What is a generative adversarial network (GAN)?
A generative adversarial network (GAN) is a machine learning (ML) model in which two neural networks compete by using deep learning methods to become more accurate in their predictions. GANs typically run unsupervised and use a cooperative zero-sum game framework to learn.
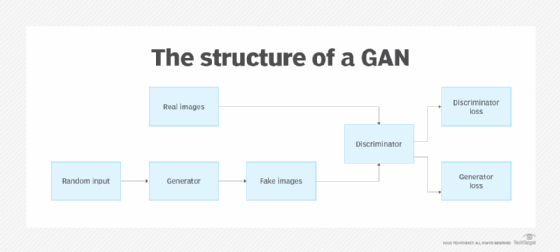
The two neural networks that make up a GAN are referred to as the generator and the discriminator. The generator is a convolutional neural network, and the discriminator is a deconvolutional neural network. The goal of the generator is to artificially manufacture outputs that could easily be mistaken for real data. The goal of the discriminator is to identify which of the outputs it receives have been artificially created.
Essentially, generative models create their own training data. While the generator is trained to produce false data, the discriminator network is taught to distinguish between the generator's manufactured data and true examples. If the discriminator rapidly recognizes the fake data that the generator produces -- such as an image that isn't a human face -- the generator suffers a penalty. As the feedback loop between the adversarial networks continues, the generator begins to produce higher-quality and more believable output, and the discriminator becomes better at flagging data that has been artificially created. For instance, a generative adversarial network can be trained to create realistic-looking images of human faces that don't belong to any real person.
How GANs work
GANs are typically divided into the following parts:
- Generative. This describes how data is generated in terms of a probabilistic model.
- Adversarial. A model is trained in an adversarial setting.
- Networks. Deep neural networks can be used as artificial intelligence (AI) algorithms for training purposes.
The first steps in establishing a GAN are to identify the desired end output and gather an initial training data set based on those parameters. This data is then randomized and input into the generator until the model acquires basic accuracy in producing outputs.
This article is part of
What is GenAI? Generative AI explained
Next, the generated samples or images are fed into the discriminator along with actual data points from the original concept. After the generator and discriminator models have processed the data, optimization with backpropagation starts. The discriminator filters through the information and returns a probability between 0 and 1 to represent each image's authenticity -- 1 correlates with real images, and 0 correlates with fake. Model developers manually check these values for success, and the process is repeated until the desired outcome is reached.
A GAN typically takes the following steps:
- The generator outputs an image after accepting random numbers.
- The discriminator receives this created image in addition to a stream of photos from the real, ground-truth data set.
- The discriminator inputs both real and fake images, and outputs probabilities -- a value between 0 and 1 -- where 1 indicates a prediction of authenticity, and 0 indicates a fake.
This creates a double feedback loop, where the discriminator is in a feedback loop with the ground truth of the images and the generator is in a feedback loop with the discriminator.
Types of GANs
GANs come in many forms and can be used for various tasks. The following are the most common GAN types:
- Vanilla GAN. This is the simplest of all GANs. Its algorithm tries to optimize the mathematical equation using stochastic gradient descent, which is a method of learning an entire data set by going through one example at a time. It consists of a generator and a discriminator. The classification and creation of generated images is done using the generator and discriminator as straightforward multilayer perceptrons. The discriminator seeks to determine the likelihood that the input belongs to a particular class, while the generator collects the distribution of the data.
- Conditional GAN. By applying class labels, this kind of GAN enables the conditioning of the network with new and specific information. As a result, during GAN training, the network receives the images with their actual labels, such as "rose," "sunflower" or "tulip," to help it learn how to distinguish between them.
- Deep convolutional GAN. This GAN uses a deep convolutional neural network for producing high-resolution image generation that can be differentiated. Convolutions are a technique for drawing out important information from the generated data. They function particularly well with images, enabling the network to quickly absorb the essential details.
- Self-attention GAN. This GAN is a variation on the deep convolutional GAN, adding residually connected self-attention modules. This attention-driven architecture can generate details using cues from all feature locations and isn't limited to spatially local points. Its discriminator can also maintain consistency between features in an image that are far apart from one another.
- CycleGAN. This is the most common GAN architecture and is generally used to learn how to transform between images of various styles. For instance, a network can be taught how to alter an image from winter to summer, or from a horse to a zebra. One of the most well-known applications of CycleGAN is FaceApp, which alters human faces into various age groups.
- StyleGAN. Researchers from Nvidia released StyleGAN in December 2018 and proposed significant improvements to the original generator architecture models. StyleGAN can produce photorealistic, high-quality photos of faces, and users can modify the model to alter the appearance of the images that are produced.
- Super-resolution GAN. With this type of GAN, a low-resolution image can be changed into a more detailed one. Super-resolution GANs increase image resolution by filling in blurry spots.
- Laplacian pyramid GAN. This GAN builds an image using several generator and discriminator networks, incorporating different levels of the Laplacian pyramid -- a linear image incorporating band-pass images spaced an octave apart -- resulting in high image quality.
Popular use cases for GANs
GANs are becoming a popular ML model for online retail sales because they can understand and re-create visual content with increasingly remarkable accuracy. They can be used for a variety of tasks, including anomaly detection, data augmentation, picture synthesis, and text-to-image and image-to-image translation.
Common use cases of GANs include the following:
- Filling in images from an outline.
- Generating a realistic image from text.
- Producing photorealistic depictions of product prototypes.
- Converting black-and-white imagery into color.
- Creating photo translations from image sketches or semantic images, which are especially useful in the healthcare industry for diagnoses.
In video production, GANs can be used to perform the following:
- Model patterns of human behavior and movement within a frame.
- Predict subsequent video frames.
- Create a deepfake.
Other use cases of GANs include text-to-speech for the generation of realistic speech sounds. Furthermore, GAN-based generative AI models can generate text for blogs, articles and product descriptions. These AI-generated texts can be used for a variety of purposes, including advertising, social media content, research and communication.
GAN examples
GANs are used to generate a wide range of data types, including images, music and text. The following are popular real-world examples of GANs:
- Generating human faces. GANs can produce accurate representations of human faces. For example, StyleGAN2 from Nvidia can produce photorealistic images of people who don't exist. These pictures are so lifelike that many people believe they're real individuals.
- Developing new fashion designs. GANs can be used to create new fashion designs that reflect existing ones. For instance, clothing retailer H&M uses GANs to create new apparel designs for its merchandise.
- Generating realistic animal images. GANs can also generate realistic images of animals. For example, BigGAN, a GAN model developed by Google researchers, can produce high-quality images of animals such as birds and dogs.
- Creating video game characters. GANs can be used to create new characters for video games. For example, Nvidia created new characters using GANs for the well-known video game Final Fantasy XV.
- Generating realistic 3D objects. GANs are also capable of producing actual 3D objects. For example, researchers at MIT have used GANs to create 3D models of chairs and other furniture that appear to have been created by people. These models can be applied to architectural visualization or video games.
The future of GAN technology
GAN technology is so rapidly advancing -- and the products of GAN applications are so effective and useful -- that it isn't only the defining factor in the future of digital imaging, but the course of generative AI technology across the board.
The dueling network aspect of the GAN model makes it an excellent method for data augmentation, which is essential in ML processes. This boosts the quantity and diversity of training sets beyond the content of existing data sets by generating variations. This, in turn, boosts the generalizability of ML products. It also provides relief to the growing industry issue of limited big data for large-scale modeling requirements.
It's likely that GANs will become a central technology in pharmaceutical research, where their capacity to generate variations of existing data configurations will become a go-to methodology for designing new drugs based on existing biochemical data. This will reduce time to market for new treatments as well as make it possible to consider and analyze far more variations in far less time.
A more peripheral prediction for the evolution of GANs is that their architectural limitations will curb their role in the evolution of video deepfakes. At present, GANs are the most advanced of the leading deepfake technologies, producing the most convincing deepfake stills of human faces, in particular. However, their volatility and limited controllability render GANs a supporting technology, rather than a primary technology, in the future development of deepfake video generation.
Both convolutional neural networks and recurrent neural networks have played a big role in the advancement of AI. Learn how CNNs and RNNs differ from each other and explore their strengths and weaknesses.






