding the search query and the intent behind it. Semantic searches apply NLP and machine learning algorithms to factors like the terms used in a query, previous searches and geographic location. This is a more effective method than keyword-based searches.
Keyword searches are relatively simple, precise and faster compared to semantic searches. However, they can fail to recognize similar terms and word variants. Keyword searches are ideal for finding exact matches and when precision searches are preferred, while semantic searches are ideal for more ambiguous, tangentially relevant and intent-driven searches.
Semantic search vs. contextual search
Contextual searches expand on traditional keyword searches by also accounting for different user contexts, like location and past searches. Similar to the idea behind semantic searches, contextual searches focus on understanding the meaning and intent behind a user's query. Where semantic search uses NLP and machine learning to understand user intent, contextual search uses different available contextual details. These details could include location, search history, device type and time. This helps to make search results more relevant to the user when compared to keyword searches.
Examples of semantic search
Semantic search examples include the following:
- Google Search. Google uses semantic search algorithms to better understand the content and intent behind user queries.
- Amazon. Amazon uses semantic search to understand search queries and show users more relevant products.
- Spotify. Spotify uses semantic search to understand user intent behind music and podcast searches.
- YouTube. YouTube uses semantic search to show and suggest relevant videos to users based on their search preferences and search history.
- Zillow. Zillow uses semantic search to show users more relevant housing opportunities based on related property searches and preferences.
Can semantic search help businesses?
Semantic search is essential to modern search engines, like Google, to help provide users with more relevant and accurate search results. However, the process can be applied to systems other than search engines. For example, it can be applied to business directories, chatbots, product discovery and recommendation systems, retrieving data from medical systems and consumer or business-to-business product catalogs.
Providing optimal search experiences helps improve the user experience by boosting the visibility of more relevant items.
Semantic search is a big part of how Google Search works. Learn more about how Google algorithms work.






