What is neural radiance field (NeRF)?

Neural radiance fields (NeRFs) use deep learning to turn 2D images of objects or scenes into detailed 3D representations by encoding the entire scene into an artificial neural network. The model then predicts the light and color intensity, or radiance, at any point in the 2D representations of a 3D space in order to enable new views of the scene -- a process known as novel view synthesis.
The process is analogous to how holograms can encode different perspectives, which are unlocked by shining a laser from different directions. In the case of NeRFs, instead of shining a light, an app sends a query indicating the desired viewing position and viewport size, and the neural network enables the rendering of the color and density of each pixel in the resulting image.
NeRFs show incredible promise in representing 3D data more efficiently than other techniques and could unlock new ways to generate highly realistic 3D objects automatically. Used with other techniques, NeRFs have the potential for massively compressing 3D representations of the world from gigabytes to tens of megabytes. Time magazine called a NeRF implementation from the Silicon Valley chipmaker Nvidia one of the top inventions of 2022. Alexander Keller, director of research at Nvidia, told Time that NeRFs "could ultimately be as important to 3D graphics as digital cameras have been to modern photography."

Applications of neural radiance fields
Google has already started using NeRFs to translate street map imagery into immersive views in Google Maps. Engineering software company Bentley Systems has also used NeRFs as part of its iTwin Capture tool to analyze and generate high-quality 3D representations of objects using a phone camera.
This article is part of
What is GenAI? Generative AI explained
Down the road, NeRFs could complement other techniques for representing 3D objects in the metaverse, augmented reality (AR) and digital twins more efficiently, accurately and realistically. Game studios are exploring how NeRFs can enhance videos.
One big plus of neural radiance fields is that they operate on light fields that characterize shapes, textures and material effects directly -- the way different materials like cloth or metal look in light, for example. In contrast, other 3D processing techniques start with shapes and then add on textures and material effects using secondary processes.
Other use cases include the following:
- Architectural models. NeRFs are used to improve representations of existing or proposed buildings and rooms.
- E-commerce. Companies use this technique to improve the ability to place new items like furniture, countertop textures and appliances in an image, giving consumers a better understanding of the finished upgrade or what a product will look like in their home.
- Sports. Potential applications include using NeRFs to let viewers see a game from any angle and distance in replays and to capture players movements in 3D to enable more precise analysis.
- VR and AR. Still in early stages, NeRFs could be used to create more realistic virtual reality (VR) and AR by enabling higher-quality renderings of generative AI objects on top of the real world, in the case of AR, or in a synthetically generated world, in the case of VR. This could reduce ergonomic problems that result from the difference in how our eyes perceive focal depth and stereoscopic rendering using existing two-screen displays.
- Robotics and autonomous systems. NeRFs' ability to capture real-world environments and adapt them to changes, such as mimicking the effects of snow, rain or darkness, will enable autonomous vehicles and other robots to navigate more precisely. Also, developers could better represent novel conditions and edge cases -- e.g., a zebra crossing the road -- in their training of autonomous systems.
- Scientific research. NeRFs' ability to capture and represent the light and color of real-world materials has many applications in scientific research, including the development of new optical technologies, better climate modeling and more accurate crime and security forensics.
Novel view synthesis
NeRFs represent an important step in the computer vision field known as novel view synthesis. The fundamental idea in novel view synthesis is to find better ways to capture a few views of something that can then guide the generation of simulated views from different perspectives. These techniques can also support new ways to generate 3D content that consider objects in 3D or even 4D (space plus time) rather than existing approaches that focus on 2D perspectives. For example, researchers are making promising progress with Gaussian splatting, another novel view synthesis technique, to achieve similar results.
Evolution of NeRF applications
Early applications. Early NeRFs were incredibly slow and required all of the pictures to be taken using the same camera in the same lighting conditions. First-generation NeRFs described by Google and University of California, Berkeley, researchers in 2020 took two or three days to train and required several minutes to facilitate the generation of each view. The early NeRFs focused on individual objects, such as a drum set, plants or Lego toys.
Ongoing innovation. In 2022, Nvidia pioneered a variant called Instant NeRFs that could capture fine detail in a scene in about 30 seconds and then enable the production of different views in about 15 milliseconds, significantly speeding up NeRF training and rendering times. Google researchers also reported new techniques for NeRF in the Wild, a system that can create NeRFs from photos taken by various cameras in different lighting conditions and with temporary objects in the scene. This also paved the way for using NeRFs to generate content variations based on simulated lighting conditions or time-of-day differences.
Emerging NeRF applications. Today, most NeRF applications render individual objects or scenes from different perspectives rather than combining objects or scenes. For example, the first Google Maps implementation used NeRF technology to create a short movie simulating a helicopter flying around a building. This eliminated the challenges of computing the NeRF on different devices and rendering multiple buildings. However, researchers are exploring ways to extend NeRFs to generate high-quality geospatial data as well. This would make it easier to render large scenes. NeRFs could eventually also provide a better way of storing and rendering other types of imagery, such as MRI and ultrasound scans.
Learn more: How do neural radiance fields work?
The term neural radiance field describes the different elements in the technique. It is neural in the sense that it uses a multilayer perceptron, an older neural network architecture, to represent the image. Radiance refers to the fact that this neural network models the brightness and color of rays of light from different perspectives. Field is a mathematical term describing a model for transforming various inputs into outputs using a particular structure.
NeRFs work differently from other deep learning techniques in that a series of images is used to train a single fully connected neural network that can only be used to generate new views of that one object. In comparison, deep learning starts by using labeled data to train the neural network, which could provide appropriate responses for similar types of data.
The actual operation of the neural network uses as an input the 3D physical location and 2D direction (left-right and up-down) that the simulated camera is pointing (a 3D viewing direction) to output a color and density value of points in 3D space. This represents how rays of light bounce off objects at that location from that view in space.
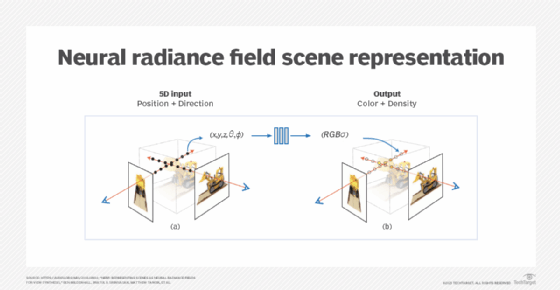
Training neural radiance fields
NeRFs are trained from images of an object or scene captured from different points of view. Here is the process in detail:
- The training process starts with a collection of images of a single object or scene taken from different perspectives, ideally from the same camera. In the very first step, a computational photography algorithm calculates the location and direction of the camera for each photo in the collection of photos.
- The information from the pictures and the location is then used to train the neural network. The difference between pixels in these images and the expected results is used to tune the neural network weights. The process is repeated 200,000 times or so, and the network converges on a decent NeRF. The early versions took days, but, as noted, recent Nvidia optimizations enable the whole thing to happen in parallel in tens of seconds.
- There is one more step NeRF developers are still trying to understand. When researchers first started experimenting with NeRFs, the images looked like smooth, blurry blobs that lacked the rich texture of natural objects, so they added a bit of digital noise to the rays to enhance the ability of the NeRF to capture finer textures. This early noise consisted of relatively simple cosine and sine waves, while later versions refined this approach using Fourier transforms to achieve better results. Adjusting this level of noise helps tune in the desired resolution. Too little, and the scene looks smooth and washed out; too much, and it looks pixelated. While most researchers stuck with Fourier transforms, Nvidia took it one step further with a new encoding technique called multi-resolution hash encoding that it cites as a critical factor for producing superior results.
Make your own NeRF
Download the NeRF code to run on your Windows or Linux system here.
The Luma AI app lets you create a NeRF on an iPhone.
What are the limitations and challenges of neural radiance fields?
In the early days, NeRFs required a lot of compute power, needed a lot of pictures and were not easy to train. Today, the compute and training are less of an issue, but NeRFs still require a lot of pictures. Other key NeRF challenges include speed, editability and composability:
- Time-intensive, but getting less so. On the speed front, training a NeRF requires hundreds of thousands of rounds of training. Early versions took several days on a single GPU. However, Nvidia has demonstrated a way to overcome this challenge through more efficient parallelization and optimization, which can generate a new NeRF in tens of seconds and render new views in tens of milliseconds.
- Challenging to edit, but getting easier. The editability challenge is related to the fact that NeRFs represent the 3D scene as a set of weights and connections that exist within a neural network. This is much less intuitive to edit than other kinds of 3D formats, such as 3D meshes representing the surface of objects or voxels -- i.e., 3D pixels -- representing their 3D structure. Google's work on NeRF in the Wild suggested ways to change the color and lighting, and even to remove unwanted objects that appear in some of the images. For example, the technique can remove buses and tourists from pictures of the Brandenburg Gate in Berlin taken by multiple people.
- Composability remains a hurdle. The composability challenge relates to the fact that researchers have not found an easy way to combine multiple NeRFs to compose larger scenes. This could make it hard in certain use cases, such as rendering simulated factory layouts composed of NeRFs of individual pieces of equipment or creating virtual worlds that combine NeRFs of various buildings.






